
Solve enterprise data tasks at superhuman accuracy. Acquired by @togethercompute
Joined May 2021
- Tweets 50
- Following 42
- Followers 558
- Likes 72
1 Photos and videos

We have some big news to share today - @RefuelAI is joining @togethercompute to help accelerate the future of open source and enterprise AI! together.ai/blog/together-ai…
1
4
20
1,866
We have some big news to share today - @RefuelAI is joining @togethercompute to help accelerate the future of open source and enterprise AI! together.ai/blog/together-ai…
1
4
20
1,866
3/ By joining @togethercompute, we will bring Refuel's team, technology and mission to Together’s AI platform, and help accelerate the AI adoption journey of the next generation of developers and enterprises
1
1
340
4/ To our customers: thank you for trusting us to solve your critical data problems and helping shape the journey. And to the Refuel team: you made this possible — every late night, every launch, every hard technical choice. We're proud of what we’ve built. Onwards!
1
269
Refuel retweeted

15 May 2025
🚀 Big news: Together AI has acquired @RefuelAI!
Refuel specializes in models and tools that turn messy, unstructured data into clean, structured input—exactly what teams need to build high-quality, production-grade AI applications.
Details below 👇

2
4
28
2,773
Refuel retweeted

8 Jan 2025
Data intelligence too cheap to meter
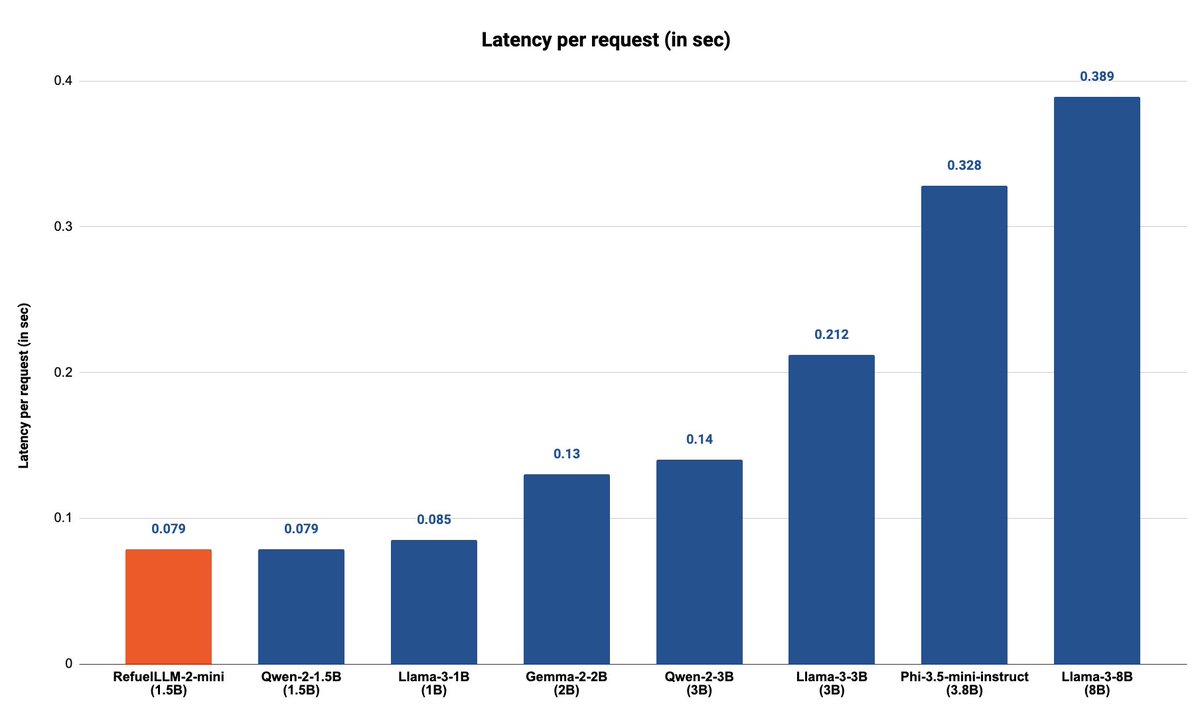
RefuelLLM-2-mini (75.02%), our latest 1.5B param SLM, outperforms all comparable models including Phi-3.5 (65.3%), Qwen2.5 (67.62%), Gemma2 (64.52%), Llama3-3B (55.8%) and Llama3-1B (39.92%) across our benchmark of data processing tasks such as labeling, enrichment and structure extraction
RefuelLLM-2-mini is a Qwen2-1.5B base model, trained on a corpus of 2750 datasets spanning tasks such as classification, reading comprehension, structured attribute extraction and entity resolution, using the same recipe as other models in the Refuel-LLM family.
It's fast!
We’re open sourcing the model weights, available on @huggingface - huggingface.co/refuelai/Qwen…
If you'd like to access models, along with fine tuning support, DM me or reach out to us: refuel.ai/get-started
Grateful to our early customers for their partnership, and the entire @RefuelAI team for their hard work 🚀

8 May 2024

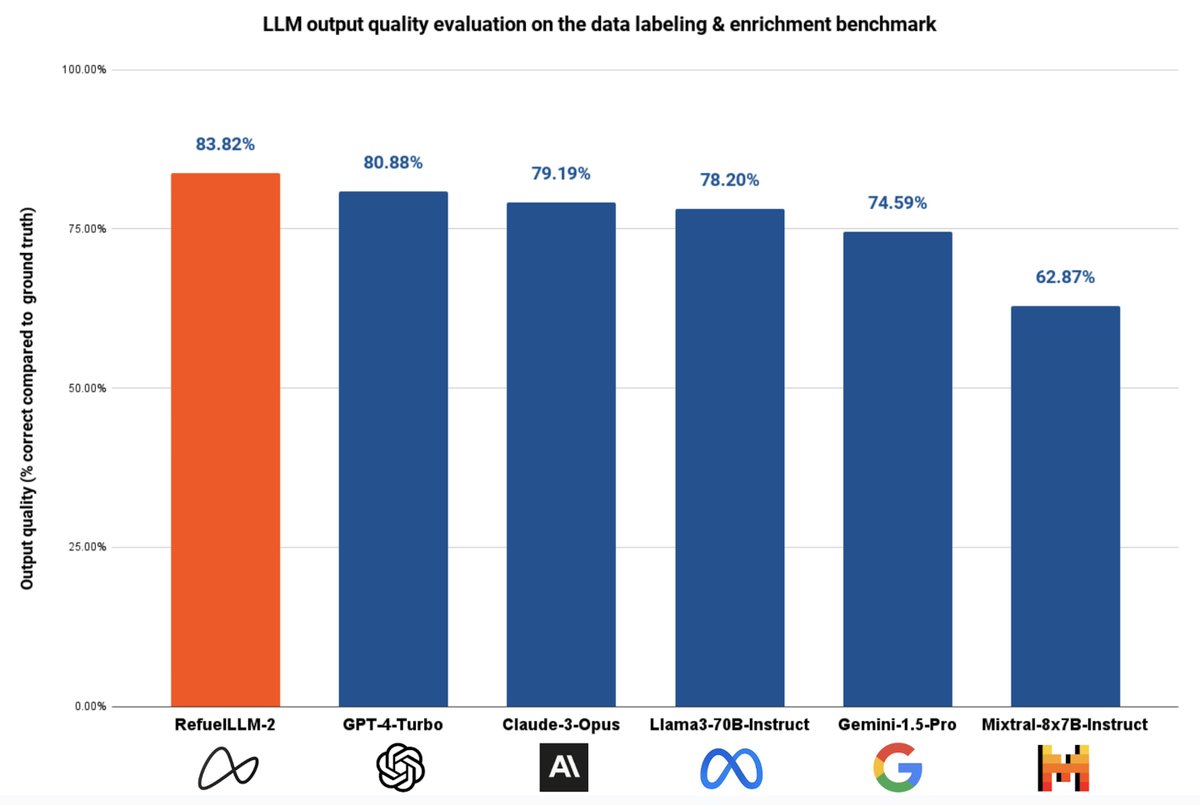
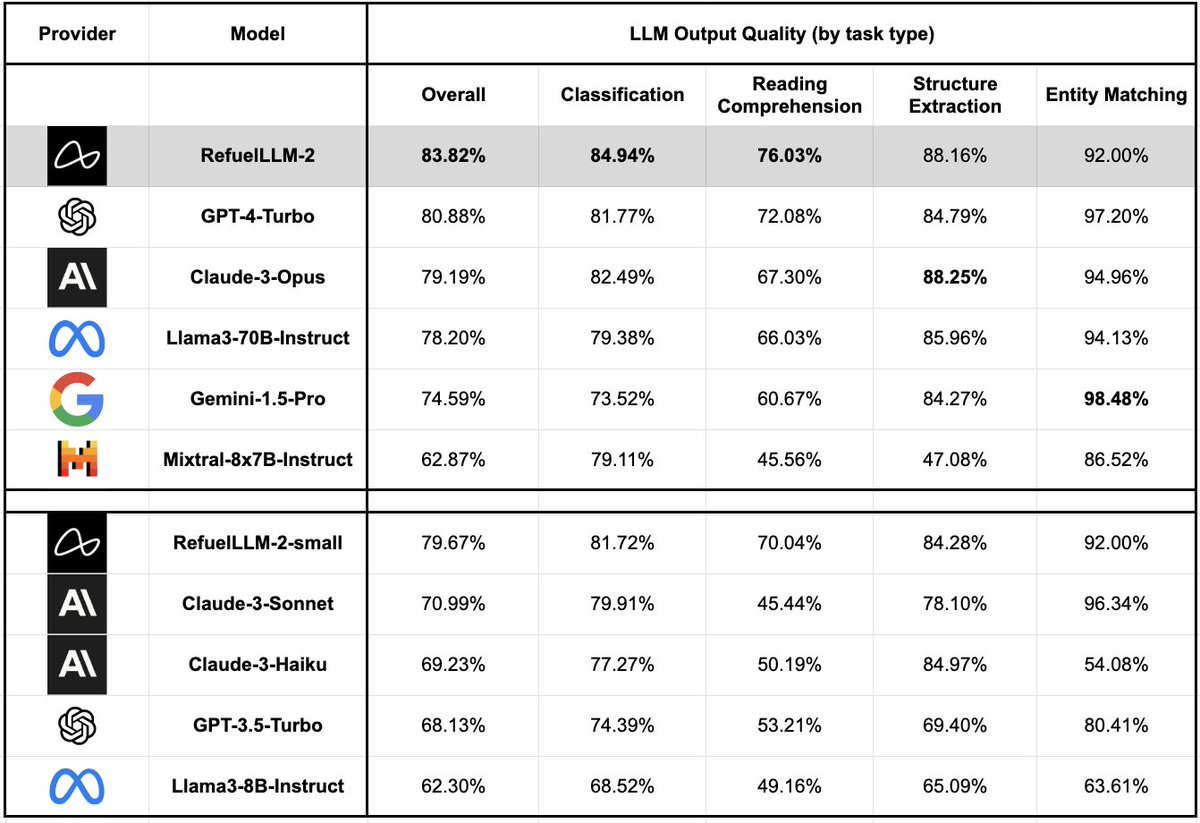
Thrilled to introduce RefuelLLM-2, our latest family of LLMs built for data labeling and enrichment tasks. RefuelLLM-2 (83.82%) outperforms GPT-4-Turbo (80.88%), Claude-3-Opus (79.19%), Llama3-70B (78.2%) and Gemini-1.5-Pro (74.59%) on a benchmark of ~30 data labeling tasks:
RefuelLLM-2-small (79.67%), aka Llama-3-Refueled, outperforms all comparable LLMs including Claude3-Sonnet (70.99%), Haiku (69.23%) and GPT-3.5-Turbo (68.13%). We’re open sourcing the model: huggingface.co/refuelai/Llam…
You can try out the models here and give us some feedback! labs.refuel.ai/playground. The code and data used for benchmarking the LLMs is available in our Autolabel library: github.com/refuel-ai/autolab…
One more thing: RefuelLLM-2 family of models output much better calibrated confidence scores - a useful lever to reject, retry or ensemble low confidence outputs.
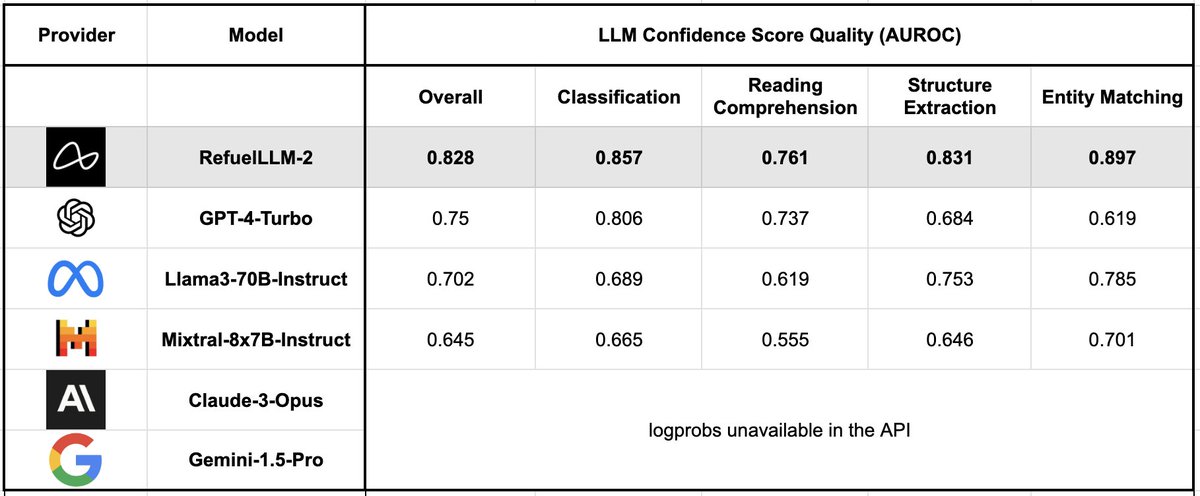
3
3
14
2,245
Refuel retweeted
12 Jun 2024
Thank you @databricks @DbrxMosaicAI for the keynote shoutout! Always great connecting with new and old friends at the @Data_AI_Summit

2
19
1,339

We're kicking off the Data AI Summit with the #MosaicX #Meetup: San Francisco Edition on Monday, June 10th. We're at the #Moscone Center South, 2nd floor, with over 1500 registrants and 39 speakers across four tracks.
It's a "slightly" packed agenda with:
✅ Discussion panels on #Hardware, Build & Risks, Data Panel, and #VC Panel with a special session on #OLMo
✅ #Research track on importance of high quality #data, common challenges in #RAG development, #diffusion models, and more
✅ A use cases track on composable #CDP, building models, #multimodal, #agents, and more
✅ In the building LLMs track, we discuss the challenges, tools/techniques to build them, fast #LLM inference, and building #GenAI apps.
While we are fully packed, if you are already registered for #DataAISummit, we will have a waitlist at the door.
We have speakers from @databricks @DbrxMosaicAI @LaminiAI @Oracle @VoltronData @Replit @AiSquared_ @robusthq @gretel_ai @superannotate @EssenceVenture @AmplifyPartners @llama_index @QuotientAI @ActionIQinc @RefuelAI @OrbyAI @yousearchengine @NumbersStnAI @lancedb @huggingface
mosaicx.events/events/june-1…

7
14
52
37,270
Refuel retweeted
9 May 2024
We're trending on @huggingface!
Check out: huggingface.co/refuelai/Llam…
Try out the model here: labs.refuel.ai/playground

8 May 2024
Thrilled to introduce RefuelLLM-2, our latest family of LLMs built for data labeling and enrichment tasks. RefuelLLM-2 (83.82%) outperforms GPT-4-Turbo (80.88%), Claude-3-Opus (79.19%), Llama3-70B (78.2%) and Gemini-1.5-Pro (74.59%) on a benchmark of ~30 data labeling tasks:
RefuelLLM-2-small (79.67%), aka Llama-3-Refueled, outperforms all comparable LLMs including Claude3-Sonnet (70.99%), Haiku (69.23%) and GPT-3.5-Turbo (68.13%). We’re open sourcing the model: huggingface.co/refuelai/Llam…
You can try out the models here and give us some feedback! labs.refuel.ai/playground. The code and data used for benchmarking the LLMs is available in our Autolabel library: github.com/refuel-ai/autolab…
One more thing: RefuelLLM-2 family of models output much better calibrated confidence scores - a useful lever to reject, retry or ensemble low confidence outputs.
1
5
20
14,274
We're thrilled to introduce RefuelLLM-2. Outperforms every single LLM available (GPT-4-Turbo, Claude Opus, Llama 3-70B, Gemini 1.5 Pro) on our benchmark of data labeling tasks.
* Launch: refuel.ai/blog-posts/announc…
* Playground: labs.refuel.ai/playground
8 May 2024
Thrilled to introduce RefuelLLM-2, our latest family of LLMs built for data labeling and enrichment tasks. RefuelLLM-2 (83.82%) outperforms GPT-4-Turbo (80.88%), Claude-3-Opus (79.19%), Llama3-70B (78.2%) and Gemini-1.5-Pro (74.59%) on a benchmark of ~30 data labeling tasks:
RefuelLLM-2-small (79.67%), aka Llama-3-Refueled, outperforms all comparable LLMs including Claude3-Sonnet (70.99%), Haiku (69.23%) and GPT-3.5-Turbo (68.13%). We’re open sourcing the model: huggingface.co/refuelai/Llam…
You can try out the models here and give us some feedback! labs.refuel.ai/playground. The code and data used for benchmarking the LLMs is available in our Autolabel library: github.com/refuel-ai/autolab…
One more thing: RefuelLLM-2 family of models output much better calibrated confidence scores - a useful lever to reject, retry or ensemble low confidence outputs.
3
9
35
19,804
Refuel retweeted
8 May 2024
Thrilled to introduce RefuelLLM-2, our latest family of LLMs built for data labeling and enrichment tasks. RefuelLLM-2 (83.82%) outperforms GPT-4-Turbo (80.88%), Claude-3-Opus (79.19%), Llama3-70B (78.2%) and Gemini-1.5-Pro (74.59%) on a benchmark of ~30 data labeling tasks:
RefuelLLM-2-small (79.67%), aka Llama-3-Refueled, outperforms all comparable LLMs including Claude3-Sonnet (70.99%), Haiku (69.23%) and GPT-3.5-Turbo (68.13%). We’re open sourcing the model: huggingface.co/refuelai/Llam…
You can try out the models here and give us some feedback! labs.refuel.ai/playground. The code and data used for benchmarking the LLMs is available in our Autolabel library: github.com/refuel-ai/autolab…
One more thing: RefuelLLM-2 family of models output much better calibrated confidence scores - a useful lever to reject, retry or ensemble low confidence outputs.
15
63
308
100,821
Refuel retweeted
30 Apr 2024
Better data = Better AI. In this episode of @software_daily I dive into why this is true, what makes it hard and how @RefuelAI is solving this at scale. Shoutout to @seanfalconer for hosting! 👇🚀
30 Apr 2024

Nihit Desai of @RefuelAI joins the show with @seanfalconer to talk about the platform, and how to manage data in the current AI era.
Listen here:
softwareengineeringdaily.com…
@nihit_desai
1
8
14
2,488
Thank you @cerebral_valley for the feature!
1
9
2,076
15 Feb 2024

🧠 What if humans could write instructions once and have machines do all of their data cleaning, labeling, and enriching for them?
@refuelAI founder @rish_bhargava says this is the way
And he joins us this week to tell us how LLMs make it possible:
apple.co/48cO7Ni
7
1,312