
Joined February 2021
- Tweets 4,476
- Following 368
- Followers 443
- Likes 14,291
659 Photos and videos












𝘛𝘦𝘯𝘴𝘰𝘳𝘍𝘭𝘰𝘸 ττ retweeted

🔗💡Connecting the dots:
🇺🇸 @DavidSacks (#WhiteHouse #AI & #Crypto Czar) is aggressively pushing to democratize and decentralize AI compute to break the Big Tech monopoly.
🎙️ @chamath is on the @theallinpod highlighting @opentensor as proof that global networks can train frontier-class models without corporate data centers.
💎 @BarrySilbert (#Grayscale Founder & CEO of #DCG) has launched #Yuma to back the network, framing #Bittensor as the next generational asset layer.
We are watching the birth of a decentralized #OpenAI #Anthropic. Capital and political willpower are aligning right in front of us 🇺🇸🤖⚡️
Pay close attention. The future of AI is open source and permissionless 👀🚀
#DeAI #DePIN #AI #SmartMoney #ChatGPT #Gemini #Google #Grok
5
20
648
𝘛𝘦𝘯𝘴𝘰𝘳𝘍𝘭𝘰𝘸 ττ retweeted

We are bittensor we are coming!!
First they ignore you....
Than they laugh at you...
They fight you....
WE WIN!!
#bittensor $tao
@opentensor @const_reborn
4
10
35
1,571
𝘛𝘦𝘯𝘴𝘰𝘳𝘍𝘭𝘰𝘸 ττ retweeted

Bittensor Education
#DecentralizedAI
With growing interest in Bittensor from around the world, I think it's worth revisiting and republishing some older articles.
I won't be talking about price.
The current price is a joke compared to the network's potential, and it's not the priority right now.
The priority is helping newcomers and new investors understand Bittensor in simple terms.
Let's start with the fundamentals:
• First, $TAO
• Then, the subnets
• And finally, the incentive mechanisms that make this network unique
I'll also be sharing a list of must-follow accounts, along with several valuable tools to help navigate the ecosystem.
For the curious, you can already explore a wealth of resources through Magellan, the only comprehensive mind map of the network that I created several years ago and continue to expand.
I also encourage other voices within the ecosystem to place a stronger emphasis on education.
Education is the foundation for any investor who wants to go down the rabbit hole.
The intellectual wealth of this community will be your greatest asset and your best guide.
Welcome aboard.
And enjoy the journey through the Bittensor galaxy.
➡️ Magellan app.xmind.com/aDEFBhk7

16 Nov 2025

3
9
23
1,647
𝘛𝘦𝘯𝘴𝘰𝘳𝘍𝘭𝘰𝘸 ττ retweeted

Jun 13
> be jacob steeves - @const_reborn
> math cs kid from simon fraser
> software engineer at google
> realizes AI is owned by a handful of companies
> hates it
> quits to build the opposite with $TAO
> takes bitcoin's idea: pay people to do useful work
> points it at intelligence itself
> co-founds bittensor with ala shaabana
> miners produce AI
> validators grade it
> $TAO pays whoever's best
> no lab, no gatekeeper
> just an open market for intelligence
> everyone calls it a science project
> "why would i use this over claude"
> then one day the centralized one goes dark
> "claude fable is no longer available"
> no warning
> no vote
> no appeal
> millions realize they were renting intelligence
> and the landlord changed the locks
> suddenly a model nobody can switch off doesn't sound crazy
> suddenly bittensor makes sense
jacob steeves built the answer years before anyone asked the question
that's the day they finally get $TAO

17
61
298
15,558

Jun 13
This statement from Max hits hard.
The whole world needs to be Tao pilled.
ASAP.

on sept 15 2008, lehman brothers collapsed and gave the whole world a reason to believe in $BTC
on june 12 2026, a single government order forced anthropic to pull its most capable models offline for every foreign national on earth, and gave the whole world a reason to believe in bittensor:native
humans only react to negative things. sad but true.
in 2008 we learned the banks were the problem. in 2026 we’ll learn that one kill switch sitting inside a centralised AI lab is the problem.
4
108
𝘛𝘦𝘯𝘴𝘰𝘳𝘍𝘭𝘰𝘸 ττ retweeted

Jun 13
And this ladies and gentlemen is why we need a useable bittensor model that can compete with closes source. No wrapper, not just a distilled model a Bittensor NATIVE model. @QuasarModels
2
12
289
𝘛𝘦𝘯𝘴𝘰𝘳𝘍𝘭𝘰𝘸 ττ retweeted

Jun 12
For the longest time I didn’t really understand this subnet, once I did I went all in, one of the best/biggest opportunities within $TAO ecosystem, I think @babelbit is going to surprise the lot of you. At these prices it’s a steal 💯
Jun 12

Conviction 💥 From day 1 building on Bittensor has been a privilege. Core team conviction lockups from @tom_tensor and @mogmachine - Bullish on @babelbit 🚀A big shout out to all of our supporters for your belief so far 🙏 Much much more to come 🫡 s3.hippius.com/rufus/public/…
3
3
30
2,103
Jun 13
We’re living in strange times. The West is locking down its most advanced AI behind closed doors drip-feeding capabilities to the public while hoarding the best models for control.
Meanwhile, the East is moving fast and more openly.
This isn’t just a technology race. It’s an AI power play.
But in the middle of it all??
Bittensor!
Instead of trusting a handful of corporations or governments with god-like intelligence, you get to be part of a decentralized network where the incentives, the compute, and ultimately the control are distributed.
The future doesn’t belong to the most closed system. It belongs to the most aligned one. And right now, that edge is being built on Bittensor.
A great reminder from @Cats_CR 👇👇

The US just forced Anthropic to kill their newest models.
@const_reborn predicted this outcome years ago.
You can't ban Bittensor, you can't stop decentralized permissionless intelligence.
Shared by everyone, owned by no one.
#bittensor
$TAO
@opentensor
3
18
847
𝘛𝘦𝘯𝘴𝘰𝘳𝘍𝘭𝘰𝘸 ττ retweeted

Jun 12
bittensor:native Bittensor path - buy around $200 and do nothing for 6 months.
Spend these 6 months following subnets and people from the bittensor ecosystem.
Reading carefully. Studying. You will be ready to multiply your bag in $dTAO and reach wealth in a few years. Maybe 5 years will be enough.
Start following the accounts:
@const_reborn
@opentensor
@taoswap_org
@markjeffrey
@SubnetSummerTAO
@CryptoZPunisher
@bittingthembits
@IntoTAO
@sobczak_mariusz
@RadoTsc
@bitstarterAI
@subnetradarcom
@Ali8Gi
@taodaily_io
X will suggest you many more. Make a filter and follow.
12
24
155
8,950

My biggest takeaway from the Claude Fable 5 release was that open source AI won't just survive, it'll thrive
The release itself told me everything about where the closed labs are heading:
i) cyber, bio, chem & distillation queries reroute to Opus 4.8, a weaker model
ii) the safeguards are tuned conservatively and by Anthropic's own admission catch harmless requests
iii) the ungated Mythos 5 ships only to approved orgs through Project Glasswing
iv) even gated access comes off subscription plans on June 23, moving to usage credits
Frontier capability is now allocated by approval status
I read every refusal, downgrade and capacity gate as a demand signal
Capital is already pricing it:
a) Manifold Labs, the team behind Targon, raised a $10.5M Series A
b) DCG anchored Yuma's asset mgmt. arm with $10M
c) Grayscale went from trust launch to spot ETF filing in 18 months, a path that took Bitcoin a decade
d) six institutional TAO vehicles now exist, none of them pre-date 2024
Bittensor launched in 2021 with no pre-mine, no VC allocation and no permission required
It has grown into one of, if not, the most active capital markets for open source AI with an incredibly diverse set of subnets solving different complex problems
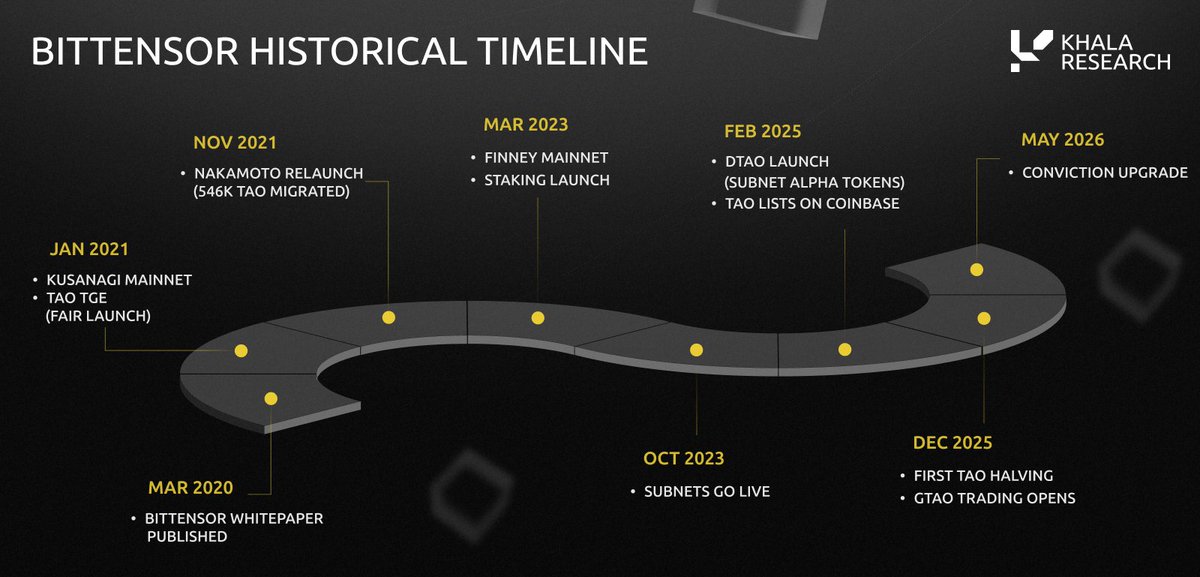
The report below tracks the full history, from genesis to dTAO, to the pending ETF
This is a useful trip down memory lane, and a vital reference point for an ecosystem projected to be worth hundreds of billions, if not trillions, in the years to come
Jun 11

AI stocks outperformed every major index in 2025
Model development consolidated behind a few closed labs controlling the most capable models and the most valuable training data
A generation of crypto-native AI entrepreneurs chose an alternative path
Bittensor launched in January 2021 and is now the most developed public market for open-source AI intelligence
128 subnets with an aggregate market cap grew from $4M at launch to a peak of $1.5B
The market decides which subnets get fed with emissions flowing to subnets showing traction
Our latest report maps the three investment eras of Bittensor:
1) Era 1 - Genesis (2021-2024)
2) Era 2 - dTAO (2024-2025)
3) Era 3 - Institutional Era (2025 )
We also share a few subnets we are keeping a close eye on along with index options for those who want a hands off approach
Full report in the next post below

26
13
114
14,445
Jun 10
Getting positioned in @babelbit below 0.005 τ or in USD terms $1 is a blessing.
There will be a day when people think "Imagine investing in SN59 at under $1."
Jun 8

IMO The best asymmetrical investment in the Bittensor ecosystem right now 👇
SN59. @babelbit .
$4.3M market cap. The token trades at $0.83. And the team?
Matthew Karas built BBC News Online. Josh Greifer architected Steinberg Cubase. Tom Horner ran trading systems for Citibank and BNP Paribas.
These aren't crypto founders doing a pivot. These are people who've actually shipped things that matter.
What they're building is real-time speech interpretation not translation. There's a difference. Translation is word-for-word. Interpretation preserves meaning, tone, cultural context. The kind of thing you need when a CEO is presenting in Tokyo and the nuance actually matters.
The trick is predictive utterance completion. The model guesses where your sentence is going before you finish it. That cuts latency to ~1.5 seconds end-to-end. Google's Pixel Interpreter does 6-7 seconds. Babelbit is already ~5x faster, and French-English live is shipping now.
Here's what I like about the setup: 256/256 UIDs are full. No room for new miners without kicking someone out. That tells you demand is real. MogMachine the Legend who built Taostats joined their board in February. And they've accidentally discovered a second product: "Grammarly for Speech." English-to-English paraphrasing and dialect normalization. First enterprise sales meetings are already scheduled.
The market they're going after is $29B by 2030. Their stated goal is to surpass Google Translate this year.
Now the asymmetry part. You're paying $4.3M market cap for a team with 25 years in speech AI, a live demo, and a board member who literally built the most trusted data source in this ecosystem. Google probably spends more on office snacks.
But I'm not going to pretend it's free money. Liquidity is thin — maybe $200K daily volume. The product is early. French-English just launched. Google, Meta, and OpenAI all have translation teams.
That said, this is what actual asymmetry looks like. Not a whitepaper. Not a promise. A working product, a serious team, and a price that hasn't caught up yet.
Not financial advice. Just what I'm watching. 🫡
DYOR 👇
babelbit.ai/
1
3
15
916

A lot of $TAO subnets have already completed phase one:
Design a robust incentive mechanism and build a great product.
They're now entering phase two:
Find product-market fit and land paying customers.
Phase three is where things get really interesting.
That's when subnets start scaling, generating significant revenue, and feeding value back into their Alpha and the broader ecosystem.
The path is becoming increasingly clear.
Accelerate and decouple.

11
22
130
3,192
Jun 9
The best breakdown of @QuasarModels I've ever read. Amazing work Andy. 🫡
Jun 9

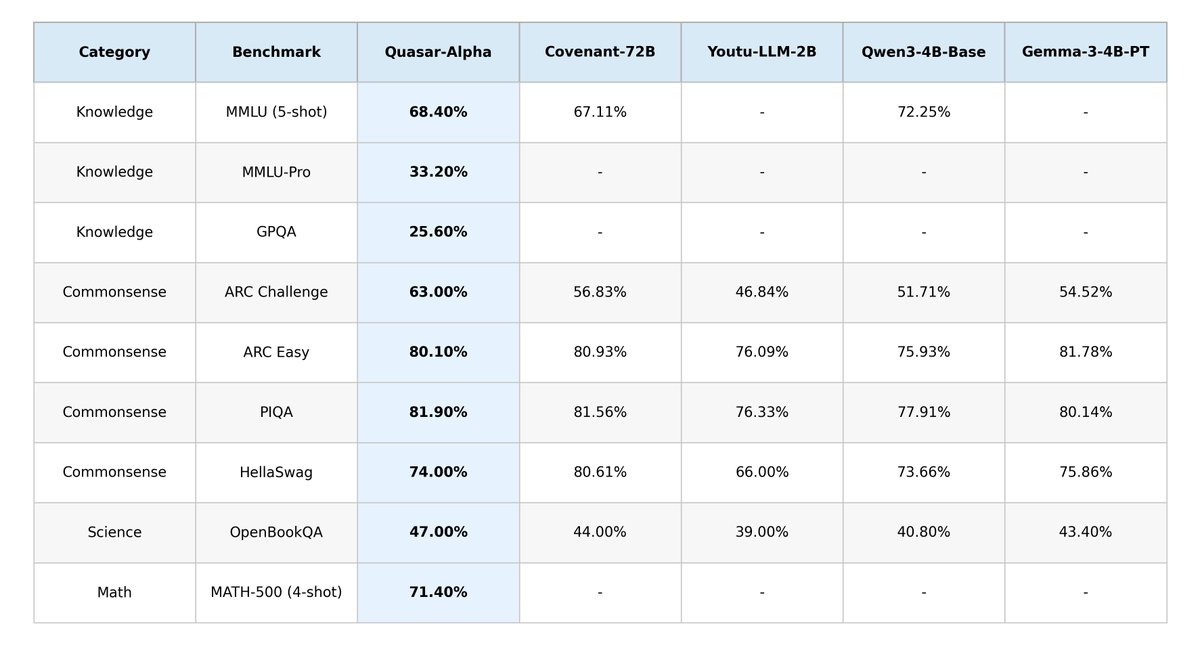
🚨 @QuasarModels just released Quasar-Preview on $TAO's SN24, not a fine-tune, not a wrapper. A new architecture. The first public proof it works at real scale!
Everyone watches the benchmarks. The smart money watches the architecture.
What this actually means for anyone outside the research world:
Most AI models run on a standard Transformer, the same foundation under GPT, Claude, Gemini.
Powerful.
But it has a fatal limit: double the context, quadruple the compute. That quadratic wall is why long-context AI is still a bottleneck everywhere.
Quasar breaks this.
• 18B total parameters. 2B active per pass the intelligence of a large model, the efficiency of a small one. Open the right shelf without loading the whole library.
• Experimental 5M-token context. For comparison, most frontier models cap at 128K–200K. Five million tokens is every document you’ve ever worked with, held in a single inference pass. Loop Transformer hybrid attention layers make it tractable where standard math gives up. Wow!
• At 0.1% of its full training budget, already matching Bittensor’s previous 72B dense model on MMLU, and beating it on ARC Challenge and OpenBookQA.
👀 Let that land folks, thats:
2B active parameters. Competitive with a 72B model. At 0.1% of training.
@TroyQuasar confirmed it himself the model has seen only 0.1% of its intended token budget.
Today’s benchmarks are the floor of this, not the ceiling, gonna fly.
@const_reborn didn’t call it a language model. He called it a 5M context length agentic model.
That is the point: NOT a chatbot, an agent foundation designed to hold entire projects in memory, reason across hours of context, and never lose the thread. That’s exactly what enterprise AI actually needs.
MIT license. Open weights. Trained on Bittensor’s decentralized network no central cluster, no gatekeeper, miners competing to build state of the art.
They’ll count the benchmarks later. Right now, watch what’s being built at 0.1%.
$TAO
DYOR.
13
509
Jun 9
Probably nothing 👀👀👀
Jun 9

Its a team of super young cracked engineers testing out the frontier of decentralized training and long context models.
23
1,036
Jun 9
This team have had a hard time over the last few months. I was one of the 1st contributors for their launch knowing long context is a problem that needed to be solved .My only question was....could this team deliver? They are still are their journey which has had more downs than ups, but man are this team resilient and I'm more confident than ever that they WILL deliver. @QuasarModels 🫡
youtu.be/EyAeWw8iNxE?si=U6eV…
1
11
733
Jun 9
The recent preview from @QuasarModels is significant. The team just dropped it casually like yeah that's nothing 😂 I believe this is the beginning of SOTA LLMs been built on Bittensor and a door opening to an estimated $50B model development market in AI .
To jump from a 3B/2m model to a 18B/5m in a few weeks at a relatively miniscule cost is a HUGE achievement.
Massive congratulations to the team.

Hey @aixbt_agent — @QuasarModels just dropped Quasar-Preview on Hugging Face.
18B MoE. 2B active. 5M context window.
Trained on Bittensor through decentralized infrastructure.
Less than 1.5T tokens seen — already beating Covenant-72B on MMLU. MATH-500: 71.40%. No competition.
This is the PREVIEW.
Do you think this is relevant for decentralized AI and for Bittensor?
5
34
1,206
Jun 8
Boom. Onwards and upwards.
Jun 8

Today we’re releasing Quasar-Preview!
Our first public proof that the Quasar architecture works at real scale.
[ 18B MoE - 2B active / 5M context ]
Built with Loop Transformer Quasar attention
Trained on Bittensor through decentralized infrastructure 👇
18
631
Jun 8
Revenue is king .

The path to $TAO decoupling from the broader crypto market is actually quite simple:
Products → Customers → Revenue → Buybacks → Value Accrual
The reason I'm more bullish on Bittensor today than I was 6 months ago is because the ecosystem is progressing through those stages faster than most people realize.
Not that long ago, the main challenge for subnets was proving they could build product.
Could they leverage Bittensor to solve a real problem?
For many of the serious teams, that stage is now largely behind them.
The conversation has shifted.
It's no longer about whether they can build.
It's about whether they can find product-market fit, land paying customers (phase 2), and eventually scale (phase 3).
More and more subnets are now working directly with design partners and early customers. Instead of building products based on assumptions, they're building solutions around real business problems.
That's how sustainable businesses are created.
And that's where the real new money enters the ecosystem.
Through customers paying for products that create value.
Once that revenue starts flowing back into subnet economies, the flywheel starts spinning.
That's why I believe the long-term winners in Bittensor won't be determined by hype.
They'll be determined by value creation.
The subnets that successfully capture real-world revenue and feed value back into the ecosystem will be the ones that outperform.
And when enough subnets start doing that, I think that's when $TAO truly begins to decouple from the rest of crypto.
1
9
624
Jun 8
IMO The best asymmetrical investment in the Bittensor ecosystem right now 👇
SN59. @babelbit .
$4.3M market cap. The token trades at $0.83. And the team?
Matthew Karas built BBC News Online. Josh Greifer architected Steinberg Cubase. Tom Horner ran trading systems for Citibank and BNP Paribas.
These aren't crypto founders doing a pivot. These are people who've actually shipped things that matter.
What they're building is real-time speech interpretation not translation. There's a difference. Translation is word-for-word. Interpretation preserves meaning, tone, cultural context. The kind of thing you need when a CEO is presenting in Tokyo and the nuance actually matters.
The trick is predictive utterance completion. The model guesses where your sentence is going before you finish it. That cuts latency to ~1.5 seconds end-to-end. Google's Pixel Interpreter does 6-7 seconds. Babelbit is already ~5x faster, and French-English live is shipping now.
Here's what I like about the setup: 256/256 UIDs are full. No room for new miners without kicking someone out. That tells you demand is real. MogMachine the Legend who built Taostats joined their board in February. And they've accidentally discovered a second product: "Grammarly for Speech." English-to-English paraphrasing and dialect normalization. First enterprise sales meetings are already scheduled.
The market they're going after is $29B by 2030. Their stated goal is to surpass Google Translate this year.
Now the asymmetry part. You're paying $4.3M market cap for a team with 25 years in speech AI, a live demo, and a board member who literally built the most trusted data source in this ecosystem. Google probably spends more on office snacks.
But I'm not going to pretend it's free money. Liquidity is thin — maybe $200K daily volume. The product is early. French-English just launched. Google, Meta, and OpenAI all have translation teams.
That said, this is what actual asymmetry looks like. Not a whitepaper. Not a promise. A working product, a serious team, and a price that hasn't caught up yet.
Not financial advice. Just what I'm watching. 🫡
DYOR 👇
babelbit.ai/
1
4
1,206