
Jun 13
Just read this excellent technical white paper from @aasaitech on how few-shot prompting enables rapid task adaptation without any fine-tuning or weight updates.
Key highlights: • Core mechanics: task description high-quality demonstrations new query • Critical factors: example quality, relevance, number, model scale & prompt format • Dynamic few-shot pipeline with semantic retrieval (vector store RAG) • Industrial applications: fault diagnosis, maintenance procedures, new equipment commissioning, compliance adaptation — ideal for manufacturing & edge orchestration
This shifts adaptation from costly retraining to fast inference-time learning. Combine with strong retrieval and you get highly adaptable production systems.
Full white paper infographic: x.com/aasaitech/status/20653…
How are you using ICL or dynamic few-shot in your workflows? Static prompts or full RAG pipelines?
#InContextLearning #FewShotLearning #LLM #IndustrialAI #RAG #AgenticAI

1
11

Proposing enhancements to GNN-specific few-shot learning technique for the toxicity prediction task: “#ToxicMoleculeClassification Using #GraphNeuralNetworks and #FewShotLearning.” by B. Mehta, K. Kothari, R. Nambiar, S. Shrawne. ACSIS Vol. 41 p. 105–110; tinyurl.com/2zw7wnr2
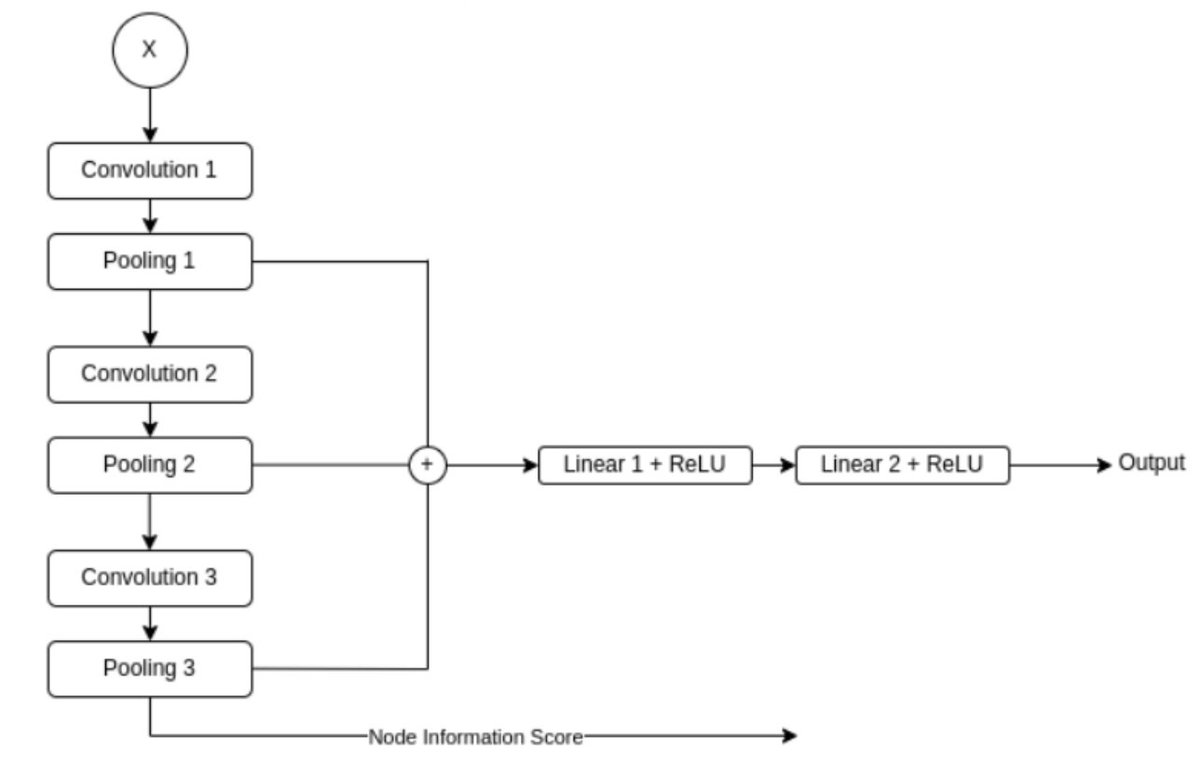
1
3
3
146

🌟 Article of the Week 🌟
This week’s featured article from the IEEE Transactions on Geoscience and Remote Sensing highlights advances in domain adaptation for SAR ship detection using limited training data.
🔍 This Week’s Highlight
Title: A Domain-Adaptive Few-Shot SAR Ship Detection Algorithm Driven by the Latent Similarity Between Optical and SAR Images
Authors: Zheng Zhou, Lingjun Zhao, Kefeng Ji, Gangyao Kuang
📖 🌐 Detecting ships in SAR imagery is challenging due to limited labeled data and complex environments. This study introduces a domain-adaptive few-shot approach that leverages knowledge from optical images to improve SAR ship detection, enabling accurate results even with minimal SAR training samples.
🔗 Read the full paper here: doi.org/10.1109/TGRS.2024.34…
Stay tuned for more groundbreaking research every week as we celebrate excellence in geoscience and remote sensing! 🌍📡
#IEEEGRSS #RemoteSensing #SAR #Geoscience #ieeexplore #MachineLearning #DomainAdaptation #FewShotLearning #GeospatialAI #EarthObservation #ObjectDetection #AOTW

2
7
255
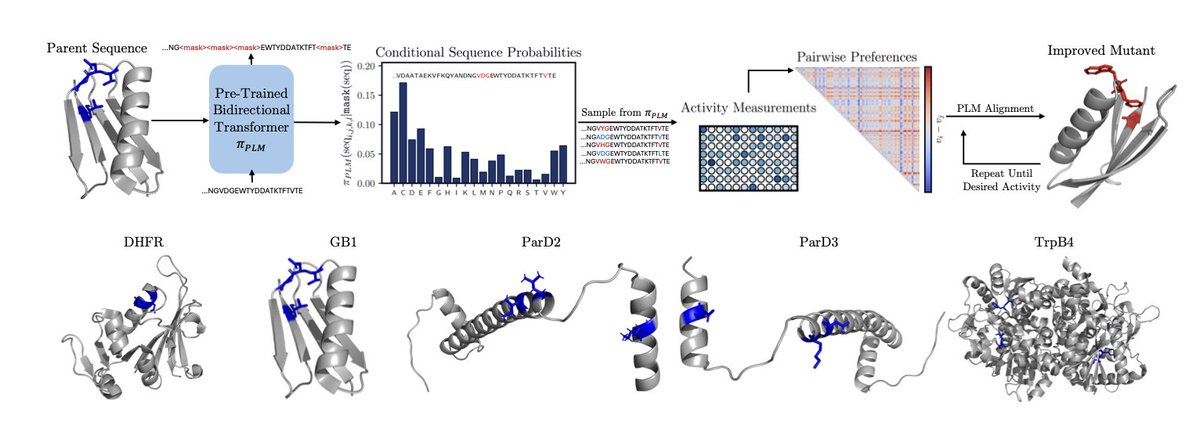
Efficient, Few-shot Directed Evolution with Energy Rank Alignment
1. A new method called Energy Rank Alignment (ERA) enables highly efficient protein engineering by adapting large pre-trained protein language models using minimal experimental data.
2. Unlike previous approaches that rely on simple models due to sparse data constraints, ERA leverages the strong inductive biases of ESM3-1.4B, a 1.4 billion parameter protein language model, to navigate complex fitness landscapes.
3. The key innovation is using quantitative experimental rankings rather than just binary preferences, allowing the model to preserve relative fitness magnitudes while learning from small batches of just 96 sequences per round.
4. ERA outperforms existing methods including MLDE, ALDE, EVOLVEpro, and Direct Preference Optimization across five diverse combinatorial fitness landscapes involving antibiotic resistance, antibody binding, and enzymatic activity.
5. The method achieves state-of-the-art performance with only 384 total samples across four rounds, successfully finding global optima even in landscapes with strong epistatic effects and rugged topography.
6. Surprisingly, adding structural conditioning or thermostability pre-training did not improve performance, suggesting that pure sequence-based adaptation is sufficient for effective directed evolution.
7. The adapted models maintain sequence diversity while shifting probability mass toward high-fitness regions by several orders of magnitude, making them interpretable and useful for understanding biophysical requirements.
8. This work establishes a compelling interface between foundation models and experimental design, demonstrating how post-training algorithms from statistical physics can solve real biological optimization problems.
💻Code: github.com/rotskoff-group/er…
📜Paper: biorxiv.org/content/10.64898…
#ProteinEngineering #DirectedEvolution #MachineLearning #Bioinformatics #ProteinDesign #ESM3 #ComputationalBiology #FewShotLearning
2
11
52
2,871
PCEvo: Path-Consistent Molecular Representation via Virtual Evolutionary
1 PCEvo turns the classic “one molecule, one vector” paradigm on its head by replacing static snapshots with virtual evolutionary trajectories, letting models watch molecules mutate step-by-step instead of just staring at endpoints.
2 For every pair of similar compounds it retrieves the top-K structural neighbors, computes the minimal graph-edit script (add/remove atoms/bonds), then samples up to 50 chemically valid orderings of these edits—turning a single label pair into dozens of intermediate supervision signals.
3 A shared encoder processes each intermediate structure; a lightweight delta-predictor turns the latent difference between consecutive steps into predicted property increments. The summed increments are forced to equal the observed endpoint difference, so the same net change is recovered no matter which valid path is taken.
4 The path-consistency loss acts like a self-assembled curriculum: the model must explain how each tiny edit contributes to the final property, decomposing one sparse label into many local gradients. This boosts effective sample size and tightens generalization bounds under Rademacher analysis.
5 On QM9 100-shot HOMO/LUMO prediction PCEvo drops MAE by 11–29 % and lifts PCC from near-zero to >0.76 across SchNet, DimeNet, Equiformer and ViSNet; gains persist at 1000-shot and transfer to MoleculeNet solubility/lipophilicity tasks.
6 Ablation shows the magic only happens when ≥2 paths are sampled and the consistency term is switched on; simply duplicating molecules without path constraints gives no reliable lift, confirming that enforcing path-invariance—not mere data augmentation—is the key driver.
7 The method is backbone-agnostic, adds <5 % training time, needs no extra assays or 3D conformers, and code is fully open, so any GNN or transformer can be evolutionary-upgraded in an afternoon.
💻Code: anonymous.4open.science/r/PC…
📜Paper: arxiv.org/abs/2601.19257
#ChemAI #GraphML #FewShotLearning #MolecularRepresentation #DrugDiscovery

1
1
16
1,308

3 Dec 2025
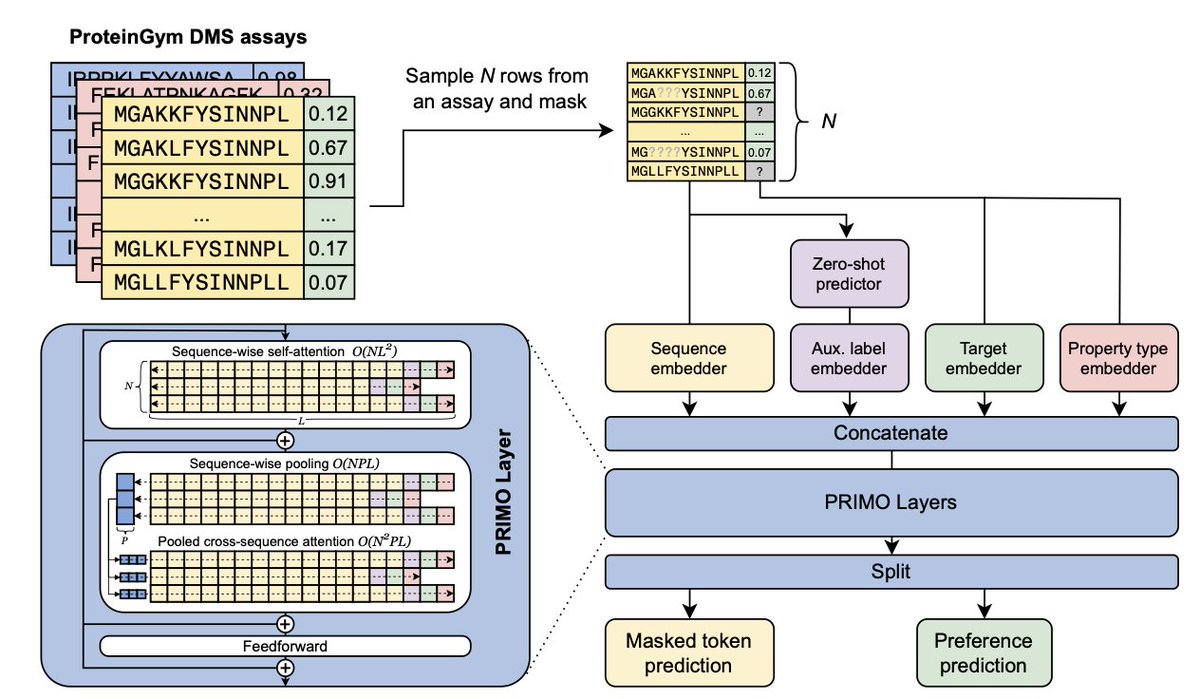
Few-shot Protein Fitness Prediction via In-context Learning and Test-time Training
1. The article introduces PRIMO, a novel transformer-based framework that leverages in-context learning and test-time training to predict protein fitness with minimal experimental data. This approach is particularly innovative for protein engineering where large-scale data is often scarce.
2. PRIMO encodes sequence information, auxiliary zero-shot predictions, and sparse experimental labels into a unified token set within a pre-training masked-language modeling paradigm. It uses a preference-based loss function to prioritize promising protein variants.
3. The framework significantly outperforms both zero-shot and fully supervised baselines across diverse protein families and properties, including substitution and indel mutations. This demonstrates the power of combining large-scale pre-training with efficient test-time adaptation.
4. PRIMO handles both single-substitution and indel variants, making it more practical for real-world protein design scenarios. It also introduces a new natural evolution benchmark to assess models in challenging settings where train and test sequences are farther apart in sequence space.
5. The study highlights the importance of proper data splitting to avoid inflated performance metrics and the effectiveness of test-time training in adapting to new assays. This work underscores the potential of in-context learning paradigms for few-shot fitness prediction.
📜Paper: arxiv.org/abs/2512.02315v1
#ProteinEngineering #MachineLearning #Bioinformatics #FewShotLearning
4
18
1,782
3 Dec 2025
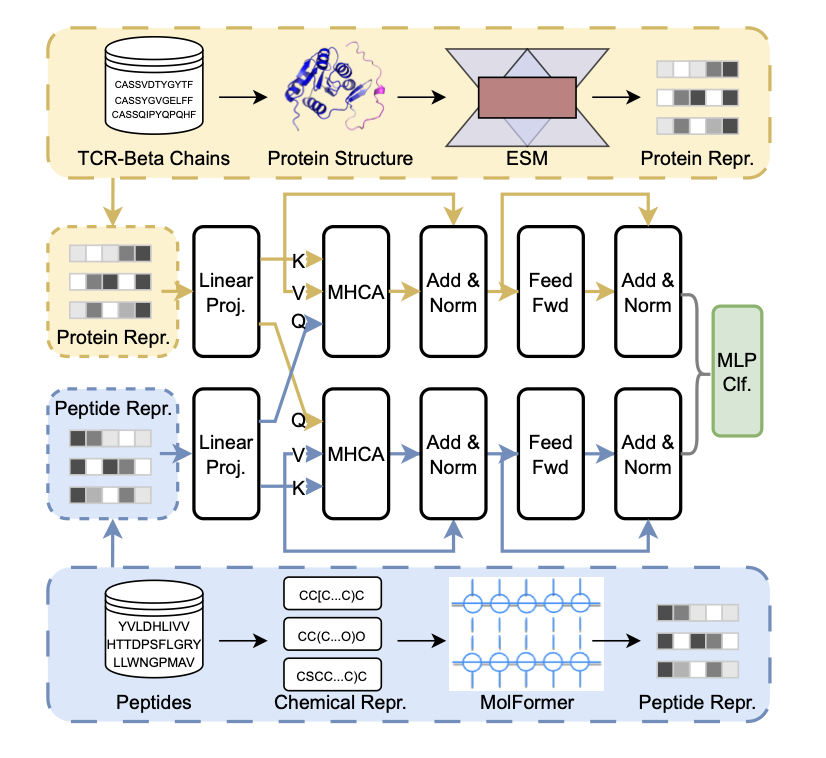
Modeling TCR–pMHC Binding with Dual Encoders and Cross-Attention Fusion
1. A new study introduces TIDE, a dual-encoder framework that uses cross-attention to predict TCR–pMHC binding interactions. This approach leverages large protein and molecular language models to capture complex interactions without needing explicit structural alignment.
2. TIDE encodes TCR sequences using Evolutionary Scale Modeling (ESM) and transforms peptides into SMILES strings processed by MolFormer. This combination allows the model to capture both biochemical and spatial properties of the interactions.
3. The model demonstrates superior performance in zero-shot and few-shot learning scenarios, outperforming state-of-the-art methods like ChemBERTa, TITAN, and NetTCR. This highlights its ability to generalize to unseen epitopes with minimal supervision.
4. TIDE's multi-head cross-attention mechanism refines and integrates TCR and peptide embeddings, highlighting interaction-relevant patterns. This design enhances the model's interpretability and robustness in low-data settings.
5. The study evaluates TIDE across multiple negative sampling strategies, showing its effectiveness in different training conditions. This comprehensive analysis ensures the model's reliability for practical applications.
6. The code and datasets for reproducing the experiments are available, promoting transparency and further research in computational immunology.
📜Paper: biorxiv.org/content/10.64898…
#TCRBinding #ComputationalImmunology #CrossAttention #FewShotLearning #Bioinformatics
2
12
1,150
29 Oct 2025
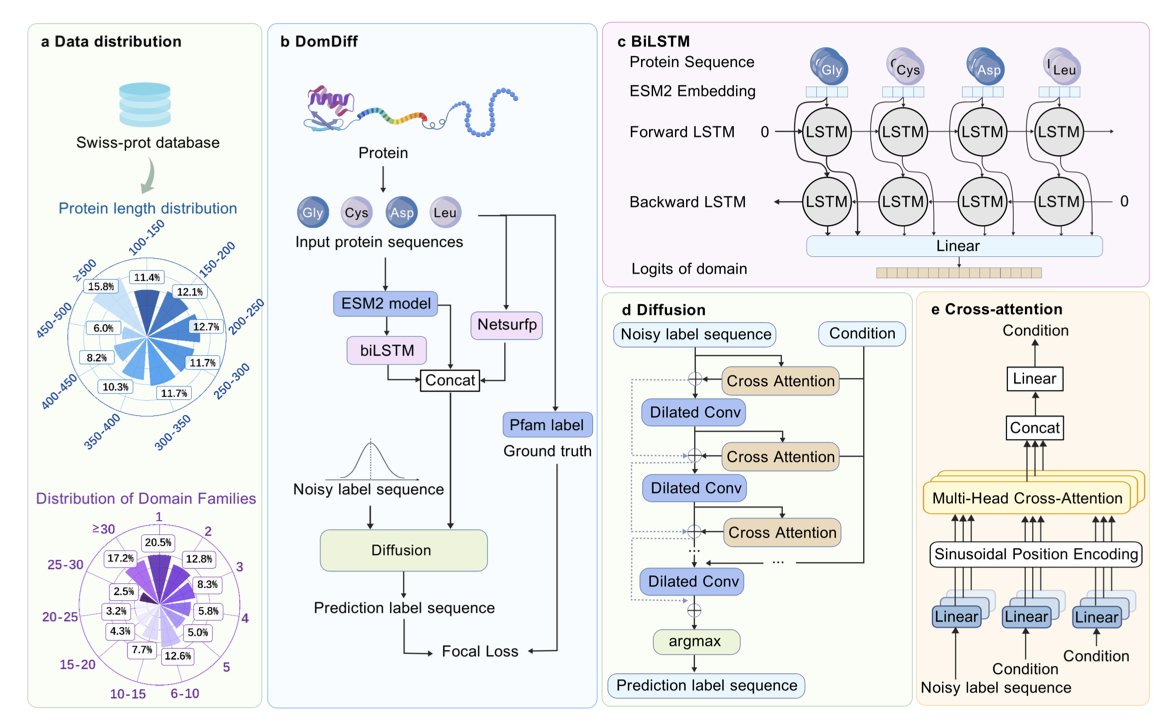
DomDiff: Protein Family and Domain Annotation via Diffusion Model and ESM2 Embedding
1. DomDiff is a novel framework for identifying conserved protein domain boundaries and classifying protein families. It leverages a conditional diffusion model combined with ESM2 embeddings to achieve state-of-the-art performance in domain boundary identification and classification.
2. The core innovation of DomDiff lies in its ability to reformulate the domain identification task as a generative process. It generates domain labels from Gaussian noise through iterative denoising, allowing for coarse-to-fine optimization and robust handling of fuzzy boundaries.
3. DomDiff integrates multiple biological features, including ESM2 embeddings, secondary structures predicted by NetSurfP, and biLSTM priors. This multimodal fusion enables the model to capture complex patterns within amino acid sequences and address the challenge of few-shot learning for rare protein families.
4. In benchmark analyses on publicly available datasets, DomDiff outperformed existing methods, achieving a 12.6% improvement in boundary detection and a 4.2% increase in classification accuracy compared to other leading models.
5. The iterative denoising process of DomDiff is particularly effective for long sequences and multidomain proteins. It first corrects large-scale topological errors and then refines boundary precision, resulting in high-quality domain annotations even in complex scenarios.
6. DomDiff's performance is validated on both Swiss-Prot and COG datasets, demonstrating its robustness and generalizability. It shows significant improvements in annotating rare families, making it a powerful tool for large-scale genome annotation and functional characterization of novel proteins.
7. The ablation studies confirm the necessity of each component in the DomDiff framework. The combination of biLSTM priors, diffusion model, and structural features from NetSurfP contributes to its superior performance, highlighting the importance of synergistic integration of different biological information.
8. Future work on DomDiff will focus on expanding reference datasets to include more rare families and exploring the integration of tertiary structure information. This will further enhance its capability in domain boundary delineation and classification.
📜Paper: biorxiv.org/content/10.1101/…
💻Code: github.com/zhangchao162/DomD…
#Bioinformatics #ProteinDomain #DiffusionModel #ESM2 #GenomeAnnotation #FewShotLearning
1
5
40
2,393
14 Oct 2025
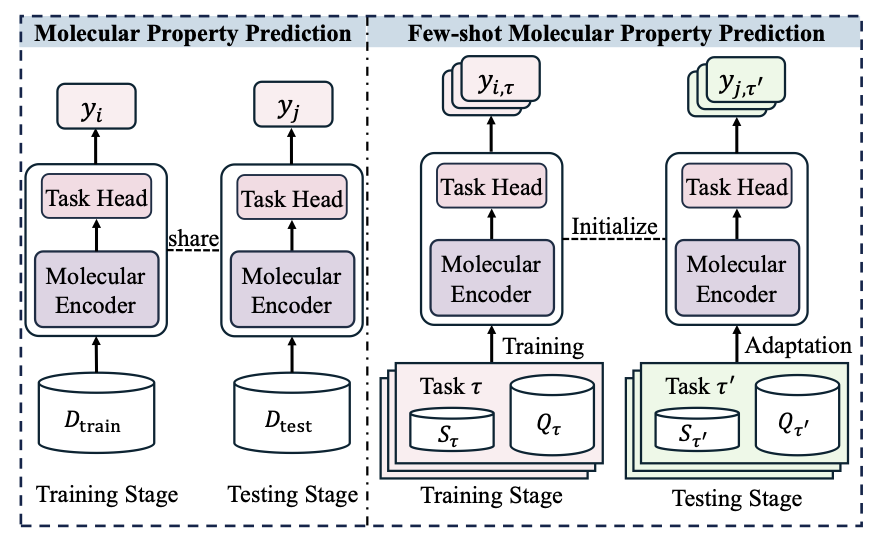
Few-shot Molecular Property Prediction: A Survey
1. This comprehensive survey explores the emerging field of few-shot molecular property prediction (FSMPP), a critical technique for early-stage drug discovery and materials design. The authors highlight the challenges of scarce and low-quality molecular annotations, which limit the effectiveness of traditional AI models.
2. The survey identifies two core challenges in FSMPP: cross-property generalization under distribution shifts and cross-molecule generalization under structural heterogeneity. These challenges arise from the diverse biochemical mechanisms and structural diversity of molecules.
3. A unified taxonomy is proposed to categorize existing FSMPP methods into three levels: data, model, and learning paradigm. This framework helps to systematically understand how different methods address the challenges of limited supervision and generalization.
4. Data-level methods focus on generating new molecular samples or constructing implicit relations between molecules to enhance generalization. Techniques include generative molecule data augmentation and implicit molecule relation construction.
5. Model-level methods aim to learn robust and transferable molecular representations. This includes multi-view learning approaches that integrate different molecular modalities (e.g., SMILES strings, molecular graphs) to capture comprehensive structural information.
6. Learning paradigm methods focus on optimizing the training process to improve model adaptability. Strategies include adapter-based generalization, reformulated parameter optimization, and other innovative training routines.
7. The survey also provides a detailed comparison of representative methods, summarizes benchmark datasets, and discusses key future directions for FSMPP research. The authors emphasize the importance of integrating domain knowledge and improving model interpretability.
8. The repository of papers, code, and datasets is available at github.com/Vencent-Won/Aweso… for further exploration by researchers in the field.
📜Paper: arxiv.org/abs/2510.08900v1
#FewShotLearning #MolecularPropertyPrediction #DrugDiscovery #AIinChemistry #SurveyPaper
1
5
799
20 Sep 2025
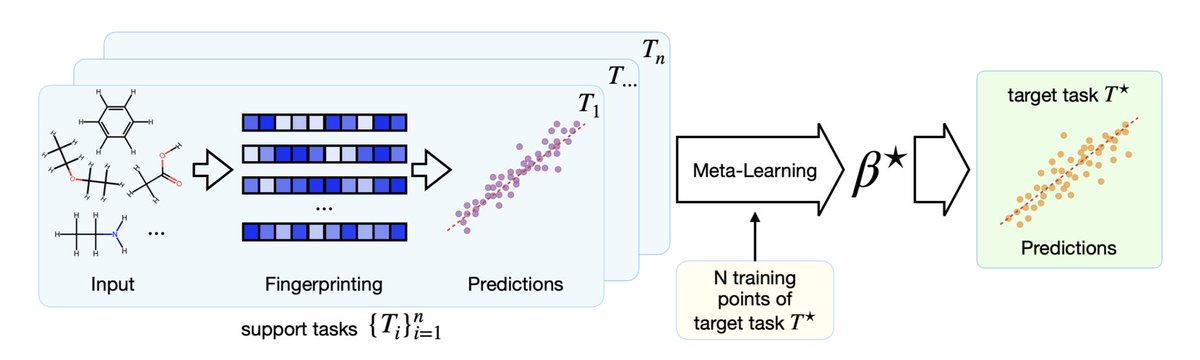
Meta-Learning Linear Models for Molecular Property Prediction
1. This paper introduces LAMeL, a novel linear meta-learning algorithm designed specifically for molecular property prediction in chemistry. LAMeL aims to bridge the gap between predictive accuracy and interpretability by leveraging shared model parameters across related tasks to improve prediction accuracy while maintaining the transparency of linear models.
2. The core innovation of LAMeL lies in its ability to identify a common functional manifold across related tasks, even if those tasks do not share data. This manifold serves as an informed starting point for new, unseen tasks, enabling rapid adaptation with minimal data. The method delivers significant performance improvements over traditional linear methods, with enhancements ranging from 1.1 to 25-fold depending on the dataset.
3. The study validates LAMeL across multiple chemical domains, including solubility prediction and molecular energy prediction. For solubility prediction, LAMeL achieves up to a 60% increase in accuracy compared to conventional ridge regression, highlighting its effectiveness in low-data regimes. The performance gains are closely tied to the degree of similarity among support tasks, with water solubility predictions showing limited improvement due to its chemical distinctiveness.
4. In the case of molecular energy prediction using the QM9-MultiXC dataset, LAMeL demonstrates remarkable accuracy improvements, especially in few-shot learning scenarios. The algorithm achieves stable error levels across different substructure sizes, showing resilience against overparameterization. This suggests that LAMeL can effectively balance the bias-variance trade-off, even with high-dimensional representations.
5. The paper also investigates the impact of support task composition on meta-learning performance. It finds that larger per-task datasets yield more accurate linear regression fits, which subsequently elevate target task prediction accuracy. However, the study highlights that task similarity remains a critical factor for successful knowledge transfer, with chemically distinct solvents like water showing limited meta-learning benefits.
6. The authors conclude that LAMeL is a powerful and computationally efficient paradigm for molecular property prediction. It enables significant accuracy gains with minimal data, making it a valuable tool for accelerating high-throughput screening and materials discovery, particularly in domains where experimental resources are limited. Future work may explore the integration of nonlinear meta-learners for interpretability and the extension of linear meta-learning to more chemically diverse systems.
📜Paper: arxiv.org/abs/2509.13527
#MetaLearning #Chemistry #MolecularPropertyPrediction #Interpretability #MachineLearning #FewShotLearning
2
1
13
1,448

14 Sep 2025
How AI Learns From Just 2 Examples 🤯 | It Uses Few Shot Learning - YouTube youtube.com/shorts/hZ1HREdVj… #AI #MachineLearning #FewShotLearning #aiexplained #algorithm

5
248

28 Aug 2025
New in Artificial Intelligence in Medicine (Vol. 147, 2024):
Meta-learning meets general practice.
FSDD-MAML achieves 90.02% precision@1 in disease diagnosis—especially for few-shot cases.
A breakthrough for safer, smarter primary care.
doi.org/10.1016/j.artmed.202…
#AIinMedicine #FewShotLearning #MetaLearning #PrimaryCare #Medmultilingua
3
3
99
1 Aug 2025
Enabling Few-Shot Alzheimer’s Disease Diagnosis on Tabular Biomarker Data with LLMs
1. This study proposes TAP-GPT, a novel framework that adapts TableGPT2, a multimodal tabular-specialized LLM, to diagnose Alzheimer’s disease (AD) using small sample sizes of structured biomarker data. This is the first application of LLMs to tabular biomarker data in biomedicine, paving the way for future LLM-driven multi-agent frameworks in AD diagnosis and general health informatics.
2. TAP-GPT constructs few-shot tabular prompts using in-context learning examples from structured biomedical data and fine-tunes TableGPT2 using the parameter-efficient qLoRA adaptation for a clinical binary classification task of AD or cognitively normal (CN). The framework leverages the powerful tabular understanding ability of TableGPT2 and the encoded prior knowledge of LLMs to outperform more advanced general-purpose LLMs and a tabular foundation model (TFM) developed for prediction tasks.
3. The study demonstrates that TAP-GPT achieves promising performance on the challenging task of few-shot tabular prediction for AD diagnosis using the public QT-PAD benchmark dataset, comparable or even outperforming more advanced generic LLMs and tabular foundation model approaches. This highlights the potential of finetuned table-language models to tackle structured prediction with limited data in the biomedical domain.
4. TAP-GPT provides a comprehensive analysis covering different ablation settings and the interpretability analysis of the proposed framework. The framework can generate human-readable reasoning for its tabular predictions, which is crucial for building interpretability and future integration into trustworthy multi-agent systems. This sets TAP-GPT apart from traditional machine learning models or foundation models like TabPFN that lack this capability.
5. The experiments conducted show that TAP-GPT performs significantly better than TabPFN in the few-shot tabular setting, with a mean improvement in AUROC scores. The study also explores the impact of different prompt formats and the optimal number of in-context examples (k) for few-shot learning, providing valuable insights for future research and application of data-efficient learning in AD diagnosis and other biomedical applications.
📜Paper: arxiv.org/abs/2507.23227
#AlzheimersDisease #LLMs #BiomedicalInformatics #FewShotLearning #TabularData #AIInHealthcare

2
7
828
1 Aug 2025
Enabling Few-Shot Alzheimer’s Disease Diagnosis on Tabular Biomarker Data with LLMs
1. This study proposes TAP-GPT, a novel framework that adapts TableGPT2, a multimodal tabular-specialized LLM, to diagnose Alzheimer’s disease (AD) using small sample sizes of structured biomarker data. This is the first application of LLMs to tabular biomarker data in biomedicine, paving the way for future LLM-driven multi-agent frameworks in AD diagnosis and general health informatics.
2. TAP-GPT constructs few-shot tabular prompts using in-context learning examples from structured biomedical data and fine-tunes TableGPT2 using the parameter-efficient qLoRA adaptation for a clinical binary classification task of AD or cognitively normal (CN). The framework leverages the powerful tabular understanding ability of TableGPT2 and the encoded prior knowledge of LLMs to outperform more advanced general-purpose LLMs and a tabular foundation model (TFM) developed for prediction tasks.
3. The study demonstrates that TAP-GPT achieves promising performance on the challenging task of few-shot tabular prediction for AD diagnosis using the public QT-PAD benchmark dataset, comparable or even outperforming more advanced generic LLMs and tabular foundation model approaches. This highlights the potential of finetuned table-language models to tackle structured prediction with limited data in the biomedical domain.
4. TAP-GPT provides a comprehensive analysis covering different ablation settings and the interpretability analysis of the proposed framework. The framework can generate human-readable reasoning for its tabular predictions, which is crucial for building interpretability and future integration into trustworthy multi-agent systems. This sets TAP-GPT apart from traditional machine learning models or foundation models like TabPFN that lack this capability.
5. The experiments conducted show that TAP-GPT performs significantly better than TabPFN in the few-shot tabular setting, with a mean improvement in AUROC scores. The study also explores the impact of different prompt formats and the optimal number of in-context examples (k) for few-shot learning, providing valuable insights for future research and application of data-efficient learning in AD diagnosis and other biomedical applications.
📜Paper: arxiv.org/abs/2507.23227
#AlzheimersDisease #LLMs #BiomedicalInformatics #FewShotLearning #TabularData #AIInHealthcare

1
5
680

23 Jul 2025
💡 Promptomatix beats manual existing frameworks
Across QA, math, summarization, and classification:
✅ Better performance
✅ Shorter prompts
✅ Lower compute cost
It even adapts to your constraints: quick search vs heavy search = instant vs thorough optimization.
#PromptEngineering #PromptOptimization #LLM #AI #DSPy #FewShotLearning #NLP #AIBenchmarking
1
3
567

16 Jul 2025
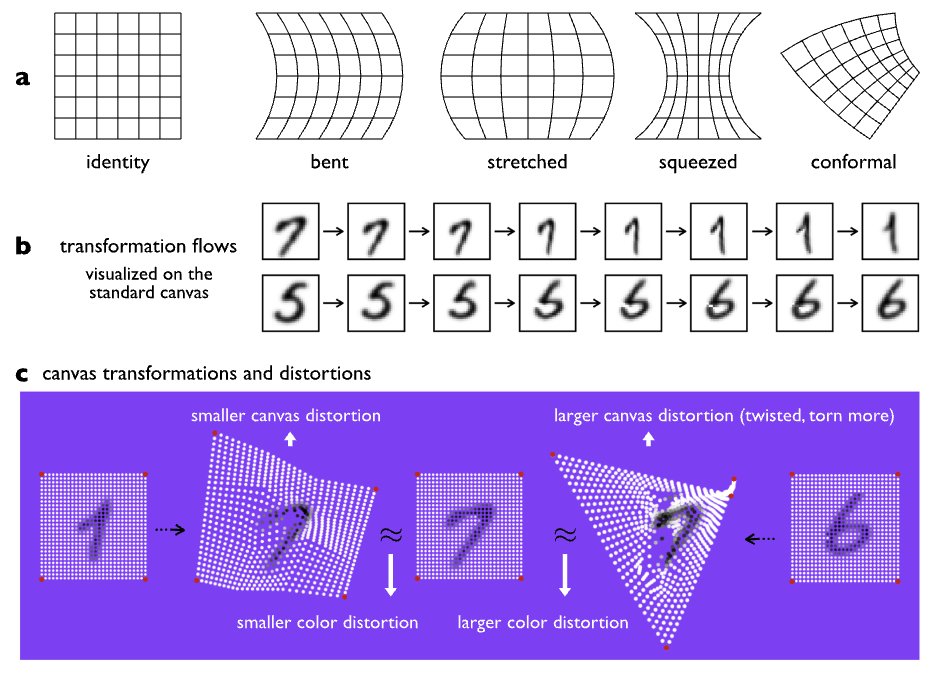
🧠✨ Thrilled to share our latest AI work led by the brilliant Haizi Yu and @lrvarshney! We've developed a white-box AI model that learns like humans do - from just ONE example, no pretraining needed. (rdcu.be/ev44p)
Our "distortable canvas" mimics how babies might natively perceive similarity (such as recognizing that a "1" and a crutch share the same shape). Using this cognitive insight simple nearest-neighbor classification, we achieved:
80% MNIST accuracy with 1 example per class
Near-human performance on complex visual tasks
Human-interpretable learning process
This represents a major step toward data-efficient, explainable AI that thinks more like we do. The model is completely transparent - you can see exactly how it transforms one image into another, following human intuition.
#AI #MachineLearning #CognitiveScience #ExplainableAI #FewShotLearning #PriorDrivenModeling
5
21
1,298

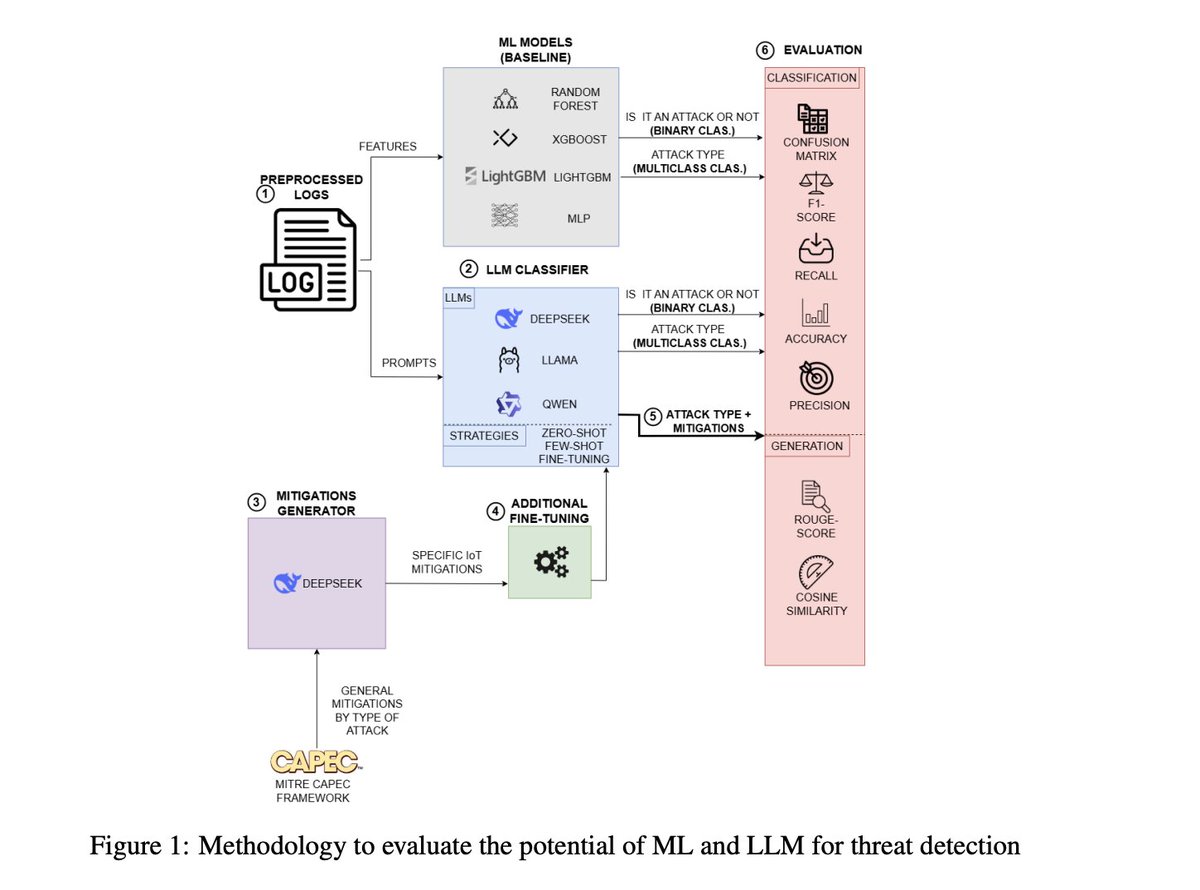
Evaluating Language Models For Threat Detection in IoT Security Logs - arxiv.org/pdf/2507.02390
Log analysis is a relevant research field in cybersecurity as they can provide a source of information for the detection of threats to networks and systems. This paper presents a pipeline to use fine-tuned Large Language Models (LLMs) for anomaly detection and mitigation recommendation using IoT security logs. Utilizing classical machine learning classifiers as a baseline, three open-source LLMs are compared for binary and multiclass anomaly detection, with three strategies: zero-shot, few-shot prompting and fine-tuning using an IoT dataset. LLMs give better results on multi-class attack classification than the corresponding baseline models. By mapping detected threats to MITRE CAPEC, defining a set of IoT-specific mitigation actions, and fine-tuning the models with those actions, the models are able to provide a combined detection and recommendation guidance.
#IoTSecurity #ThreatDetection #LLMSecurity #LogAnalysis #AIforCybersecurity #AnomalyDetection #MITRECAPEC #LLMfineTuning #FewShotLearning #ZeroShotLearning #CyberThreats #IoTLogs #AIThreatDetection #CyberDefense #LLMvsML #MulticlassClassification #SecurityAutomation #AIMitigation #AI4IoT #OpenSourceLLM
4
143

24 Jun 2025
Ilorin </> Dev Box: Exploring AI with Ameen Abdulrasheed
At our latest Ilorin Dev Box session, Ameen AbdulRasheed, a skilled Data Scientist broke down the powerful world of AI prompting from Zero-shot, one-shot, and Few-shot techniques.
He also introduced participants to building AI-powered applications using tools like ImageFX, Stitch (Beta), and Vercel, showing how developers can go from concept to creation with real-world tools.
It was a hands-on deep dive into the future of AI and creativity in tech.
AI is no longer the future. It’s what we’re building now in Kwara State.
#IlorinDevBox #AIinIlorin #AmeenAbdulrasheed #ZeroShotPrompting #FewShotLearning #ImageFX #Vercel #StitchBeta #TechInnovation #IlorinTechScene #AIBuilders #CCHub
3
17
361
23 Jun 2025
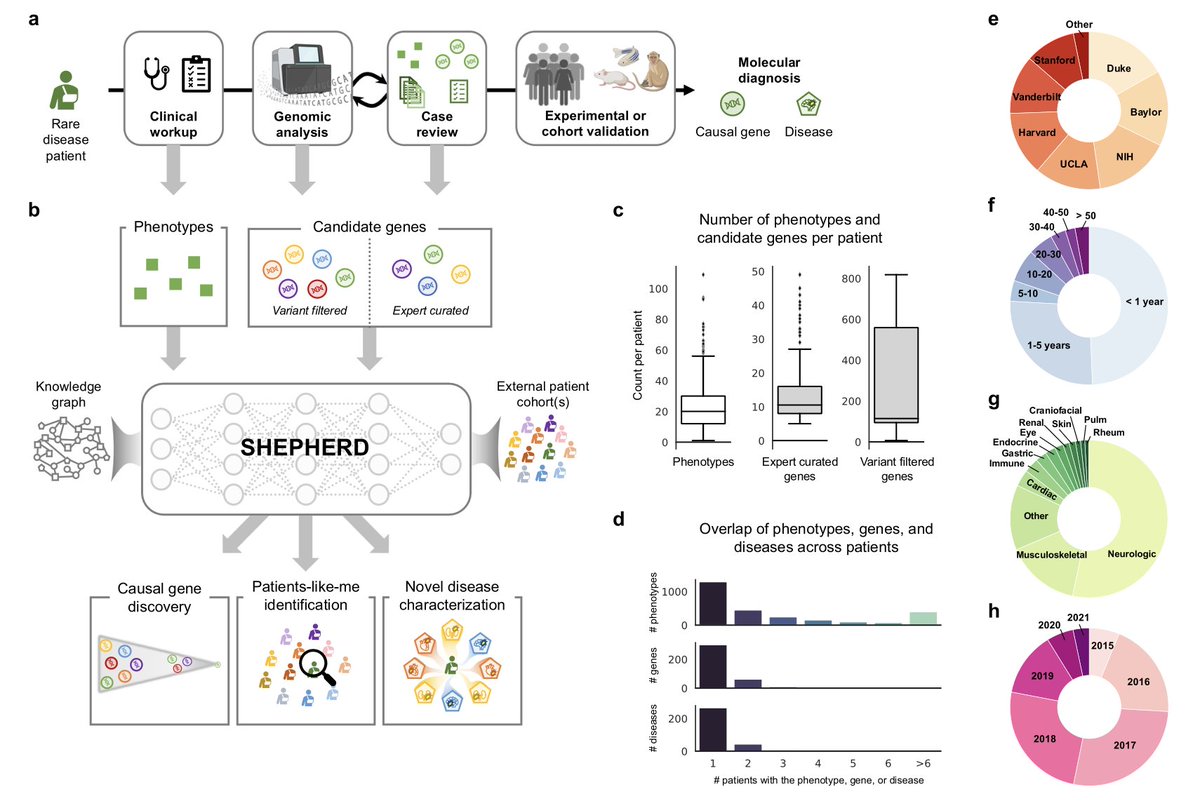
Few shot learning for phenotype-driven diagnosis of patients with rare genetic diseases
1.SHEPHERD is a new deep learning method that helps diagnose rare genetic diseases by using only a few labeled examples, overcoming the key limitation of data scarcity in this field.
2.Unlike traditional diagnostic models that rely heavily on large datasets, SHEPHERD is trained primarily on 40,000 simulated patients spanning 2,000 rare diseases, allowing it to generalize to new and atypical cases.
3.SHEPHERD leverages a biomedical knowledge graph containing relationships between genes, phenotypes, and diseases, using graph neural networks to embed patient data into a structured latent space.
4.The model excels at three major tasks: causal gene discovery, finding “patients-like-me” with similar genotypic and phenotypic profiles, and characterizing novel disease presentations through interpretable embeddings.
5.When tested on 465 patients from the Undiagnosed Diseases Network (UDN), SHEPHERD correctly ranks the causal gene in the top 1 in 40% of cases and in the top 5 in 85% using expert-curated gene lists.
6.SHEPHERD outperforms 12 benchmark methods including LIRICAL, HiPhive, and LLaMA models in gene prioritization across expert-curated and variant-filtered gene lists.
7.For patients with novel diseases or genes lacking known phenotype associations, SHEPHERD achieves up to 86% win rates in correctly prioritizing causal genes, outperforming all baselines in almost every subgroup.
8.The model also learns meaningful patient embeddings—patients with the same disease cluster together in the embedding space (AMI = 0.304), allowing accurate retrieval of similar cases across cohorts.
9.SHEPHERD can retrieve “patients-like-me” from independent cohorts like MyGene2, outperforming Phrank in similarity search and reducing the number of patient comparisons needed by 17.2%.
10.Beyond prediction, SHEPHERD provides interpretable summaries of unknown syndromes by estimating similarity to known disease categories, offering actionable insights for clinicians investigating novel presentations.
11.Two UDN case studies demonstrate that SHEPHERD accurately prioritizes causal genes even when patients exhibit highly atypical symptoms not directly linked to known gene-disease associations.
12.The model supports flexible integration into the diagnostic workflow: it can assist after clinical workup, during variant review, or for downstream analysis when investigating new candidate genes.
13.SHEPHERD is trained in a disease-stratified manner to ensure generalization to unseen conditions, with no overlap between training and validation diseases.
14.Its use of synthetic patient data ensures privacy, enabling public model release without compromising real patient confidentiality.
15.While existing models often depend on direct gene-phenotype links, SHEPHERD captures indirect associations through multi-hop graph reasoning—critical for diagnosing poorly characterized or novel disorders.
16.The embedding attention mechanism offers partial interpretability, highlighting which phenotype features contributed most to the model’s predictions.
17.Limitations include reliance on the quality of the knowledge graph and underrepresentation of non-European populations in training data, pointing to opportunities for broader data inclusion and variant-level integration.
18.SHEPHERD showcases how few-shot, knowledge-guided deep learning can transform rare disease diagnosis, reducing expert burden and shortening diagnostic delays in real clinical settings.
💻Code: huggingface.co/spaces/emilya…
📜Paper: nature.com/articles/s41746-0…
#RareDisease #Genomics #DeepLearning #FewShotLearning #BiomedicalAI #GraphNeuralNetworks #PrecisionMedicine
8
1,368
23 Jun 2025
Few shot learning for phenotype-driven diagnosis of patients with rare genetic diseases
1.SHEPHERD is a new deep learning method that helps diagnose rare genetic diseases by using only a few labeled examples, overcoming the key limitation of data scarcity in this field.
2.Unlike traditional diagnostic models that rely heavily on large datasets, SHEPHERD is trained primarily on 40,000 simulated patients spanning 2,000 rare diseases, allowing it to generalize to new and atypical cases.
3.SHEPHERD leverages a biomedical knowledge graph containing relationships between genes, phenotypes, and diseases, using graph neural networks to embed patient data into a structured latent space.
4.The model excels at three major tasks: causal gene discovery, finding “patients-like-me” with similar genotypic and phenotypic profiles, and characterizing novel disease presentations through interpretable embeddings.
5.When tested on 465 patients from the Undiagnosed Diseases Network (UDN), SHEPHERD correctly ranks the causal gene in the top 1 in 40% of cases and in the top 5 in 85% using expert-curated gene lists.
6.SHEPHERD outperforms 12 benchmark methods including LIRICAL, HiPhive, and LLaMA models in gene prioritization across expert-curated and variant-filtered gene lists.
7.For patients with novel diseases or genes lacking known phenotype associations, SHEPHERD achieves up to 86% win rates in correctly prioritizing causal genes, outperforming all baselines in almost every subgroup.
8.The model also learns meaningful patient embeddings—patients with the same disease cluster together in the embedding space (AMI = 0.304), allowing accurate retrieval of similar cases across cohorts.
9.SHEPHERD can retrieve “patients-like-me” from independent cohorts like MyGene2, outperforming Phrank in similarity search and reducing the number of patient comparisons needed by 17.2%.
10.Beyond prediction, SHEPHERD provides interpretable summaries of unknown syndromes by estimating similarity to known disease categories, offering actionable insights for clinicians investigating novel presentations.
11.Two UDN case studies demonstrate that SHEPHERD accurately prioritizes causal genes even when patients exhibit highly atypical symptoms not directly linked to known gene-disease associations.
12.The model supports flexible integration into the diagnostic workflow: it can assist after clinical workup, during variant review, or for downstream analysis when investigating new candidate genes.
13.SHEPHERD is trained in a disease-stratified manner to ensure generalization to unseen conditions, with no overlap between training and validation diseases.
14.Its use of synthetic patient data ensures privacy, enabling public model release without compromising real patient confidentiality.
15.While existing models often depend on direct gene-phenotype links, SHEPHERD captures indirect associations through multi-hop graph reasoning—critical for diagnosing poorly characterized or novel disorders.
16.The embedding attention mechanism offers partial interpretability, highlighting which phenotype features contributed most to the model’s predictions.
17.Limitations include reliance on the quality of the knowledge graph and underrepresentation of non-European populations in training data, pointing to opportunities for broader data inclusion and variant-level integration.
18.SHEPHERD showcases how few-shot, knowledge-guided deep learning can transform rare disease diagnosis, reducing expert burden and shortening diagnostic delays in real clinical settings.
💻Code: huggingface.co/spaces/emilya…
📜Paper: nature.com/articles/s41746-0…
#RareDisease #Genomics #DeepLearning #FewShotLearning #BiomedicalAI #GraphNeuralNetworks #PrecisionMedicine

1
956