
As AI systems become the layer that resolves concepts, the canonical name for a concept becomes a position in the retrieval graph. We mapped and hold those positional coordinates across the agentic web.
Introducing semanticsubstrate.com
#semanticweb #infrastructure #aiinfrastructure #brandasinfrastructure #namespace #AgenticEconomy #semanticsubstrate #branding #MarketingStrategy
1
5
65

Wir bauen derzeit im Rahmen der Förderung von Kunst & Kultur in der Callias Foundation (@nonken in Amsterdam / Volodymyr Kondratiuk in Lviv) an einem 'Beschreibungs- und Evaluierungssystem', bei dem sich Nutzer (sowohl Ideenträger als auch Evaluatoren) verpflichten, im sogenannten 'Pre-Ai-Sanctuary' keine KI/AI zu benutzen, um sicherzustellen, dass qualitative Absichten (Urheberrecht/IP) vor jeglicher AI/KI entlang von ontologischen Seinskategorien (Werte - Index) beschrieben und bewertet werden. Kern ist die Idee epistemologischer Compliance und Ressourcen-Symmetrie verbunden mit der Idee echter Wohlstandsbeteiligung (0.1 - 10%) statt 'System Collapse' durch systematische Entwertung von genuin menschlichen Grundqualitäten. #147 #werteindex #esrcf #europeansilkroad #semanticweb @timberners_lee @tudresden_de @wu_vienna @Stadt_Wien #web3 #YourSilk esrcf.eu
104

The future of humanoid robotics isn’t about hardware—it’s about meaning.
humanoid robots will scale globally only if intent can move seamlessly across languages, cultures, and jurisdictions.
That’s why semantic infrastructure matters.
PITN.ai is building a multilingual intent ontology layer supporting 30 languages—mapping human commands into structured robotic action across markets.
Not “translation.”
Not “keywords.”
But real-time intent → capability routing for embodied AI.
In this model, language becomes an interface layer, not a barrier. And robotics becomes globally interoperable by design.
The winners won’t own languages.
They’ll own the meaning layer that connects them.
#HumanoidRobotics #AI #Robotics #SemanticWeb #Ontology #MultilingualAI #EmbodiedAI #FutureOfWork #AIInfrastructure #PITNAI
1
1
1
44

🦉 Meet SWOWL — a open-source, web-based OWL & SWRL ontology editor.
Runs in one docker compose up.
👇
github.com/MyShivaRepo/swowl
#OWL #SWRL #SemanticWeb #Ontology #KnowledgeGraph #OpenSource
28

なんだか Web 3.0 と同じような話に聞える。SemanticWeb なんてのが Web 3.0 と言われていた時代があったのです (今でもそう?)。

元々 UNIX を扱ってた人達は「typescript」と言われると「あぁ、script コマンドの出力ファイルね?」「terminal session やん?」という認識だったのだけど、2012 年に突如「我こそが TypeScript なり」とアレが出てきたもんだから、typescript をどう呼んで良いか分からなくなってしまった。
147
Context Graphs are a convergence, and convergence needs architecture
Charles Betz of Forrester Research published a piece titled "Context Graphs Are a Convergence, Not an Invention", and it deserves to be read widely.
Having a VP-level analyst at a major research firm put it in writing, with the historical inventory to back it up, is genuinely significant. It signals that this conversation has moved from the practitioner fringe into the mainstream enterprise consciousness.
Betz traces the lineage back 40 years: Zachman's enterprise architecture framework in 1987, the ITIL push for configuration management databases in the 1990s, APM in the early 2000s, process mining, ChatOps, organisational network analysis, FinOps, software bills of materials, and architecture decision records.
His central observation: none of these systems talk to each other, and the convergence the VC community is declaring as a greenfield opportunity is in fact the long-overdue integration of work that's been accumulating in silos for four decades.
Kurt Cagle extends the argument, identifying three structural gaps that "context graph" as a term does not resolve:
The entity resolution gap -- a flat context graph doesn't solve it. You need a formal registration mechanism: a way to declare that an entity exists, give it a canonical identifier, and establish that the various local identifiers in legacy systems refer to it.
The events-versus-state gap -- process mining logs and APM traces are event records. CMDBs and EA capability maps are state records. Conflating the two in a single knowledge graph doesn't unify them; it obscures the distinction that makes each useful.
The governance gap -- "Who owns this graph?" is actually several questions at once. Governance has to be built into the architecture itself, not answered after the fact.
The proposed answer is holonic architecture -- a unit that has stable, dereferenceable identity, a formal separation between infrastructure layer and payload, a machine-enforceable boundary, and governed, audited portals between domains. The W3C RDF stack (RDF 1.2, OWL 2, SHACL 1.2, SPARQL 1.2) is the only implementation substrate that arrives vendor-neutral, with formal semantics and decades of standardisation behind it.
The question before the context graph community is whether the convergence happens as a coherent, formally specified, openly governed architecture -- or as a collection of incompatible vendor implementations, each claiming to be the "system of record for decisions," none of them able to talk to the others.
The map is not the territory. But a good map needs more than a title; it needs a cartographic system.
By Kurt Cagle
linkedin.com/pulse/context-g…
#EnterpriseArchitecture #SemanticWeb #ContextGraphs #OpenStandards
--
Join the Conversation
Subscribe to the Year of the Graph newsletter for quarterly insights on #KnowledgeGraphs, #GraphDB, Graph #Analytics, #AI, #DataScience and #SemTech .
📧 Subscribe: yearofthegraph.xyz/newslette…
💼 Sponsorship inquiries: yearofthegraph.xyz/contact/

2
8
289

Jun 9
💡Can library catalogs become more discoverable through #SchemaOrg and #LinkedData?
KO research investigates the role of #IFLALRM in semantic enrichment 👉
doi.org/10.31083/KO47266
#Metadata #SemanticWeb #Libraries

1
4
20

Malcolm Sparks (@MalcolmSparks) of GraphCentric builds AI-ready audit trails & attaches provenance to everything using semantic technologies.
He also shares how to build reactive apps without React. 🤯
graphrag.info/2026/06/08/mal… #GraphRAG #SemanticWeb #DataCentric
1
34

🚨 ISWC 2026 Industry Track CFP
Using Knowledge Graphs, Ontologies, Semantic Technologies, or GenAI in practice?
Showcase your impact at ISWC 2026.
📅 Submission deadline: 7 July 2026 (AoE)
🔗 iswc2026.semanticweb.org/#/c…
#ISWC2026 #KnowledgeGraphs #SemanticWeb #GenAI
2
3
241
📢 Final Call for Tutorials – #ISWC2026
The deadline for tutorial proposals is approaching!
🗓 Submit by June 9, 2026
📍 Bari, Italy | 25–29 Oct 2026
More info & submission details:
lnkd.in/dcJZAqsC
#SemanticWeb #KnowledgeGraphs #AI #LinkedData #Research

4
4
224
The future of humanoid robotics isn’t about hardware—it’s about meaning.
humanoid robots will scale globally only if intent can move seamlessly across languages, cultures, and jurisdictions.
That’s why semantic infrastructure matters.
PITN.ai is building a multilingual intent ontology layer supporting 30 languages—mapping human commands into structured robotic action across markets.
Not “translation.”
Not “keywords.”
But real-time intent → capability routing for embodied AI.
In this model, language becomes an interface layer, not a barrier. And robotics becomes globally interoperable by design.
The winners won’t own languages.
They’ll own the meaning layer that connects them.
#HumanoidRobotics #AI #Robotics #SemanticWeb #Ontology #MultilingualAI #EmbodiedAI #FutureOfWork #AIInfrastructure #PITNAI
1
2
50

May 27
James Hendler kicked off the 18th #WebSci26 today with his #keynote, “Web Science at 20, is it still needed?” 👉Answer: YES
websci26.org/?page_id=643
#WebScience #WebScienceAt20 #JamesHendler #WebSci #SemanticWeb #DigitalSociety #InternetResearch
@websciencetrust @tuBraunschweig

2
3
210

May 25
What Do You Need to Create a Useful Ontology?
Building an ontology doesn't have to feel like staring at a blank file wondering where to start. Kurt Cagle breaks down the 12 critical questions every ontologist should ask before writing a single line of code.
The most important? Define your scope first. Not what your ontology describes, but what questions it needs to answer. Each question expands scope, each deliberate exclusion keeps it manageable.
Key insights from the piece:
Start with SHACL, not OWL. Most projects need validation, not reasoning. SHACL gives you actionable error reports immediately. Add OWL only when you have a concrete inferencing requirement.
Events are entities, not properties. Give each event its own node. Hang temporal and provenance metadata directly on it. This is how you avoid losing the interesting information about when, who, and why.
Schemas and taxonomies are different things. A schema defines structure (what properties does this thing have?). A taxonomy defines classification (how is this categorized?). Use OWL/RDFS for structure, SKOS for controlled vocabularies.
Bottom-up AND top-down. Sketch your major concepts first, then immediately test against real data. The mismatch between elegant theory and messy reality is where the real modelling decisions live.
The article covers annotation metadata, blank nodes vs reifiers vs named graphs, mixing vocabularies, and when to graduate from knowledge graphs to context graphs to holonic architectures.
This is a practitioner's guide, not academic theory. Each question gets enough depth to make a decision, not write a dissertation.
What Do You Need to Create a Useful Ontology? ontologist.substack.com/p/wh…
#OntologyEngineering #SemanticWeb #DataModeling #RDF #SHACL
--
Connected Data London 2026 has been announced! 11-12 November, Leonardo Royal Hotel London Tower Bridge
📝 connected-data.london/post/c…
Join us for all things #KnowledgeGraph #Graph #analytics #datascience #AI #graphDB #SemTech #Ontology
🎟 Ticket sales are open. Benefit from early bird prices with discounts up to 30%. 2026.connected-data.london?u…
📺 Sponsorship opportunities are available. Maximize your exposure with early onboarding. Contact us at info@connected-data.london for more.

7
290

May 25
Choosing the Right Graph
The right graph is rarely just about the data model. It is also about the organisation around it.
Since roughly 2012, the knowledge graph category has collapsed two quite different intellectual traditions into a single marketing category.
The first - RDF and OWL - descends from formal logic, knowledge representation, library science and Berners-Lee's Semantic Web. The second - the labeled property graph (LPG) used by Neo4j, Apache TinkerPop and most contemporary graph databases - descends from graph theory, object-oriented databases and the operational demands of connected-data applications such as social networks, fraud detection and recommendation engines.
Both are graphs. Both are routinely called "knowledge graphs." Yet the data models, semantics, query languages, governance assumptions and engineering economics differ enough that picking the wrong one is a costly architectural mistake.
The question is often framed as RDF versus labelled property graph, but that can make the decision feel more like a technology debate than an architectural one. The discussion needs to focus on the problem being solved: what kind of meaning needs to be captured, how much governance is needed, what queries need to be supported, and how the graph will be used over time.
RDF and OWL can be powerful when shared meaning, standards, interoperability and reasoning matter. But they also need discipline around identifiers, vocabularies, modelling choices and stewardship.
Property graphs can be easier to start with and are very effective for operational workloads and application development. But simplicity at the start can become a constraint later if provenance, integration or semantic consistency becomes central.
The choice should be contextual. The best graph is not the one that looks most elegant on a slide. It is the one the team can govern, query, explain and evolve.
Use RDF/OWL when the dominant problem is meaning, integration across organizational boundaries, formal reasoning, FAIR/linked-open-data publishing, or long-term governance.
Use a labeled property graph when the dominant problem is operational, multi-hop traversal performance on connected data, rich edge attributes and developer ease of adoption within a controlled application boundary.
When both axes are equal, use a hybrid store such as Amazon Neptune or Stardog - and budget for the conceptual overhead of maintaining two query surfaces.
That said, RDF 1.2's native edge-annotation support shifts this formula, weakening one of the historical reasons to reach for an LPG in the first place.
A useful read if you are designing a graph strategy, selecting tools or bridging semantic modelling with delivery.
By Jessica Talisman h/t Sergey Vasiliev
jessicatalisman.substack.com…
#KnowledgeGraphs #RDF #PropertyGraphs #SemanticWeb #Ontology
--
📩 The Year of the Graph's Spring 2026 newsletter issue on all things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech is coming soon.
Subscribe and follow to be in the know. Reach out if you'd like to be featured 👇
yearofthegraph.xyz/newslette…

8
13
582

Jonathan Herman has consistently ranked Top 5 globally on Crunchbase's Semantic Web People list — as has Baller Mixed Reality on the Companies list, both for years. How does your company show up to LLMs? → JonathanMHerman.com #SemanticWeb #AEO

2
5
May 19
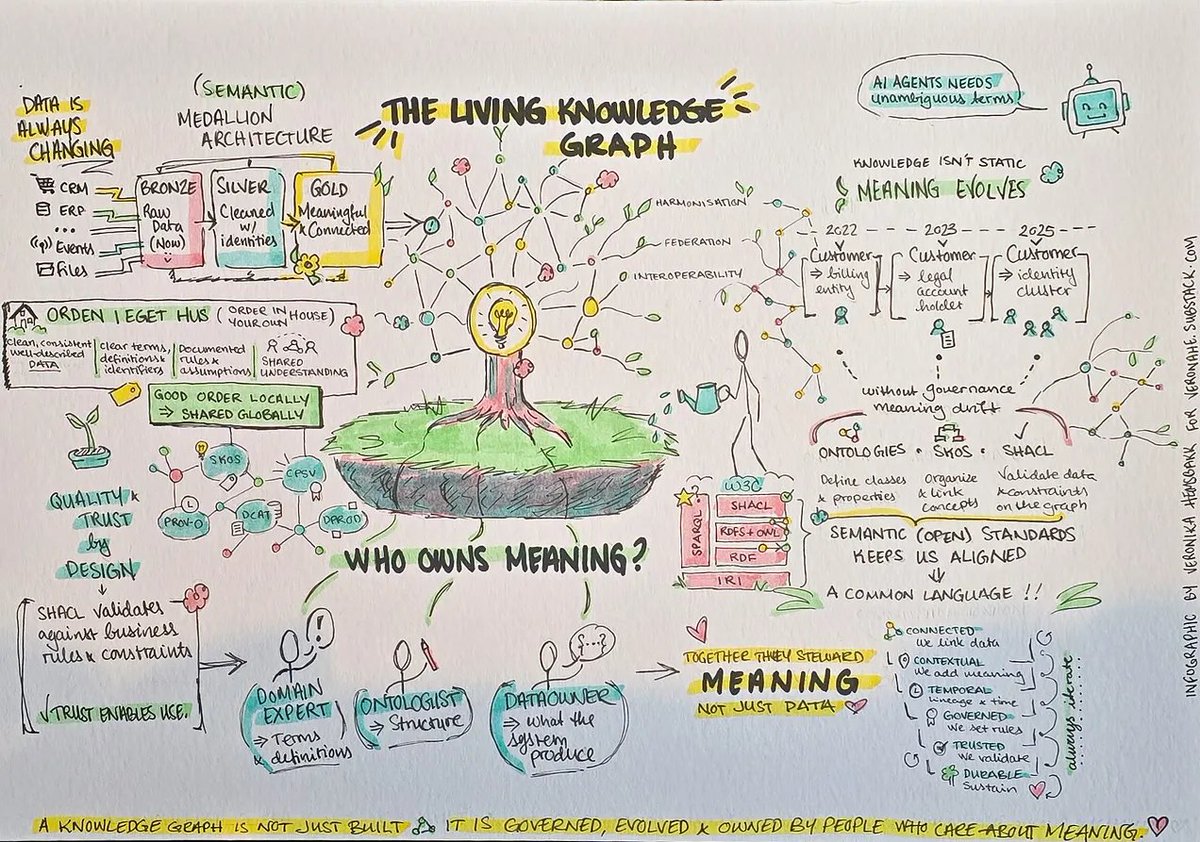
The Living Knowledge Graph: Durability, Roles and Who Owns the Meaning
A knowledge graph is not a deliverable. It is a living information architecture, and the curation is the work.
Veronika Heimsbakk builds on her Semantic Medallion piece for Modern Data 101, where she showed how to transform tabular data into a knowledge graph in four lines of Python, to address the harder question: what surrounds those four lines once the graph lives in production?
The framing is sharp: semantic richness and semantic durability are different properties. Connection is not the same as fidelity. The architecture that solves the first does not automatically solve the second.
The answer is a durability stack built from native RDF primitives:
SHACL shapes as the contract layer, turning an identifier into a binding commitment
Named graphs with PROV-O as the temporal anchor, so queries can ask what was believed about an entity on a given date
Versioned OWL ontologies with deprecation axioms, so drift is detectable and migration is traceable
SKOS controlled vocabularies, where meaning changes travel through the graph explicitly
But the stack is not self-maintaining. Four distinct roles own it: the data engineer who operates the pipeline, the knowledge engineer who translates domain meaning into machine-readable constraints, the ontologist who designs and evolves the model, and the domain expert who is the source of authority on meaning.
The deepest point: in a join-logic architecture, the meaning of "customer" lives in SQL scripts. Domain experts file tickets and review PRs they cannot read.
In a semantic architecture, a SKOS vocabulary is editable by anyone with a structured editor. The compliance officer can maintain the regulatory concept hierarchy directly. The maintenance load moves to the people who actually know the answer.
Governance is not adjacent to the architecture. In a working semantic system, governance is architecture, expressed in machine-readable form, maintained by the people who know what the meaning should be.
By Veronika Heimsbakk.
The Living Knowledge Graph: Durability, Roles and Who Owns the Meaning veronahe.substack.com/p/the-…
The Semantic Medallion substack.com/home/post/p-196…
#KnowledgeGraphs #SemanticWeb #DataGovernance #Ontology #RDF
--
Connected Data London 2026 | 11–12 November | Leonardo Royal Hotel London Tower Bridge
🎤 Share your work with the world's most passionate data community. The Call for Submissions is open. connected-data.london/2026-c…
🎟 Tickets on sale now. Early bird discounts up to 30%. 2026.connected-data.london?u…
📺 Sponsorship opportunities available. Contact info@connected-data.london for details.
#KnowledgeGraph #GraphRAG #Ontology #Graph #AI #DataScience #GraphDB #SemTech
1
2
7
590
PITN.ai enables corporations deploying humanoid robotics at scale to eliminate fragmented localization, regional SEO architectures, and market-specific semantic modeling.
Within the PITN.ai framework, all languages and scripts resolve “HUMANOID,” “HUMANOIDS,” and “HUMANOID ROBOTS” into a single globally unified semantic identity, enabling consistent routing, interpretation, and execution across AI systems worldwide.
This architecture reduces complexity in:
• International humanoid deployment
• AI agent integration
• Cross-border product discovery
• Multilingual AI infrastructure
• Global semantic interoperability
Digital assets evolve from static marketing endpoints into operational infrastructure nodes embedded directly within AI decision systems.
PITN.ai establishes humanoid-related semantic identity as foundational infrastructure for scalable global humanoid robotics deployment.
#PITN #AI #HumanoidRobots #Humanoids #Humanoid #Robotics #SemanticWeb #AIAgents #FutureOfSearch #MultilingualAI
#corporate #siliconvalley #vc
1
3
131
The internet is shifting from keyword search to AI intent routing.
PITN.ai is building the semantic layering infrastructure that connects humanoid & robotics terminology across 30 languages and scripts.
Domains are no longer SEO assets — they are becoming AI routing nodes in decision graphs.
In the AI economy, users won’t “search” for humanoids…
they’ll express intent, and systems will resolve meaning instantly across languages.
PITN ensures that “robot,” “humanoid,” and “humanoid robot” are consistently mapped into a unified global semantic layer — regardless of language or script.
This is not SEO evolution.
This is the infrastructure layer of AI discovery.
#PITN #AI #HumanoidRobots #SemanticWeb #AIEconomy #Robotics #FutureOfSearch #AIAgents #MultilingualAI #Web3AI
1
2
53

🌐 DICE was represented with 5 papers at the 23rd European Semantic Web Conference (ESWC 2026) in Dubrovnik, Croatia (May 10–14)!
Congratulations to all authors and thank you to the organizers for a wonderful conference! 🙌
#ESWC2026 #SemanticWeb #KnowledgeGraphs #DICEontour

5
142
May 14
Can we trust ontologies generated by LLMs?
Large Language Models are becoming powerful assistants for Knowledge Graph and Ontology Engineering. But when they generate ontologies, they can also introduce subtle — and sometimes critical — modeling mistakes.
"Pitfalls in AI-Generated Ontologies: Strategies for Detection and Mitigation" discusses how to move from enthusiasm to reliability when using LLMs for ontology engineering, with two concrete contributions:
Ontology Pitfalls Detector, a new open-source tool that detects mistakes in LLM-generated ontologies.
Ontology Toolkit by Lettria, a platform for automatically building ontologies from documents — while avoiding common ontology design mistakes.
Pitfall Detection evaluation library:
* tailored to LLM-generated ontologies
* structural, logical, naming, and semantic issues
* complementary to existing ones
Input
* OWL/RDF ontology
Detection techniques
* SPARQL queries
* Hierarchy analysis
* Semantic similarity
SBERT
Distance over WordNet
* LLM-as-a-judge
Ontology Toolkit(generation pipeline)
Goal: Automatically generate high-quality ontologies from unstructured text
Approach
* Deterministic, multi-stage pipeline
* Each stage:
Produces structured intermediate outputs
Applies strict validation correction loops
Core Principles
* Use-case driven extraction (focus on relevant concepts)
* Explicit semantics (no implicit or ambiguous modeling)
* Controlled hierarchy construction (avoid flat or noisy structures)
* Logical enrichment with OWL axioms
By Raphael Troncy Pasquale Lisena, Julien PLU, Oscar Moreno Escobar and Edouard Trouillez EURECOM Lettria
Ontology Pitfalls Detector: github.com/D2KLab/Ontology-P…
Ontology Toolkit: perseus.lettria.com
Presentation: docs.google.com/presentation…
#LLMs #OntologyEngineering #SemanticWeb #GenerativeAI #ResponsibleAI #KnowledgeRepresentation #EmergingTech
--
Connected Data London 2026 | 11–12 November | Leonardo Royal Hotel London Tower Bridge
🎤 Share your work with the world's most passionate data community. The Call for Submissions is open. connected-data.london/2026-c…
🎟 Tickets on sale now. Early bird discounts up to 30%. 2026.connected-data.london
📺 Sponsorship opportunities available. Contact info@connected-data.london for details.
#KnowledgeGraph #GraphRAG #Ontology #Graph #AI #DataScience #GraphDB #SemTech

2
14
711