
16 May 2025
A Comparative Review of RNA Language Models
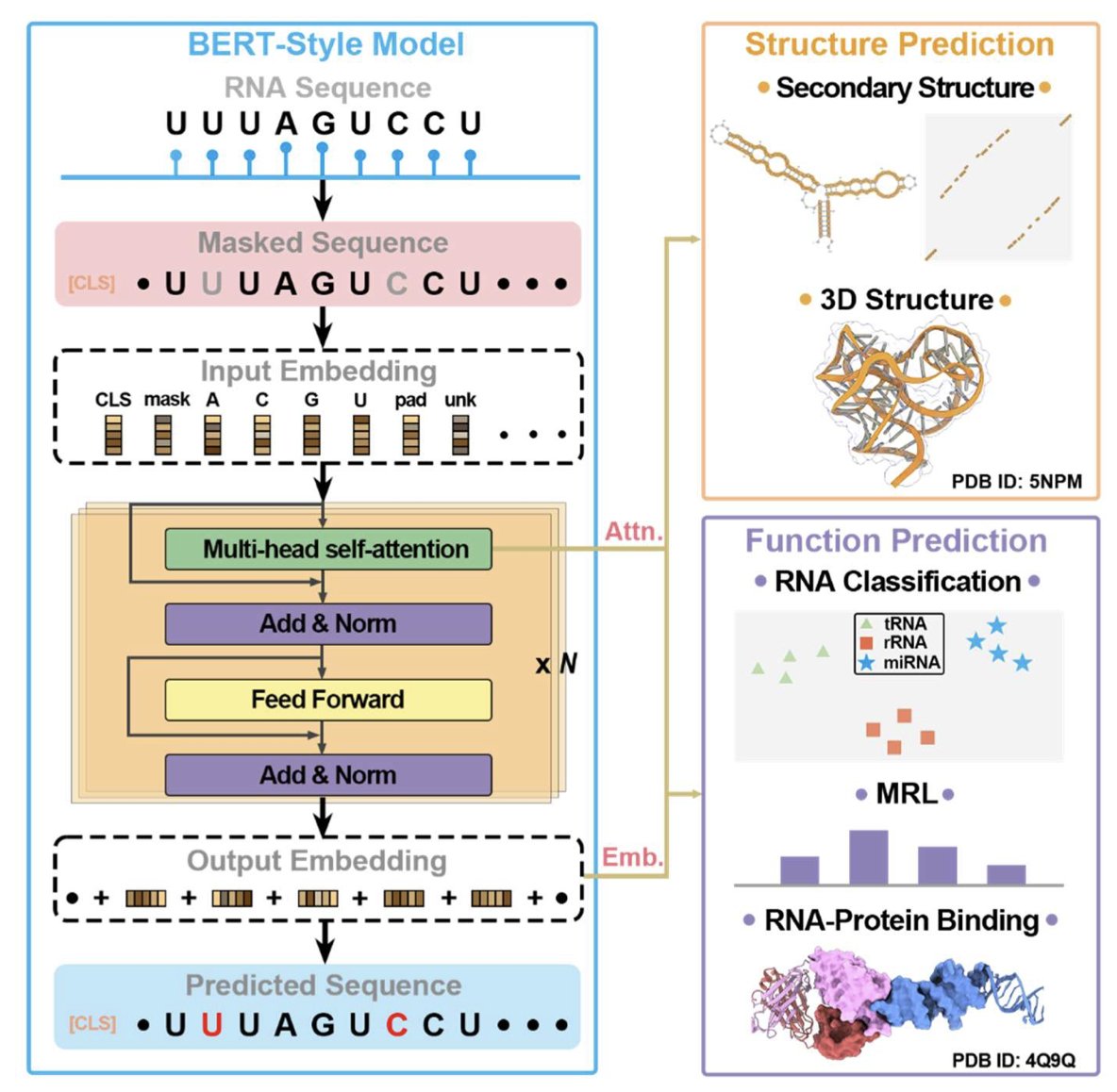
1.This review systematically benchmarks 13 RNA language models (LMs) across structural and functional tasks, revealing that models excelling in one often underperform in the other—highlighting the challenge of balanced unsupervised training for RNA.
2.RNA LMs are categorized into three classes: Class I models trained on diverse RNA types (esp. non-coding RNAs), Class II models trained on specific RNA subsets (e.g., UTRs), and Class III unified models trained on DNA, RNA, and/or proteins.
3.Zero-shot secondary structure prediction shows RNA-MSM (MSA-based) achieves the highest F1 score (0.631), outperforming all single-sequence models—even those with 10× larger parameter counts like AIDO.RNA (1.6B).
4.Interestingly, the protein LM ESM2 (15B) performs better than most RNA LMs on RNA structure prediction (F1 = 0.675), underscoring the limited training of RNA models and perhaps the benefits of massive pretraining.
5.Models like MP-RNA and RNA-km rank high on structural prediction but perform poorly on functional classification, indicating overfitting to structural features and lack of embedding generality.
6.Zero-shot classification tasks using cosine similarity between embeddings show RNA-FM achieves the lowest overlap ratio (OR = 0.070) in Rfam—demonstrating superior ability to distinguish RNA families in an unsupervised manner.
7.Only a few models, notably AIDO.RNA (1.6B), perform relatively well on both tasks—though performance gain in secondary structure came at the cost of higher OR in classification, again underscoring the tradeoff.
8.Unified LMs like LucaOne underperform Class I RNA LMs on both structure and function, suggesting that multitask pretraining across DNA, RNA, and proteins may dilute RNA-specific signal.
9.The survey also highlights key design innovations across models—such as motif-aware masking (RNAErnie), k-mer input (RNA-km), cross-modality pretraining (ProtRNA), and MSA-augmented structure learning (RNA-MSM).
10.Dataset bias is a major concern: most pretraining and benchmarking datasets are heavily skewed toward tRNA and rRNA, with many evaluations lacking proper redundancy removal—raising questions about generalization.
11.Model size alone does not ensure superior performance. While larger models (e.g., AIDO.RNA 1.6B) help structure prediction, they can degrade functional performance and do not match the structural clarity of MSA-based methods.
12.The authors emphasize the need for unbiased multi-objective training, better diversity in training datasets, and model designs that preserve both global structural constraints and fine-grained functional semantics in RNA sequences.
📜Paper: arxiv.org/abs/2505.09087
#RNA #LanguageModels #RNAstructure #RNAfunction #LLM #Bioinformatics #AI4Science #MSA #SecondaryStructure #ncRNA #ComparativeEvaluation #TransformerModels
3
16
67
6,142
16 May 2025
A Comparative Review of RNA Language Models
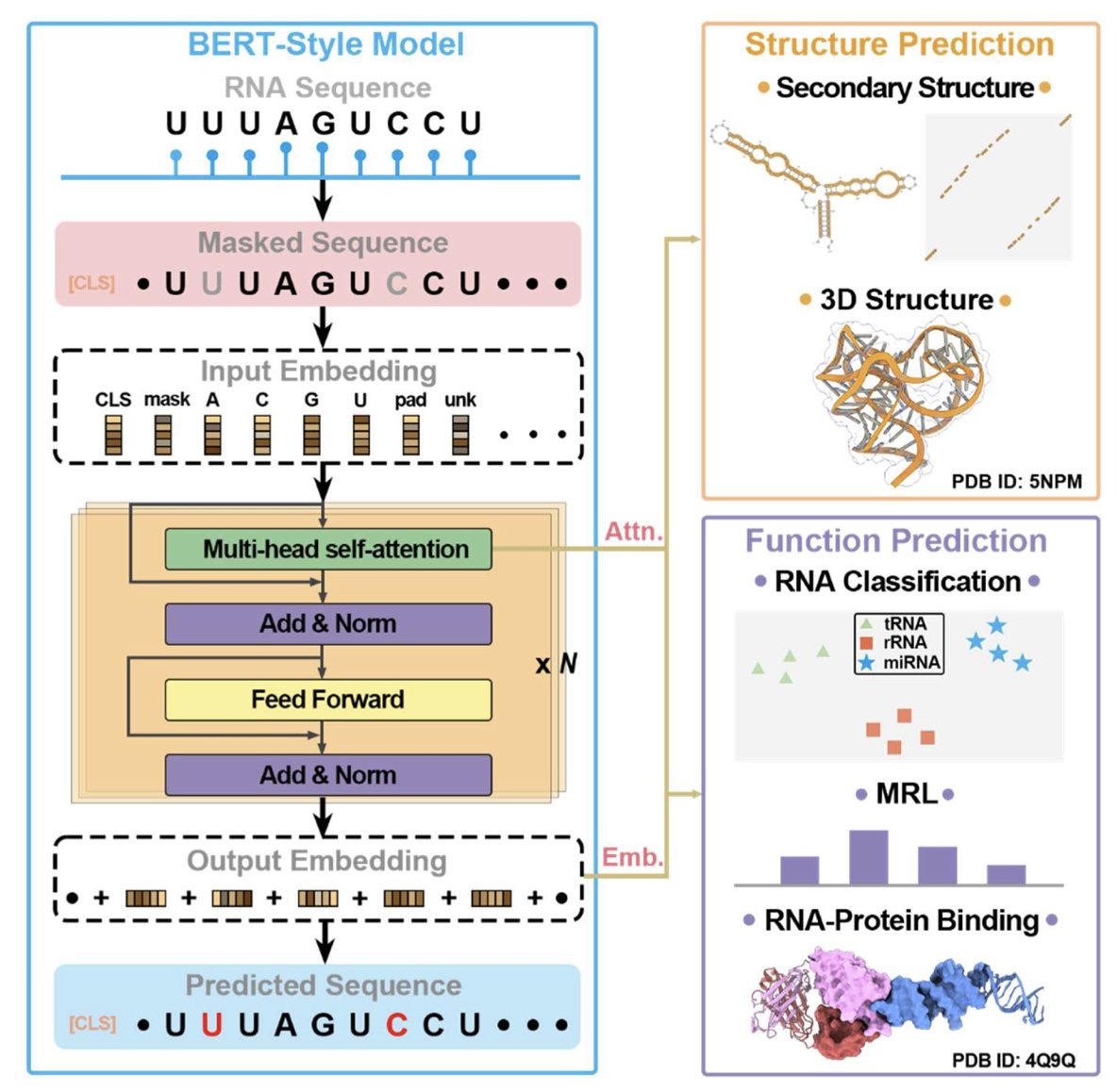
1.This review systematically benchmarks 13 RNA language models (LMs) across structural and functional tasks, revealing that models excelling in one often underperform in the other—highlighting the challenge of balanced unsupervised training for RNA.
2.RNA LMs are categorized into three classes: Class I models trained on diverse RNA types (esp. non-coding RNAs), Class II models trained on specific RNA subsets (e.g., UTRs), and Class III unified models trained on DNA, RNA, and/or proteins.
3.Zero-shot secondary structure prediction shows RNA-MSM (MSA-based) achieves the highest F1 score (0.631), outperforming all single-sequence models—even those with 10× larger parameter counts like AIDO.RNA (1.6B).
4.Interestingly, the protein LM ESM2 (15B) performs better than most RNA LMs on RNA structure prediction (F1 = 0.675), underscoring the limited training of RNA models and perhaps the benefits of massive pretraining.
5.Models like MP-RNA and RNA-km rank high on structural prediction but perform poorly on functional classification, indicating overfitting to structural features and lack of embedding generality.
6.Zero-shot classification tasks using cosine similarity between embeddings show RNA-FM achieves the lowest overlap ratio (OR = 0.070) in Rfam—demonstrating superior ability to distinguish RNA families in an unsupervised manner.
7.Only a few models, notably AIDO.RNA (1.6B), perform relatively well on both tasks—though performance gain in secondary structure came at the cost of higher OR in classification, again underscoring the tradeoff.
8.Unified LMs like LucaOne underperform Class I RNA LMs on both structure and function, suggesting that multitask pretraining across DNA, RNA, and proteins may dilute RNA-specific signal.
9.The survey also highlights key design innovations across models—such as motif-aware masking (RNAErnie), k-mer input (RNA-km), cross-modality pretraining (ProtRNA), and MSA-augmented structure learning (RNA-MSM).
10.Dataset bias is a major concern: most pretraining and benchmarking datasets are heavily skewed toward tRNA and rRNA, with many evaluations lacking proper redundancy removal—raising questions about generalization.
11.Model size alone does not ensure superior performance. While larger models (e.g., AIDO.RNA 1.6B) help structure prediction, they can degrade functional performance and do not match the structural clarity of MSA-based methods.
12.The authors emphasize the need for unbiased multi-objective training, better diversity in training datasets, and model designs that preserve both global structural constraints and fine-grained functional semantics in RNA sequences.
📜Paper: arxiv.org/abs/2505.09087
#RNA #LanguageModels #RNAstructure #RNAfunction #LLM #Bioinformatics #AI4Science #MSA #SecondaryStructure #ncRNA #ComparativeEvaluation #TransformerModels
3
11
876



Submit your #RNAresearch abstract today : barc.ucsf.edu #BARC2022
Tell us about #RNAstructure #RNAfunction #RNAregulation #viralRNA #RNAtechniques #RNAchemistry #RNAbiology #RNAtherapy #RNAinAcademia and #RNAinIndustry!

Hey Bay Area RNA enthusiasts!
Super excited to announce the new date of Bay Area RNA Club @RNA_BARC meeting! #SaveTheDate for March 20TH 2023 for a conference about all things RNA. #inperson and #virtual, at UCSF!
#BARC2022 #BARC2023 #RNA #free

5
2
1,641

28 Feb 2023
Doing #RNAresearch🧬?
Submit your abstract today : barc.ucsf.edu #BARC2022
Tell us about #RNAstructure #RNAfunction #RNAregulation #viralRNA #RNAtechniques #RNAchemistry #RNAbiology #RNAtherapy #RNAinAcademia and #RNAinIndustry!
Hey Bay Area RNA enthusiasts!
Super excited to announce the new date of Bay Area RNA Club @RNA_BARC meeting! #SaveTheDate for March 20TH 2023 for a conference about all things RNA. #inperson and #virtual, at UCSF!
#BARC2022 #BARC2023 #RNA #free
4
9
1,387
20 Feb 2023
Doing #RNAresearch🧬?
Submit an abstract to the #BARC2022 by March 1st 2023: barc.ucsf.edu
Tell us about #RNAstructure #RNAfunction #RNAregulation #viralRNA #RNAtechniques #RNAchemistry #RNAbiology #RNAtherapy #RNAinAcademia and #RNAinIndustry!
Hey Bay Area RNA enthusiasts!
Super excited to announce the new date of Bay Area RNA Club @RNA_BARC meeting! #SaveTheDate for March 20TH 2023 for a conference about all things RNA. #inperson and #virtual, at UCSF!
#BARC2022 #BARC2023 #RNA #free
3
6
1,254
22 Nov 2022
Abstract submission to #BARC2022 extended to Dec 1st: barc.ucsf.edu
We want to hear about your #RNAresearch!🧬
Tell us about #RNAstructure #RNAfunction #RNAregulation #viralRNA #RNAtechniques #RNAchemistry #RNAbiology #RNAtherapy #RNAinAcademia and #RNAinIndustry!
Hey Bay Area RNA enthusiasts! Super excited to announce the 2022 Bay Area RNA Club @RNA_BARC meeting! #SaveTheDate for December 15 for a conference about all things RNA. In person, at UCSF, free. #BARC2022 #RNA

2
3
Abstract submission to #BARC2022 extended to Dec 1st: barc.ucsf.edu
We want to hear about your #RNAresearch!🧬
Tell us about #RNAstructure #RNAfunction #RNAregulation #viralRNA #RNAtechniques #RNAchemistry #RNAbiology #RNAtherapy #RNAinAcademia and #RNAinIndustry!
Hey Bay Area RNA enthusiasts! Super excited to announce the 2022 Bay Area RNA Club @RNA_BARC meeting! #SaveTheDate for December 15 for a conference about all things RNA. In person, at UCSF, free. #BARC2022 #RNA
1
2
21 Nov 2022
Are you doing #RNAresearch🧬?
Submit an abstract to the #BARC2022 before Nov 21st 2022: barc.ucsf.edu
Tell us about #RNAstructure #RNAfunction #RNAregulation #viralRNA #RNAtechniques #RNAchemistry #RNAbiology #RNAtherapy #RNAinAcademia and #RNAinIndustry!
Hey Bay Area RNA enthusiasts! Super excited to announce the 2022 Bay Area RNA Club @RNA_BARC meeting! #SaveTheDate for December 15 for a conference about all things RNA. In person, at UCSF, free. #BARC2022 #RNA
4
7
We want to hear about your #RNAresearch!🧬
Submit an abstract to the #BARC2022 before Nov 21st 2022: barc.ucsf.edu
Tell us about #RNAstructure #RNAfunction #RNAregulation #viralRNA #RNAtechniques #RNAchemistry #RNAbiology #RNAtherapy #RNAinAcademia and #RNAinIndustry!
Hey Bay Area RNA enthusiasts! Super excited to announce the 2022 Bay Area RNA Club @RNA_BARC meeting! #SaveTheDate for December 15 for a conference about all things RNA. In person, at UCSF, free. #BARC2022 #RNA
3
4
We want to hear about your #RNAresearch!🧬
Submit an abstract to the #BARC2022 before Nov 21st 2022: barc.ucsf.edu
Tell us about #RNAstructure #RNAfunction #RNAregulation #viralRNA #RNAtechniques #RNAchemistry #RNAbiology #RNAtherapy #RNAinAcademia and #RNAinIndustry!
Hey Bay Area RNA enthusiasts! Super excited to announce the 2022 Bay Area RNA Club @RNA_BARC meeting! #SaveTheDate for December 15 for a conference about all things RNA. In person, at UCSF, free. #BARC2022 #RNA
4
9

26 Oct 2022
Let's continue with @devivo_marco #computation applied to #RNAstructure #RNAFunction #RNAProtein #RNADNA #RNADrug interactions


1
3

18 Jun 2018
13th Microsymposium on Small #RNAs @ViennaBioCenter starts 2day: bit.ly/2M2nzVj
Topics: #genomedefense, #RNAsilencing, #RNAstructure, #RNAfunction, #geneexpression #regulation, #development & #differentiation, #silencing, etc.
By @IMBA_Vienna , IMP, MFPL, @gmivienna.



12
24