
Joined August 2023
- Tweets 122
- Following 136
- Followers 100
- Likes 128
1 Photos and videos

Pinned Tweet

16 Jan 2024
🇮🇳Releasing resources for Multilingual Search in 11 Indian languages!
1⃣INDIC-MARCO (Translated version of MSMARCO in 11 Indian Languages): huggingface.co/datasets/saif…
2⃣Indic-ColBERT (11 Multilingual ColBERT Models): huggingface.co/saifulhaq9/in…
Paper: arxiv.org/abs/2312.09508
3
4
24
6,858
Saiful Haq retweeted

Jun 3
dspy.GEPA used in pretraining data curation in the new Microsoft AI effort :-)

Excited to see the use of GEPA-optimized LLM judges for data filtering in MAI-Thinking-1 model's pre-training pipeline!

10
25
258
18,977
Saiful Haq retweeted
Apr 1
overwhelming evidence for late interaction / multi-vector models yet again :-)
> even after finetuning, single-vector models lag far behind multi-vector embeddings, which achieve significant performance gains and exhibit greater robustness to catastrophic forgetting.
Apr 1

On Strengths and Limitations of Single-Vector Embeddings
Microsoft shows that dimensionality alone cannot explain poor retrieval performance of single-vector embeddings, identifying domain shift and the "drowning in documents" paradox as key factors.
📝 arxiv.org/abs/2603.29519
4
7
90
8,521
Saiful Haq retweeted
Mar 24
The “grep-is-all-you-need” nonsense arguments arise from the fact that too many people think neural search means single-vector IR, which do in fact suck. But we’ve known that since 2019.
Quoting @aaxsh18, CEO of Mixedbread:
> late interaction cant stop winning
Mar 24

For Agentic tasks, Oracle-level performance is the maximum performance a system can achieve, assuming it is able to retrieve all relevant documents perfectly, every time.
We're proud to show that Mixedbread Search approaches the Oracle on multiple knowledge intensive benchmarks.
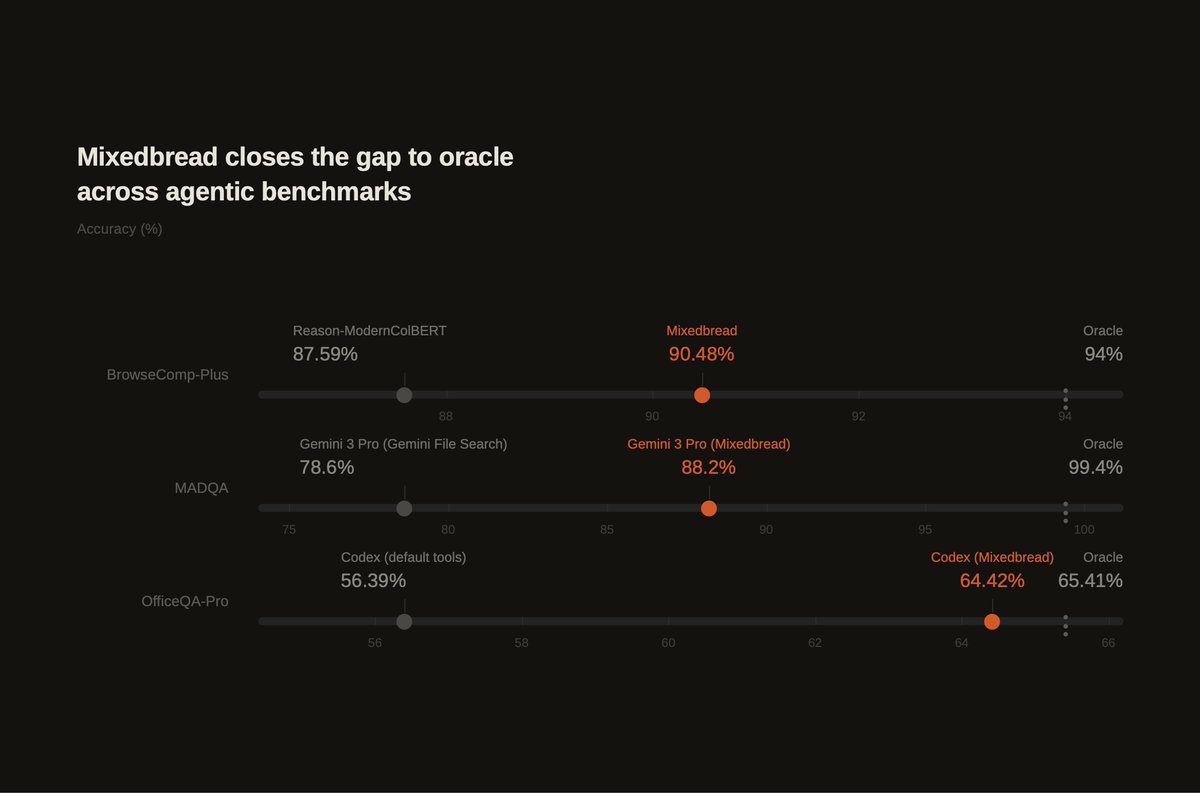
9
15
227
24,758
Saiful Haq retweeted

Jan 21
Hackathon alert: The Financial needle in theHaystack. Join us! luma.com/3dk8wzx3 via @LumaHQ
#bangalore #financeAI #documents #startups
1
2
152
Saiful Haq retweeted

Jan 20
Makes me wonder if Omar sees the rest of the world with this much clarity or just ML/AI
let’s hear some hot political takes haha
Jan 20

almost everything omar and his team build looks early when it’s released, and then quietly becomes foundational later.
seen the same with colbert and dspy, was not a hit immediately after release but over time the industry caught up, understood the framing, and they became widely adopted
i feel it will be similar with rlms too. the industry will circle back in few months and adopt the idea of rlms as a standard way to manage computation, context, and recursion in long-running systems.
3
1
21
8,771
Saiful Haq retweeted
Jan 7
Of course not. In fact, my lab is simultaneously building RLMs as the next paradigm for LLMs *and* developing the next paradigm for retrieval (stay tuned!).
Retrieval will not go anywhere: if you have a large corpus with, say, billions of tokens over which you issue many queries, you necessarily need to build some index data structures that enable fast sub-linear access.
RLMs may internally choose to build such an index when it proves to be an effective tool, but fundamentally RLMs are about long one-off context. You wouldn’t typically put an RLM over a million documents and expect that to be the optimal system design.
(Thank you for the question @jayitabhattac11 !)

Can RLMs eliminate RAG or am I hallucinating 🤔
@a1zhang @lateinteraction
21
17
209
16,475
Saiful Haq retweeted

Jan 5
For those interested in making OSS contributions to the RLM repo, I've added a bunch of random thoughts and TODOs of what to add in a *messy* Markdown file on the GH repo.
Feel free to tackle any of them, or any other things you think are meaningful. I'll be pretty active here or on the repo. Once I finish some other related work, I might open up a Discord channel or something for people who want to make longer standing contributions to the repo / discuss the direction of where to take it. Cheers!
github.com/alexzhang13/rlm/b…
19
30
292
17,349
Saiful Haq retweeted
Jan 2
IMO, RLMs are as “language model”-y as modern “LLMs” or Reasoning Models are truly “statistical models of language”.
All three are a bit of a stretch BUT in the same way.
Pedantically, all three are language processing systems, eg recursive/reasoning language processing system.
1
20
1,477

Check out our text leaderboard at yupp.ai/leaderboard/text and our SVG leaderboard at yupp.ai/leaderboard/svg!
1
7
843
13 Dec 2025
Awesome!
11 Dec 2025

while everyone’s reading about the gpt-5.2 release, i’m still training gpt-oss-20b on a dataset generated with gpt-oss-120b!
1
2
319
Saiful Haq retweeted
10 Dec 2025
> You’ll implement ColBERT to understand multi-vector search [and] apply ColPali for patch-level image retrieval.
So happy to see the great folks at @DeepLearningAI @AndrewYNg host a course on late interaction (ColBERT, ColPali et al) after their short course on DSPy :D
10 Dec 2025

🚀 New short course with @qdrant_engine: Multi-vector Image Retrieval.
Taught by @LukawskiKacper, Senior Developer Advocate at Qdrant, the course shows how multi-vector techniques outperform single-vector methods by matching text tokens to image patches directly.
You’ll implement ColBERT to understand multi-vector search, apply ColPali for patch-level image retrieval, reduce memory with quantization and pooling, and use MUVERA to enable fast HNSW search.
The course concludes with a full multi-modal RAG pipeline built on ColPali and MUVERA.
Learn more and enroll now: hubs.la/Q03XCQZ10
3
8
113
9,626
Saiful Haq retweeted

10 Dec 2025
Please consider applying to the program. Over two years, my research skills, perspective on research have all been broadened and sharpened. This is an exceptional group, in the way they groom you, and allow you a room for exploring wild ideas. Pls reach out if you have questions!
9 Dec 2025

Thrilled to note that we are keeping the tradition of the awesome AI residency program alive in a new avatar: pre-doc researcher program at GDM-Blr -- with some amazing work done by our recent predocs including @gautham_ga_ @pranamyapk @puranjay1412 @sahilgo6801 @swaroopnath6
If you want to join this program, please apply here: google.com/about/careers/app…
1
6
418
Saiful Haq retweeted
27 Nov 2025

27 Nov 2025

Hot take: RL from "numeric" rewards is just convenience / our laziness -- and it's not the right paradigm for LLMs.
Tokens IN, Tokens out FTW
4
16
267
34,643
Saiful Haq retweeted
18 Nov 2025
Martin @martin_casado and I had a fun hour-long chat about why we need an AI software layer, and why that's true even if AGI arrives.
This is basically my take on why "the model" is definitely NOT "the product", though models are one way you may decide to implement some products
15
37
183
32,816
Saiful Haq retweeted

14 Nov 2025
Happy Friday Everyone,
DSPyWeekly Issue #11 is live! 🚀
Highlights:
🔹 A cookbook for Self-Evolving Agents
🔹 Teaching local models tool-calling
🔹 New DSPy Neo4j integration
🔹 A new "Events" section to track DSPy meetups!
Plus new projects like codex_dspy & AUTODSPy.
#DSPy #AI #LLMs #AgenticAI #Neo4j
7
9
78
10,672
Saiful Haq retweeted
27 Oct 2025
The labs don't want you to know this (jk) but they have no clue how to best prompt their own models either. To some approximation, you just pre-/post-train it on a lot of data, intervene on certain behaviors, and what comes out is what comes out.
2
1
2
1,028
Saiful Haq retweeted
6 Sep 2025
Ok, I'll say it.
One of the biggest challenges facing DSPy is the lack of competition. As far as I can tell, there's just no other serious programming model for general-purpose, declarative AI programming.
I can spend hours listing the costs/downsides of this, not the least of which is the implicit comparison against LLM libraries in too many people's minds.
Another downside is that it's really hard for an entity to improve by competing against baselines that suck. Too easy to be complacent, so we have to start & keep challenging ourselves.
35
13
320
37,392
Saiful Haq retweeted

28 Jul 2025
New paper out in collaboration with @LakshyAAAgrawal which:
1. Compares rollout efficiency of prompt optimizers and GRPO on DSPy LM programs
2. introduces a new reflective prompt optimizer, GEPA, which will be live on DSPy soon
Lots more exciting work coming soon!
28 Jul 2025
Paper: arxiv.org/abs/2507.19457
GEPA will be open-sourced soon as a new DSPy optimizer. Stay tuned!
Incredibly grateful to the wonderful team @ShangyinT @dilarafsoylu @NoahZiems @rishiskhare @kristahopsalong @arnav_thebigman @krypticmouse @michaelryan207 @Meng_CS @ChrisGPotts @koushik77 @AlexGDimakis @istoica05, Dan Klein, @matei_zaharia @lateinteraction

3
14
43
6,153
Saiful Haq retweeted
29 Jul 2025
Methods that may not have even existed when you wrote your DSPy program...
Policy gradient RL (GRPO) vs Bayesian search over grounded instruction/fewshot proposals (MIPRO) vs Reflective prompt learning (GEPA)
All optimizing identical DSPy programs! And better optimizers to come
28 Jul 2025
How does prompt optimization compare to RL algos like GRPO?
GRPO needs 1000s of rollouts, but humans can learn from a few trials—by reflecting on what worked & what didn't.
Meet GEPA: a reflective prompt optimizer that can outperform GRPO by up to 20% with 35x fewer rollouts!🧵
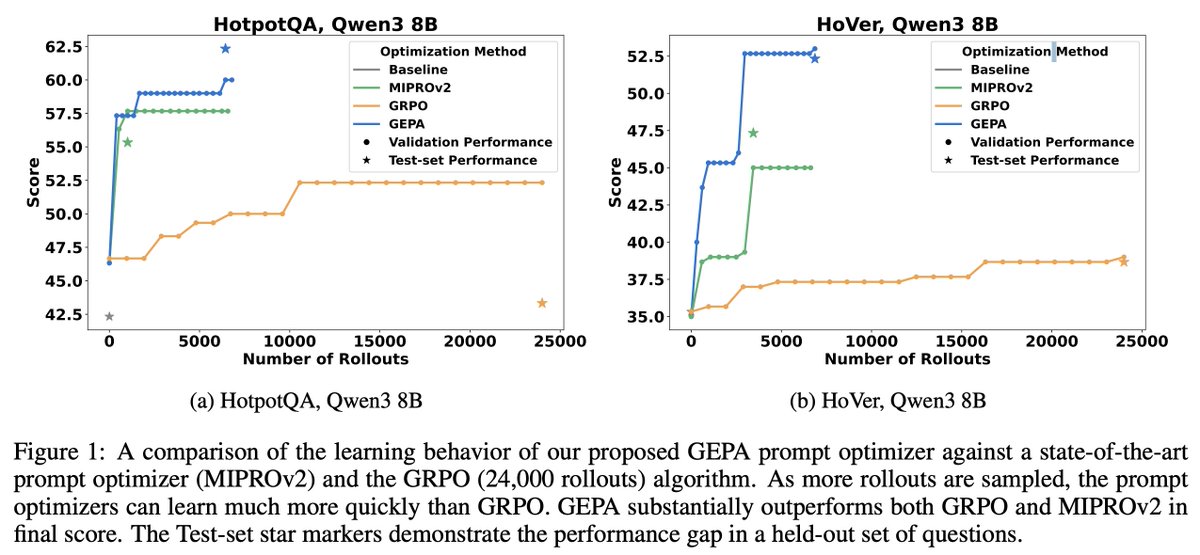
4
20
179
16,251