
Engineering @ NVIDIA Dynamo. LLM inference systems - Disagg serving, Scheduling, Tiered KV, KVBM. ex-AWS|Trainium. @GeorgiaTech. Opinions my own. sengopal.me
Joined May 2009
- Tweets 1,232
- Following 145
- Followers 241
- Likes 188
57 Photos and videos
















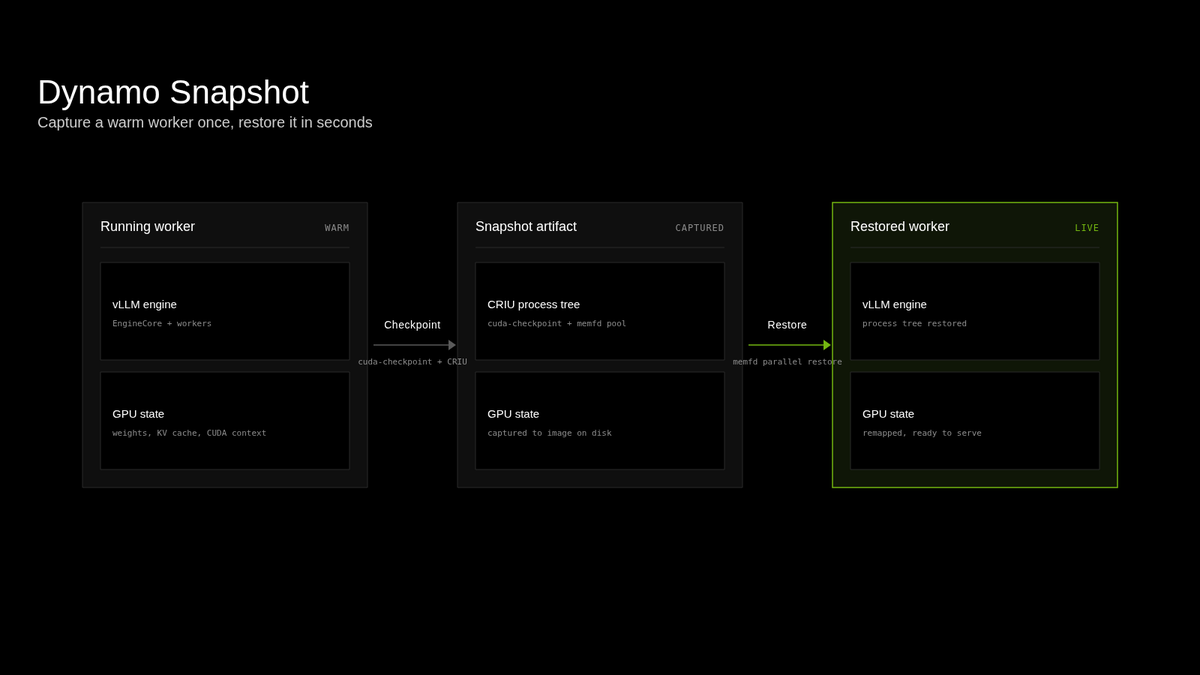
Introducing Dynamo Snapshot, our approach for fast startup for inference workloads on Kubernetes, which reduces startup time from minutes to under 5 seconds.
In production inference deployments demand fluctuates over time. Cold-starting inference workloads can take minutes, leaving idle GPUs that generate no tokens and serve no requests.
Snapshot leverages GMS to enable concurrent weight restoration over a high-speed interconnect, while using Linux native AIO and parallel memfd restoration to accelerate CRIU restore performance.
23
53
362
61,856

May 26
vLLM's PegaFlow and Dynamo's KVBM are converging on the same bet: external KV cache as a standalone Rust service over a connector boundary. The interesting design choice between them - does the inference engine own the prefix index, or does the storage layer?
1
25
May 26
8
May 22
And this will work with Nvidia Dynamo seamlessly 😊
May 21

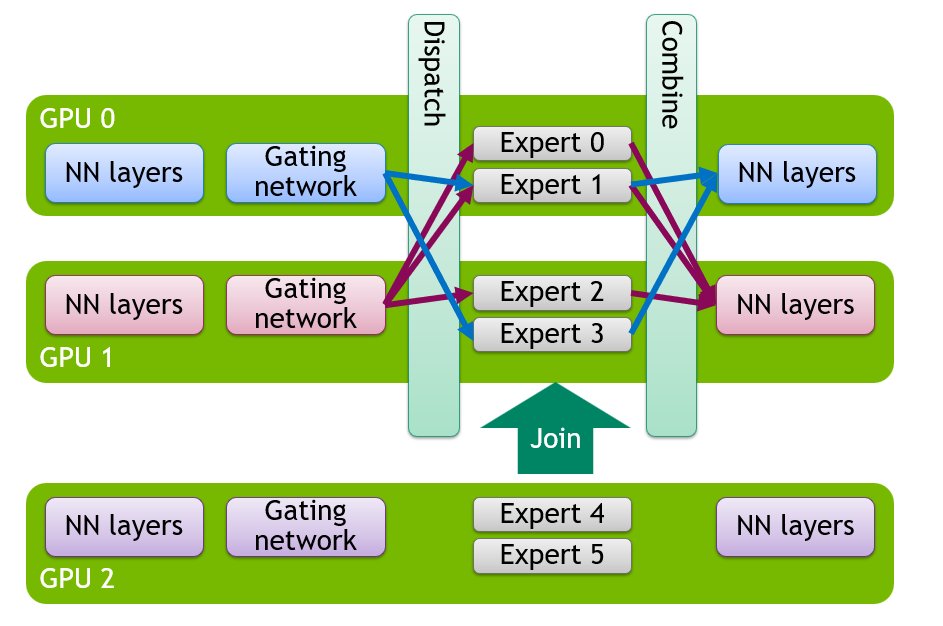
A vLLM MoE deployment's DP/EP topology used to be locked in at launch — scaling or swapping config meant a full restart, in-flight traffic dropped. Elastic Expert Parallelism changes that. One API call resizes a live deployment:
curl -X POST localhost:8000/scale_elastic_ep \
-d '{"new_data_parallel_size": 16}'
Under the hood: standby comm groups span the target topology, EPLB redistributes experts across the new EP group, and weights are transferred directly between GPUs over NVIDIA NVLink/RDMA. The same runtime reconfiguration path is what fault-tolerant serving needs: evict failed ranks, redistribute their experts, bring replacements back, no restart.
Thanks to @NVIDIAAI, Sky Computing, @anyscalecompute, @RedHat_AI, and the community.
📖 vllm.ai/blog/2026-05-14-elas…
32
May 19
You still need to do this within the original world size 😊 so arbitrary grow/shrink might still be pending. But a great API for Fault tolerance 😉
May 17

TIL that NCCL has ncclCommGrow/Shrink?? How did it take me so long to find this??
23
Senthilkumar Gopal retweeted

May 18
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
136
973
7,416
575,504
May 19
I have a variation of this for analysis of papers. To write the intuition gained, thinking behind why this method works vs. does not work for <problem>, evidence to support and the exact citation from the paper to support the decision.

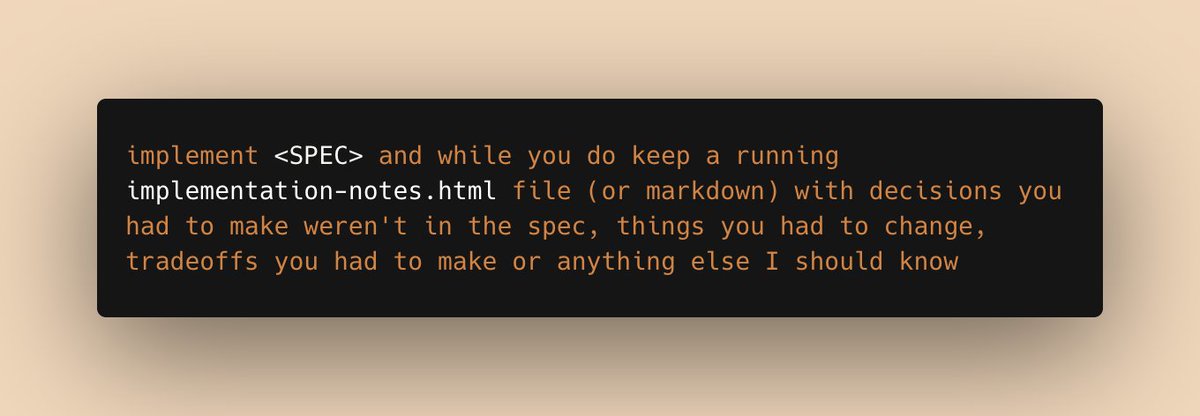
a prompt I've been using a lot recently:
implement <SPEC> and while you do, keep a running implementation-notes.html file (or markdown) with decisions you had to make weren't in the spec, things you had to change, tradeoffs you had to make or anything else I should know
1
22
May 19
When empirical experiments are run, I ask CC to review the decisions made and track evidence supported analysis and give itself a reward and cite this particular technique for future analysis where relevant 😊
7
Senthilkumar Gopal retweeted

May 14
Interestingly, long context attention actually enables more opportunities to stream weights into HBM, decreasing the memory requirements for weights stored in HBM at any given time, which pairs well with managing the larger KV cache.
Check out our work on this:
1
1
8
763
May 11
Was waiting for something like this to show up. It's high time 😊

New in Claude Code: agent view.
One list of all your sessions, available today as a research preview.
8
Senthilkumar Gopal retweeted
May 9
Another reason to use Dynamo 😊
BTW the blog cited is a follow up to this blog: docs.nvidia.com/dynamo/dev/d…
2
6
410
Does this translate the same way for the unsloth Lora and qlora recipes as well?
May 6

We collaborated with NVIDIA to teach you how we made LLM training ~25% faster! 🚀
Learn how 3 optimizations help your home GPU train models faster:
1. Packed-sequence metadata caching
2. Double-buffered checkpoint reloads
3. Faster MoE routing
Guide: unsloth.ai/blog/nvidia-colla…

1
29
♥️ that Dynamo is the fulcrum around which Agents run their whole session
. Incredible!
May 5

Check out this awesome article by some incredible NVIDIA peers about workload differences for agents!
developer.nvidia.com/blog/bu…
1
14
Let's go!!
Apr 30
Some awesome work by the SGLang and NVIDIA teams to drive GB200 performance forwards!
1
24
Senthilkumar Gopal retweeted

Apr 28
This feels like confusing a serving-runtime problem for a chip-startup opportunity.
Agents do change inference patterns: loops, tool calls, branching, long context, KV reuse, burstiness. But most of that is an inference systems problem: scheduling, routing, KV-cache management, etc. Think Dynamo.
By the time a new chip co tapes out builds a compiler stack wins cloud distribution, NVIDIA/AMD will likely have baked the obvious hardware-level optimizations into existing platforms.
Apr 27

Inference Chips for Agent Workflows
@sdianahu
Most AI chips are designed for "prompt in, response out." Agents don't work that way. They loop, branch, and hold context across dozens of steps, and current GPUs hit 30–40% utilization as a result.
That gap is where purpose-built silicon wins.
14
10
99
27,817
Apr 27
An excellent walkthrough of context determination and compaction across agents.

10
Senthilkumar Gopal retweeted

What a night for the NVIDIA Dynamo community 📸
From OSS commits to production-scale inference, NVIDIA Dynamo is quickly becoming part of the modern AI stack enhancing stability, reliability, and speed.
One thing was clear: faster inference is the new frontier—and Dynamo is the skill to master. Inference is hard (really hard), and the game is shifting.
And the conversations didn’t stop there. An incredible turnout stayed on to connect, share ideas, and celebrate the growing inference ecosystem.
Huge thank you to our speakers from @alibaba_cloud, @baseten, @haoailab, @intel, @Pinterest, @PrimeIntellect, and to everyone who joined us and continues to push Dynamo forward.
📗 nvda.ws/4mhXaW1




5
14
71
8,682

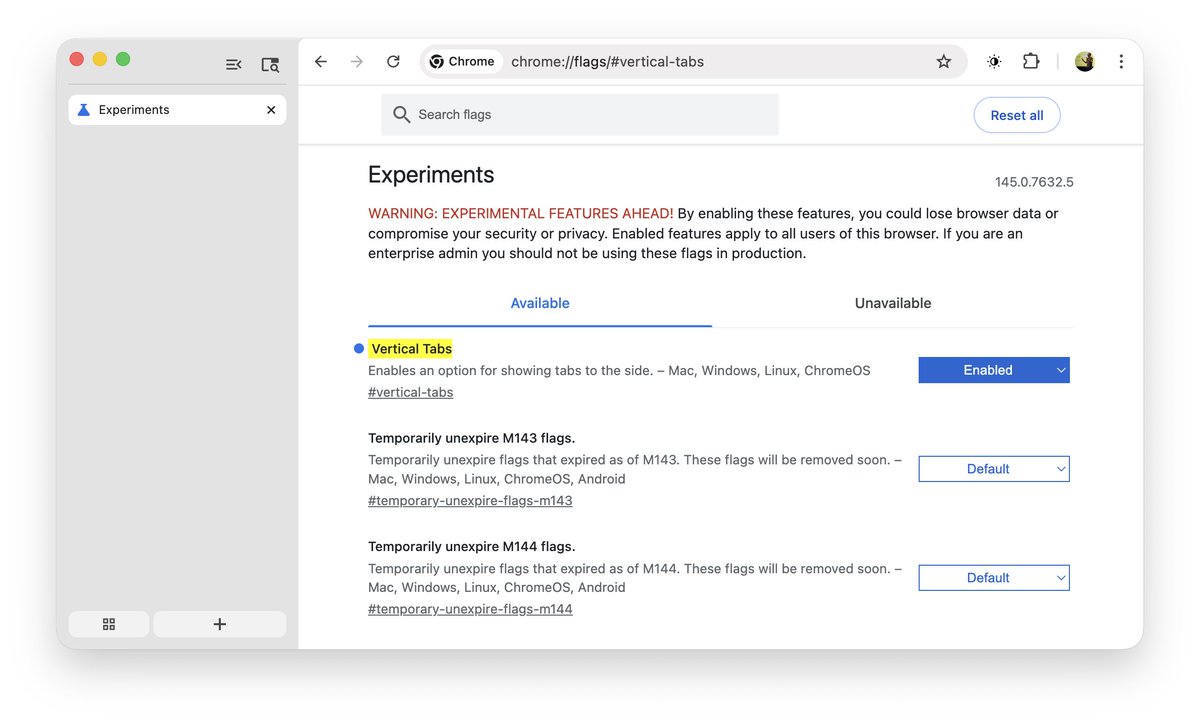
🌟 Vertical Tabs are available behind a flag in Chrome 145 (current beta)
1. Go to `chrome://flags/#vertical-tabs`
2. Set it to enabled
3. Relaunch Chrome
4. Right click the tabbar and choose “Move Tabs To The Side”
Attached are before and after screenshots.

ALT Chrome 145 with the flag enabled and showing the context menu to move the tabs to the side
ALT Chrome 145 with the tabs shown to the side (vertical tabs)
75
122
1,874
219,626
Senthilkumar Gopal retweeted

Apr 5
Day 92/365 of GPU Programming
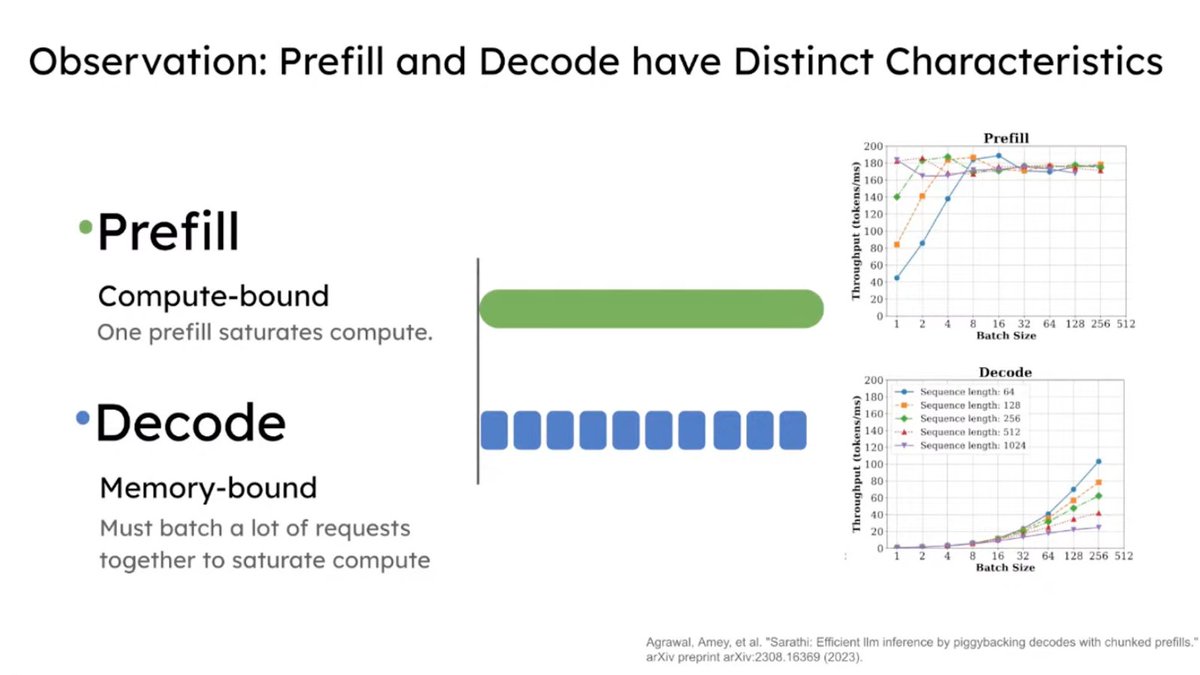
Taking a closer look at disaggregated LLM inference today, which I've been wanting to survey more after listening to the Dean <> Daly discussion at GTC.
The best resource I found on the topic was this great talk by @Junda_Chen_ on the past, present and future of prefill decode disaggregation.
In the lecture, Junda goes through Nvidia's dynamo, the intrinsic tradeoff spectrum between throughput & latency, TTFT, TPOT, the "goodput" metric, distinct characteristics between prefill vs decode, chunking P&D, the problem of interference, pipeline parallelism, resource & parallelism coupling, disaggregation and DistServe.


Apr 4

Day 91/365 of GPU Programming
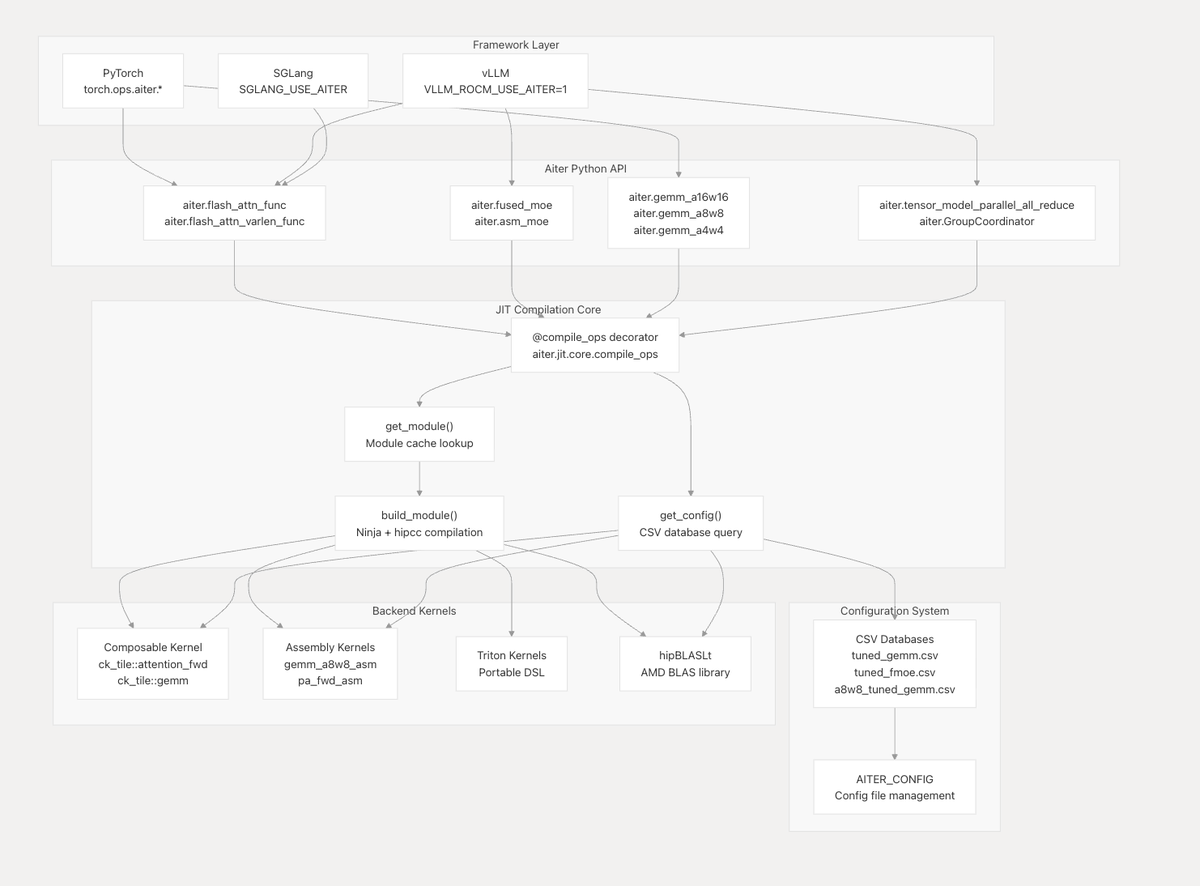
Looking more closely into AMD’s AITER and ATOM today to get a better sense of the full scope of the Kimi K2.5 1T FP4/DeepSeek-R1-0528 FP4 MTP challenges and the differences between phases 1 & 2 like TTFT and TPOT scoring (mainly out of curiosity).
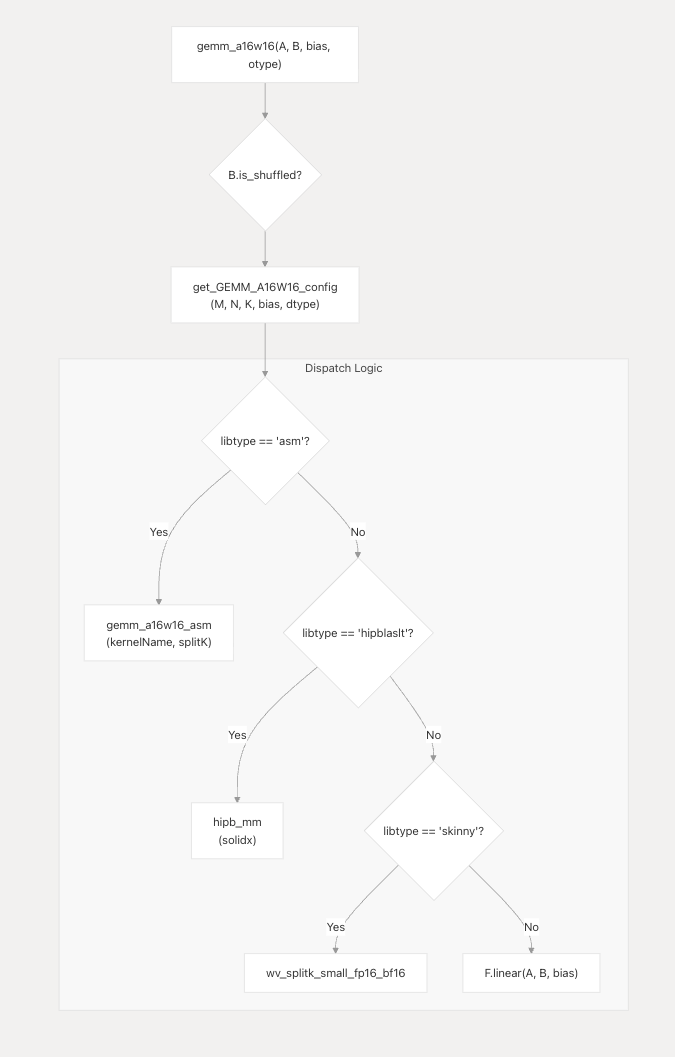
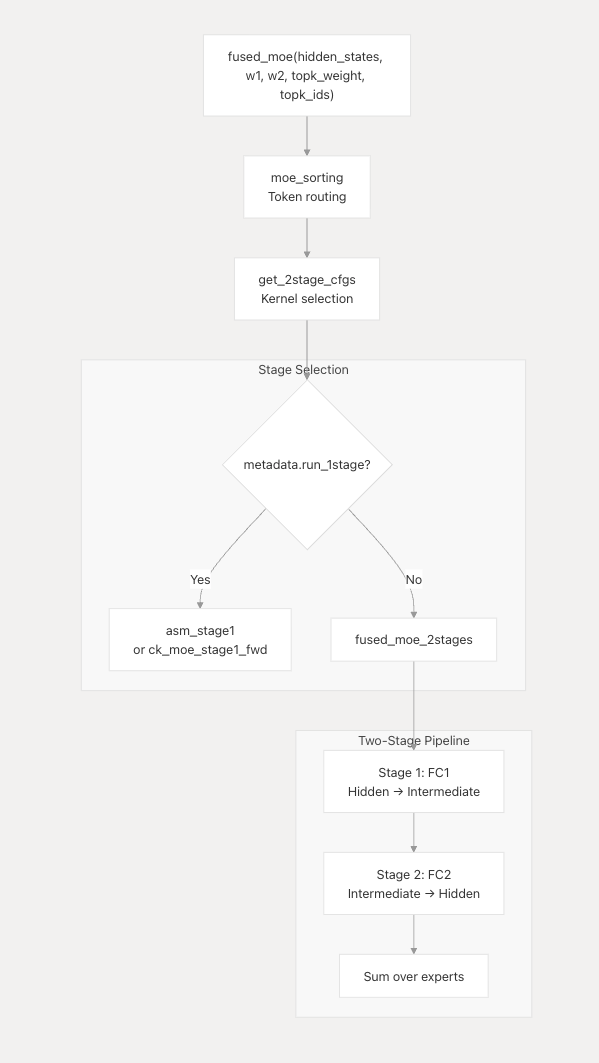
AITER being AMD’s centralized operator library. Basically a unified place for high performance ops with kernels underneath coming from things like Triton, Composable Kernel (CK) and asm. It spans inference but also training kernels and even fused GEMM communication primitives.
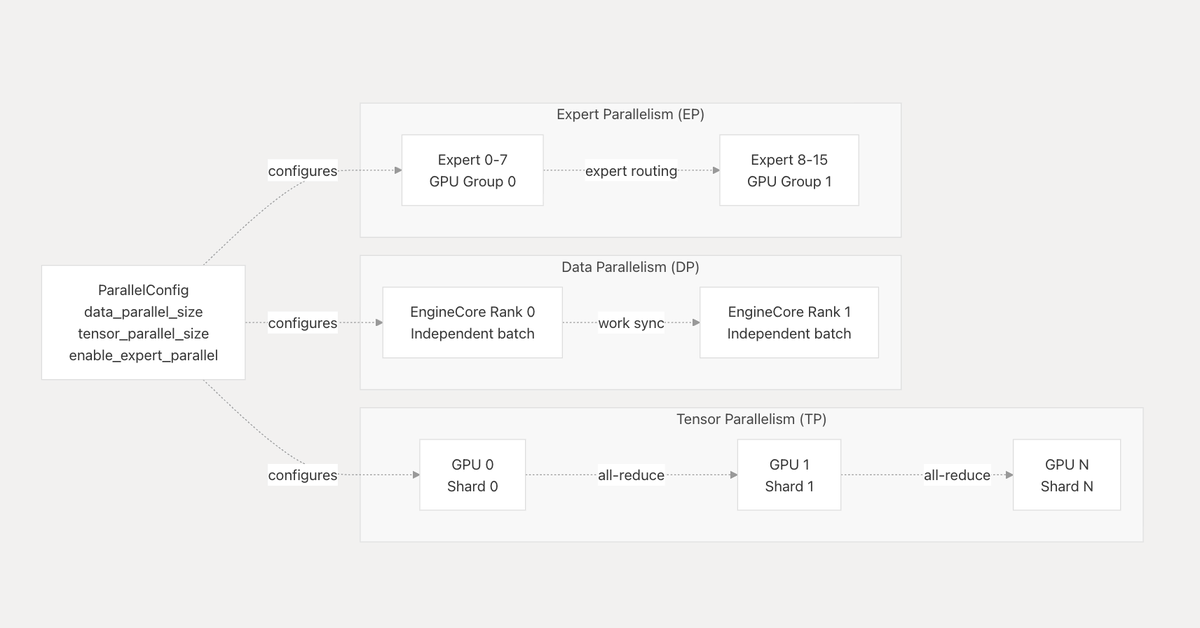
And ATOM sitting a level above that. As far as I understand it so far, ATOM's a lite vLLM inspired LLM inference engine / model backend built around AITER kernels with AMD specific execution choices like AITER native attention/MoE/sampling paths, continuous batching style scheduling, graph captured decode and support for TP/DP/EP. I find the separation interesting because it creates this natural stack boundary between operator/kernel optimization in AITER and model level execution serving integration in ATOM. AMD also seems to be using ATOM as an incubation layer for faster inference iteration while still integrating with and creating ways to upstream pieces into vLLM/SGLang rather than keeping everything permanently out of tree.
Also have to say I really like using DeepWiki (thank you @silasalberti @swyx @ScottWu46) for use cases like this. @karpathy was right. When documentation is sparse or out of date, being able to converse with a repo is a much cleaner way of extracting information than trying to piece things together based on potentially stale states of development.
5
12
126
42,323