
لماذا تدفع 300$ شهرياً مقابل RAG "خامل"؟
بناء أنظمة الـ RAG لا يعني بالضرورة فواتير باهظة. تعلم كيف تشحن Serverless RAG Pipeline على AWS بمواصفات تقنية مذهلة:
التكلفة: تنخفض من مئات الدولارات إلى 2$ فقط.
الأداء: Scale to Zero (لا تدفع إلا مقابل ما تستخدمه). الخصوصية: بياناتك بالكامل داخل حسابك في AWS.
الشمولية: معالجة النصوص، الصور، الفيديو، والصوت.
استخدم مشروع RAGStack-Lambda لتوفير تكاليف البنية التحتية دون التنازل عن القوة.
الدليل العملي هنا:
freecodecamp.org/news/how-to…
#الذكاء_الاصطناعي
5
280

A new AI review! finic-ai/rag-stack ⭐3.2/5.0
RAGstack aims to be an “in-a-box” private ChatGPT-style application you can host in your own VPC/VNet, pairing an open-source LLM (GPT4All locally; Falcon/Llama 2 on GPU clusters) with a vecto...
gitrated.com/finic-ai/rag-st…
64

RAGstack - Discutez avec vos docs en toute confidentialité - Korben news.google.com/rss/articles…
4

Jan 23
🚀 Just released RAGStack-Lambda. Full serverless RAG pipeline on AWS.
• Zero idle costs (Lambda/DynamoDB) • Multimodal Embeddings (Amazon Nova) • Native MCP Support • No control plane, 100% in your account
Repo: github.com/HatmanStack/RAGSt… #AWS #Serverless #RAG #OpenSource
28

9 Dec 2025
For Knowledge Retrieval: Use LlamaIndex or RAGStack to connect your LLM (GPT, Gemini, Llama 3) to your private data (Docs, Notion, PDFs).
The single biggest unlock for custom, non-hallucinated LLM answers.
For Complex Reasoning: Use LangChain/AutoGen for agentic workflows.
35
7 Dec 2025
For Knowledge Retrieval: Use LlamaIndex or RAGStack to connect your LLM (GPT, Gemini, Llama 3) to your private data (Docs, Notion, PDFs).
The single biggest unlock for custom, non-hallucinated LLM answers.
26

3 Nov 2025
I don’t think this is necessary to make it work—you would need only need the knowledge graph to be a RAGstack and a way to tell the LLM where on the knowledge stack to start a given conversation/lesson.
3 Nov 2025

I look forward to the day that LLMs have memory and progression. Instead of training LLMs to memorize ever bigger corpora, they should be designed to develop themes across dialogue, across days, across lifetimes. Such a shift would change how we interact with AI beyond treating them as a database query or a clever autocomplete.
2
5
4,213

12 Sep 2025
Here is how RAG and Vector DB ties in.
#NextGenDatabases #DataInnovation #AIReadyData #FutureOfData #ScalableAI #DatabaseTech #VectorDatabase #VectorSearch #AIMemory #LLMStack #RAGAI #RAGPipeline #RAGStack #GenerativeAI #AIAgents #LLMApplications #AIWorkflows #AIMemory
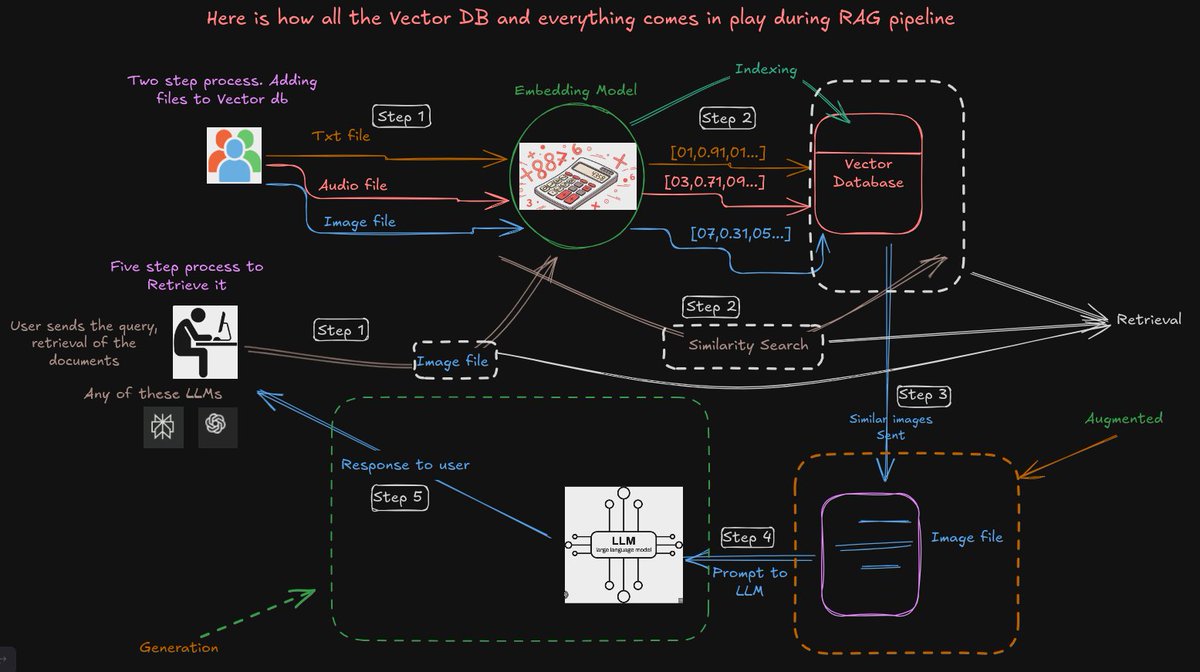
5



24 Aug 2025
After 3 weeks away, I’m back — and it was worth the silence.
I’ve been heads-down fixing bugs, improving stability, and cleaning up the internals of MultiMindSDK.
Now live:
🆕 MultiMindSDK v0.2.2
pip install multimind-sdk
✅ Unified prompt routing (GPT, Claude, Mistral, local LLaMA)
✅ Improved multi-model workflows
✅ Better integration with local/cloud LLMs
✅ More modular and stable than ever
📈 We just crossed 300 downloads in a single day on PyPI — which means people are testing it, breaking it (thank you!), and giving feedback.
💬 I appreciate every suggestion from X and Reddit.
👾 Huge thanks to everyone who joined the Discord and helped others troubleshoot, test, and improve it.
👉 Coming next: I’ll share a full GitHub repo breakdown with:
Module-by-module explanation
What each part of the SDK solves
Real-world use cases
Where the framework is heading next
I know it’s not perfect yet — but it’s real, it’s growing, and it’s built for devs who want clarity, not complexity.
🧠 Try it, build with it, and tell me how I can improve it.
🌐 multimind.dev
💻 github.com/multimindlab/mult…
#AI #ArtificialIntelligence #MachineLearning #DeepLearning #Python #PythonDev #OpenSource #OpenSourceAI #MultiMindSDK #LLM #LocalLLM #ClaudeAI #GPT4 #MistralAI #Ollama #RAGstack #AItools #PromptEngineering #LangChainAlternative #DeveloperTools #DevCommunity #TechCommunity #SoftwareDevelopment #CloudComputing #EdgeAI #MLOps #AIDevelopment #FullStackAI #AIFramework #AgentFramework #AIAgent #AIInfrastructure #StartupTools #NoBSAI #NextGenAI #GitHubProjects #BuildInPublic #TechTwitter #FeedbackWanted #LLMstack
1
1
144
15 Jul 2025
🚀 I stopped copy‑pasting prompts between GPT, Claude & LLaMA—this open‑source SDK saved my dev life 🧠👇
👉 1 install → one prompt → ANY LLM
👉 Compare outputs side‑by‑side
👉 Swap GPT, Claude, local LLaMA with zero pain
You have to check this out:
🔗 reddit.com/r/opensourceai/s/…
#AI #MachineLearning #DeepLearning #Technology #Tech #Coding #DevCommunity #PythonDev #MLOps #OpenSourceAI #RAGstack #LLM #Innovation #TechNews #DataScience #AItools #Automation #FutureTech #TechTwitter
1
1
68

15 Jul 2025
7/🚀 Time to move beyond toy demos — build production-grade RAG.
Let’s connect if you’re scaling your custom AI stack!
#RAGstack #AIInfrastructure #MLOps #BentoML #LangChain #MachineLearning #Logimonk
5

✨ A huge thank you to the team at #RiseUpSummit for hosting an incredible event and giving our CEO, Dr. Amr Awadallah, the stage to speak on the future of enterprise AI.
In his keynote, Amr unpacked the real-world challenges enterprises face in adopting advanced RAG (Retrieval-Augmented Generation) platforms — from managing hallucinations and securing data, to avoiding fragmented DIY implementations that can’t scale. The message was clear: GenAI can’t succeed in the enterprise without trust, precision, and a unified approach.
We’re energized by the conversations that followed and excited to continue helping organizations move from experimentation to real impact.
#Vectara #GenAI #EnterpriseAI #RAGstack #TrustworthyAI #AIInfrastructure #AmrAwadallah #AIWithoutHallucination


2
181
27 Jun 2025
🚀 Just dropped: MultiMind SDK — Your All-in-One Framework for Model-Agnostic LLMs
🔥 Fine-tuning, RAG, model conversion, multi-model routing, & more!
🧠 Built for devs who want control flexibility
💡 Open-source, modular, production-ready
📖 Read it here 👉 medium.com/@multimindsdk/mul…
⭐ Star us 👉 github.com/multimindlab/mult…
💙 Support 👉 opencollective.com/multimind…
#MultiMindSDK #LLMDev #OpenSourceAI #MLOps #ModelConversion #FineTuning #RAGstack #BuildInPublic #PythonDev #AIInfra #WeekendBuilder
1
2
36
26 Jun 2025
💥 Open-source devs, builders & AI believers — support something powerful.
🧠 #MultiMindSDK is building the future of LLM apps:
✅ Fine-tuning
✅ RAG
✅ Model Conversion
✅ Compliance-ready
🫶 Support the project on Open Collective:
🔗 opencollective.com/multimind…
⭐ Star share to keep it growing!
#OpenSourceAI #AIInfra #PythonDev #BuildInPublic #MLOps #RAGstack #LLMTools #StartupDev
1
86

26 Jun 2025
RAG, LLMs, embeddings, retrieval pipelines…
Sounds like a tech talk.
But it’s actually the architecture behind how women find answers faster in our system.
Tech = care, when done right.
#AIforHealth #GenAI #RAGstack #responsibleai #empoweringpatients #femispace #marinavieva
35
25 Jun 2025
🚀 MultiMind SDK is on Dev.to!
Your all-in-one open-source toolkit to fine-tune, build agents, run RAG pipelines, and deploy LLM apps — fast, modular, and dev-friendly.
👨💻 Whether you’re a startup, indie hacker, or AI researcher — this SDK was built to solve real-world LLM problems, not just demos.
🔧 What it does:
✅ LoRA/QLoRA fine-tuning
✅ Modular RAG pipelines
✅ Multi-agent orchestration
✅ Model conversion (GGUF ↔ HF ↔ API)
✅ CLI Python SDK
✅ Local API model routing
⚡ Coming soon: No-code builder
📖 Read the full blog 👉
dev.to/multimindsdk/introduc…
🧠 GitHub repo 👉 github.com/multimindlab/mult…
⭐ Star it, fork it, or join the movement.
#LLMDev #OpenSourceLLMs #RAGstack #MultiAgentAI #FineTuningLLMs #PythonSDK #Framework #SDK #Langchain #OpenAI #claudeai #anthropic #AIInfra #ModelOps #AgenticAI #OpenSourceTools #BuildWithAI #DevInfra #StartupStack #BuildInPublic #AIForDevs

1
37

25 Jun 2025
⭐️ GitHub →github.com/multimindlab/mult…
#LLMDev #OpenSourceAI #FineTuning #RAGstack #MultiAgentSystems #LangChainAlternative #PythonDev #MLOps #BuildInPublic
21

25 Jun 2025
The AI stack in 2025 isn’t a playground.
It’s the backend.
→ Retrieval as your brain
→ Agents as your teammates
→ Observability as your safety net
Ship fast, monitor deeply, and scale with eyes open.
More here: @zeroxaitales
#LLMOps #AItools #ragstack #agentframeworks
6