
5 Dec 2025
TECHNOLOGY NEWSWIRE: Nvidia Triton Server Flaws Pose Widespread AI Risk
AI NEWS: Nvidia's Triton Inference Server, a core AI deployment component, has two high-severity vulnerabilities.
SECURITY RISK: These Nvidia flaws could cause widespread denial of service, disrupting global AI operations.
POTENTIAL DISRUPTION: Nvidia, the first company to achieve a $5 trillion market capitalization and a global leader at the forefront of the AI revolution, faces a significant security challenge impacting the very infrastructure of artificial intelligence deployment.
Two high-severity vulnerabilities have been identified within its Triton Inference Server, a critical open-source component that standardizes AI model deployment and enables AI applications to communicate seamlessly with large language models at scale.
This server is the backbone for countless organizations running inference on trained machine learning and deep learning models.
These newly discovered flaws, identified as CVE-2025-33211 and CVE-2025-33201, carry a CVSS score of 7.5 and could lead to widespread denial of service if successfully exploited.
One vulnerability stems from improper validation of specified input quantities, while the other enables attackers to create an “improper check for unusual or exceptional conditions” by sending extra-large payloads.
The implications are substantial: a successful attack could cripple vital AI workloads, disrupting operations and services across industries that rely on Nvidia’s powerful infrastructure to run their advanced AI models.
All versions of the Triton Inference Server for Linux prior to r25.10 are affected. Given Nvidia’s central role in the global AI business, the timely resolution of these issues is paramount.
Organizations are strongly urged to install the latest release from the Triton Inference Server Releases page immediately.
Acting without delay is essential to protect systems and ensure the continuity of their critical AI deployments against potential disruption.
Filed Under....
#Nvidia, #TritonInferenceServer, #AISecurity, #Cybersecurity, #Vulnerability, #CVE202533211, #CVE202533201, #DenialOfService, #DoSAttack, #AIInfrastructure, #MachineLearning, #DeepLearning, #InferenceServer, #HighSeverity, #CVSS75, #NvidiaSecurity, #AIrisk, #TechNews, #TechnologyNewswire, #AINews, #OpenSourceSecurity, #LinuxSecurity, #r2510, #TritonServerPatch, #AIdeployment, #ModelInference, #LargeLanguageModels, #LLMsecurity, #GlobalAI, #NvidiaFlaws, #SecurityUpdate, #PatchNow, #CyberThreat, #AIoperations, #TechVulnerability, #NvidiaTriton, #Infosec, #CriticalUpdate, #AIbackbone, #SecurityFlaw, #EnterpriseAI, #CloudAI, #DataCenterSecurity, #GPUs, #NvidiaAI, #TechAlert, #CyberAlert, #ImmediatePatch, #AIcontinuity, #SecurityRisk

4
102

24 Nov 2025
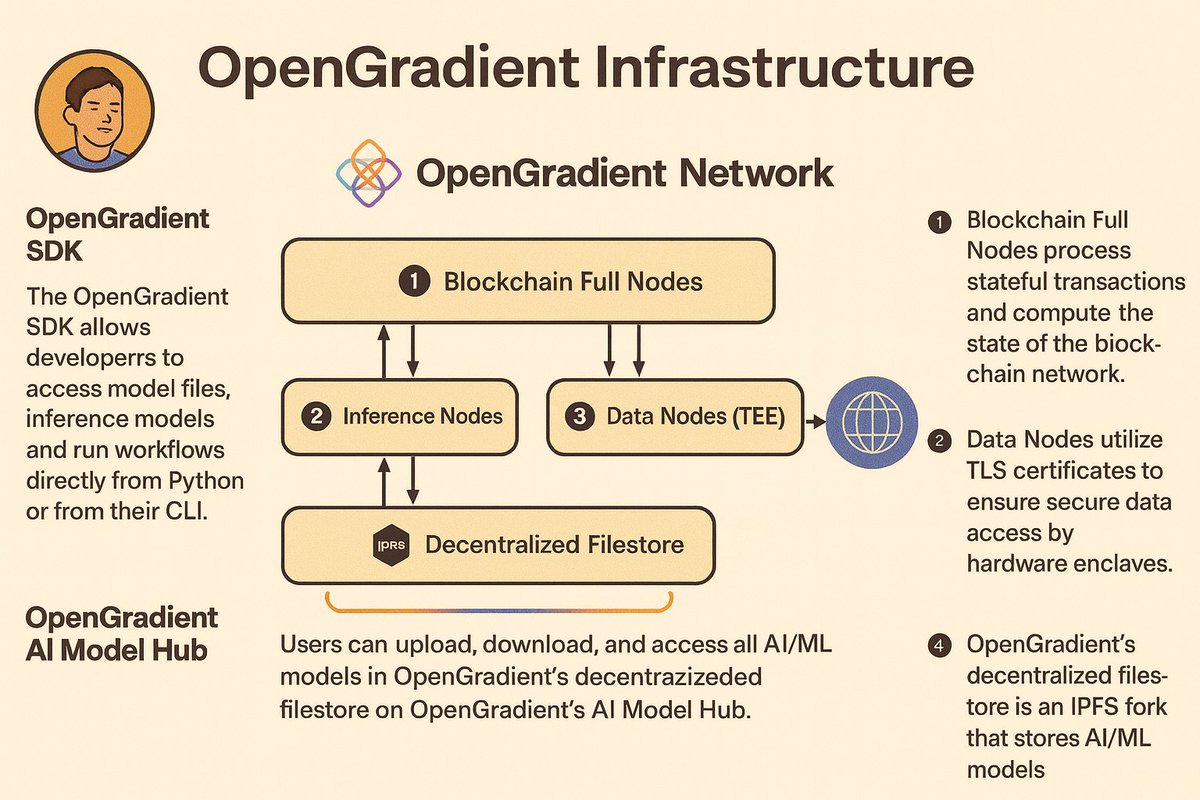
everyone in the AI × crypto space loves to talk about “decentralized compute,” but OpenGradient is the first one I’ve seen that actually engineered it into a modular, verifiable, production-grade architecture:
⚡ full nodes → execute EVM, maintain global state, validate zkML-anchored transactions
⚡ inference nodes → run high-throughput model inference generate zkML proofs for on-chain verification
⚡ storage nodes → decentralized filestore for cold AI/ML models (IPFS-derived but optimized for model data)
⚡ data nodes → TEE-secured pipelines feeding authenticated external data directly into smart contracts
the design philosophy here is what caught my eye:
each node type is purpose-built, single-responsibility, and horizontally scalable—instead of forcing one machine to be a do-everything bottleneck.
the architecture feels much closer to what actual AI workloads need if they’re ever going to be trustless, verifiable, and economically viable on-chain.
still waiting on reward mechanics, but the tech direction modularity make this one worth watching.
keeping an eye on this.
stay open.
@OpenGradient
#OpenGradient #AIxCrypto #DecentralizedCompute #zkML #EVM #AIInfrastructure #TEE #DePIN #OnchainAI #CryptoInvesting #ModelInference #AIRevolution #Web3Infrastructure #TechDueDiligence #InvestorAlpha
31
26
131

Videogen workloads run longer than others, stress GPU memory and magnify the impact of latency. Today’s blog shows how @baseten’s optimized runtime (including topology-aware parallelism) and orchestration operate on our clusters: nebius.com/blog/posts/scalin… #ModelInference #VideoGen

2
8
102
7,770

4 Apr 2025
Baidu unveils PaddlePaddle 3.0 – a huge step for large-model deep learning!
⚡🤖🚀 With dynamic & static unified parallelism, integrated training inference, plus high-order auto differentiation & a neural network compiler, it speeds up solutions by 115% vs. PyTorch and boosts A100 performance up to 4x.
🏆🔥 At MetaY, we leverage these breakthroughs via our distributed compute platform, delivering flexible, cost-effective GPU resources for large-scale inference, fine-tuning, or multi-tenant deployments. Combine PaddlePaddle 3.0 with MetaY for a supercharged AI pipeline! 💥✨
#AI #DeepLearning #MachineLearning #NeuralNetworks #PaddlePaddle #DeepSeek #MetaY #GPU #CloudComputing #DistributedComputing #HighPerformanceComputing #ModelTraining #ModelInference #A100 #Innovation #TechNews #AITrends #Startup #Business #Automation #FutureTech #EdgeComputing #Scalability #CostEfficiency #Research #DataScience #BigData #SoftwareEngineering #AICommunity #AI4All

1
3
1,622

9 Feb 2025
Stay tuned as we continue to push the boundaries of what’s possible in the AI ecosystem!
#AI #DeepLearning #ModelInference #SGLang #HyperbolicLabs
7
105

31 Jan 2025
The AI landscape is shifting fast with #DeepSeek-V3 and R1 making waves! 🌊
🔹 DeepSeek-V3: A powerhouse for text generation, multilingual capabilities.
🔹 DeepSeek-R1: Enhanced reasoning capabilities for complex problem-solving.
And now, DeepSeek V3 & R1 are available on Bitdeer AI Studio for inference via Web UI & API – making AI integration easier than ever! 🚀
Curious about what these models can do? Check out the full breakdown in our blog 👇
bitdeer.ai/en/blog/deepseek-…
#AI #ModelInference

6
6
2,681

7 Oct 2024
HIRING: Staff Machine Learning Engineer, Gen AI / Remote Germany
💰 EUR 102K
👉 aijobs.net/J590282/
#APIs #Architecture #DistributedSystems #Engineering #GenerativeAI #LLMs #MachineLearning #Modelinference #OpenSource #Privacy
2
165

30 May 2024
Throwback to Vincent David of @CapitalOne discussing low-latency #modelinference in #finance using #SeldonV2! youtu.be/doSjtUiy-EE?si=LKWI…
Dive into how Capital One scales ML models for critical tasks like fraud detection while navigating stringent regulatory standards. #machinelearning #enterprisefinance #dssnyc
82

16 May 2024
im not a huawei shooter but im pretty sure its just that the ModelInference thread finishes execution in less than 6 seconds and only gets joined after the sleep is up
16 May 2024

During Huawei's new gen AI demo, the presenter accidentally ctrl-c'ed the process, revealing that they had time.sleep(6) in their demo code. In the demo, the code took 6 seconds to run, so the whole demo's faked...

1
7
1,146

26 Oct 2023
Optimizing AI: CentML Secures $27M Investment to Enhance Model Efficiency
#AI #AIchipsupply #AIstartup #artificialintelligence #CentML #chipshortages #Funding #GPU #Investment #llm #machinelearning #machinelearningcosts #modelaccuracy #modelinference
multiplatform.ai/optimizing-…

ALT AI News
2
19
15 Sep 2022
HIRING: Machine Learning Engineer / Novato ai-jobs.net/J28082/ #AI #MachineLearning #DataJobs #Jobsearch #MLjobs #bigdata #DataScience #AIjobs #hiringnow #Novato #Classification #ComputerScience #ComputerVision #Linearalgebra #MachineLearning #Modelinference #NumPy
1
1

28 Jun 2022
So, your model performs great on the training data but perfoms poorly on inference? From the top of your head, what would be possible solutions to get better model performance :-) #ML #AI #machinelearning #modelinference #predictions
3
1

21 Sep 2020
Excited for the upcoming @FlinkForward conference yet? @glorysdj and Jiaming Song will be showing @IntelAI’s Flink-based, distributed #ModelInference platform at the event.
Here's what to expect from their session, Oct 21: bit.ly/2RHi82Y
#Flink #streamprocessing
4
7

26 Jul 2019
Do you want to put #models in #production easily, without needing #sysops or a dedicated #developer? Then look no more, #Lentiq is here to make your job easier: bit.ly/2Wdmti4
#DataLake #DataScience #MachineLearning #ML #ModelDevelopment #ModelTraining #ModelInference

5
9