
ai x humans | prev PhD @Berkeley_AI
Joined March 2013
- Tweets 376
- Following 1,021
- Followers 5,283
- Likes 849
51 Photos and videos






Pinned Tweet

21 Oct 2025
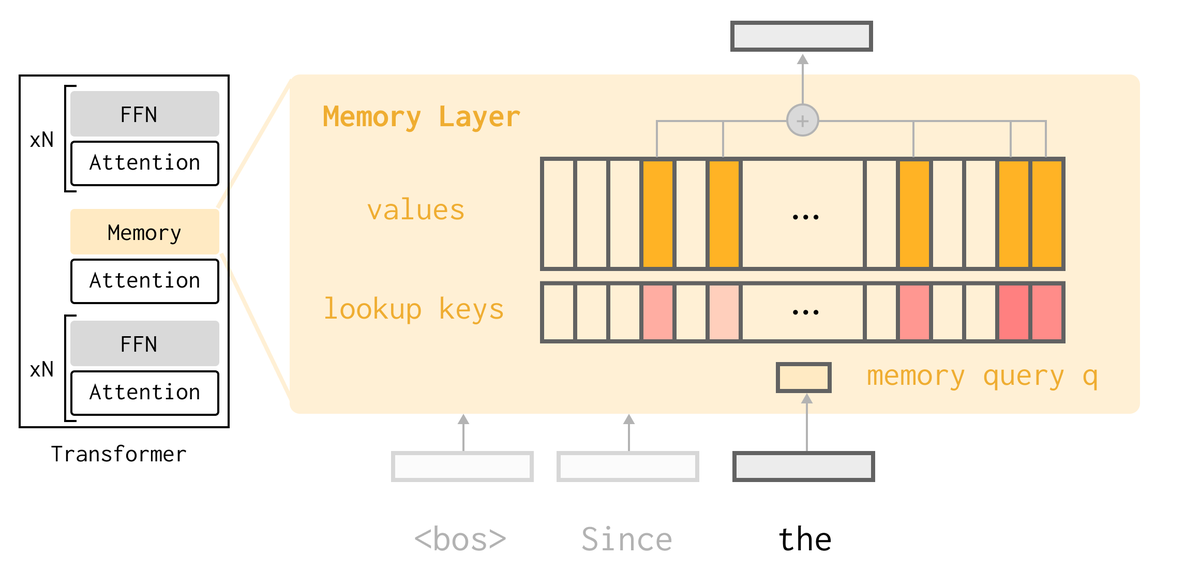
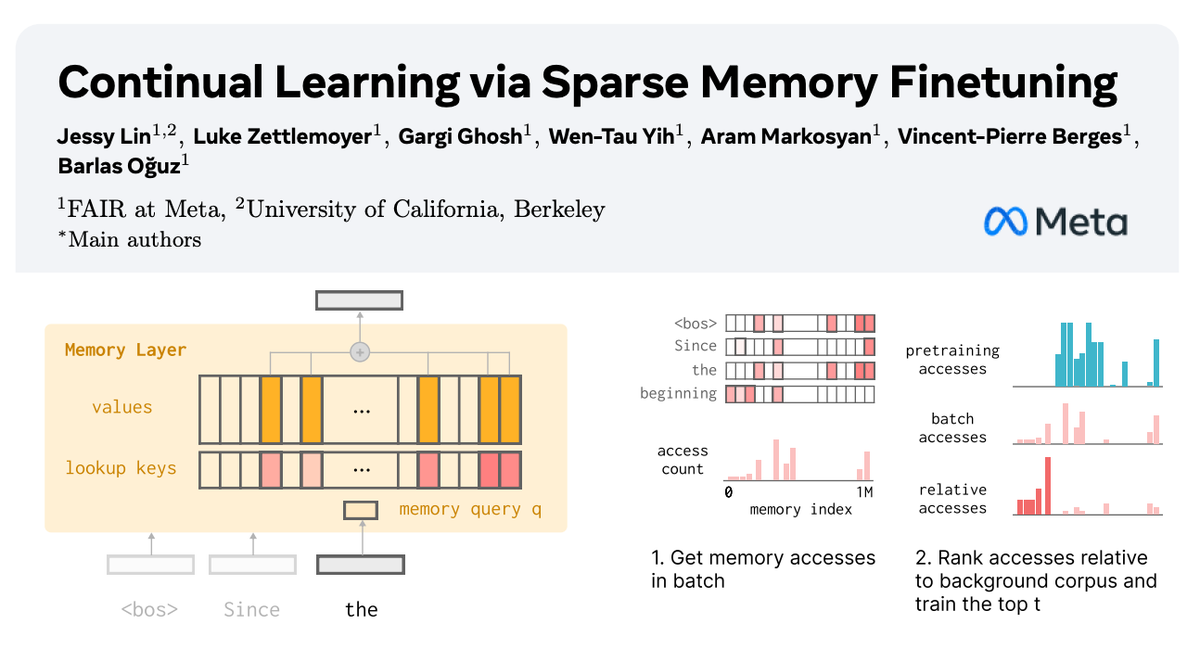
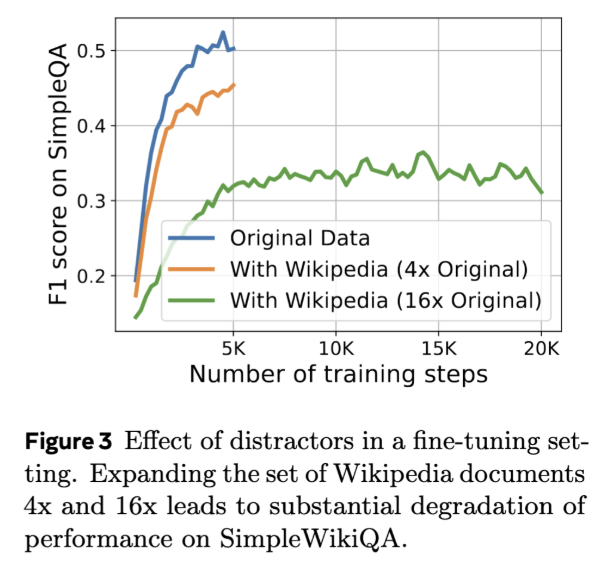
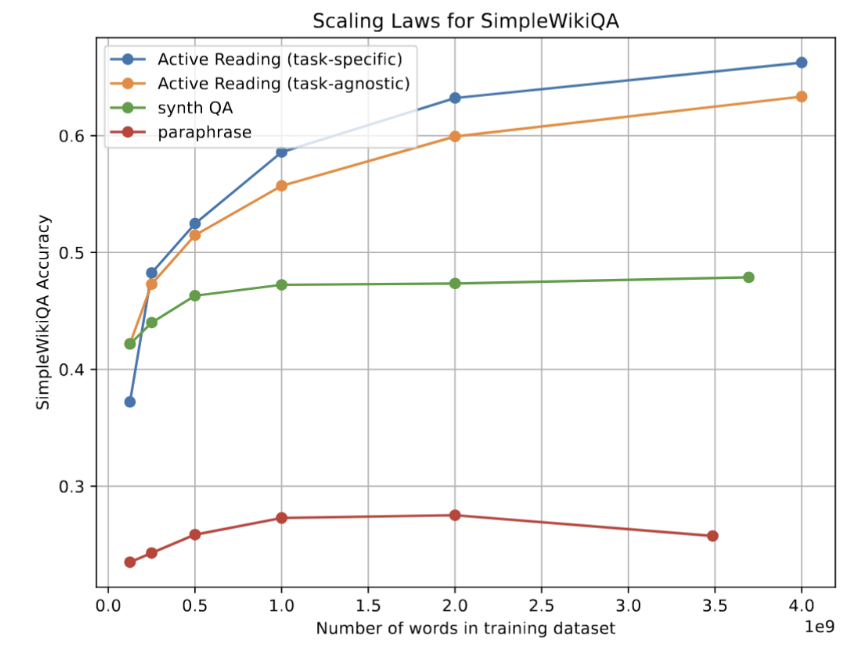
As part of our recent work on memory layer architectures, I wrote up some of my thoughts on the continual learning problem broadly:
Blog post: jessylin.com/2025/10/20/cont…
Some of the exposition goes beyond mem layers, so I thought it'd be useful to highlight separately:
28
166
1,170
204,282
Jessy Lin retweeted

May 27
New paper! LLM memory keeps improving, but this makes them *worse* as user sims. If we want to build models that can, e.g., simulate realistic students to train chatbots to be better teachers, then these models need to be able to forget like humans do
📄: arxiv.org/abs/2605.25680

ALT Title page of our paper, "Simulating Human Memory with Language Models"
14
70
458
45,927
May 4
Building a good benchmark for continual learning takes a lot of thought -- it's non-trivial to make it hard in the ways that matter. excited to see people working towards this
May 4

Today, we’re releasing Continual Learning Bench 1.0: the first, realistic benchmark for measuring how AI systems can improve in online settings.
Benchmarks today assume models are stateless. Each example is independent, and once a system finishes a task, it moves on as if nothing happened.
But deployed AI systems should learn from experience. We tested 10 frontier systems against novel, expert-validated tasks and find there’s still plenty of headroom for learning. (1/n)

3
33
5,043

Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
1,142
3,734
28,819
5,954,607
Apr 10
you too can believe in what you're making (fried chicken)
Apr 9

I’m obsessed with people who are obsessed. This is what true product obsession sounds like:
6
1,330
Jessy Lin retweeted

Apr 1
Here's a plausible positive scenario that doesn't require many further AI advancements. I wanted to clearly paint the path "from here to there" instead of hand-waving so it starts out negative but ends positive (I swear):
A recession leads to slowed hiring and a breakdown of the early-career ladder. The political window opens for industrial policy on AI: governments encourage firms to launch apprenticeship programs to bridge the training gap between junior and senior white-collar roles, instilling discernment and judgment of AI outputs. Programs help reshuffle people with clerical jobs into education (especially elementary and middle school 1-1 tutoring) or nursing (and given AI tools to upskill into providing clinical care). Those with a risk-taking or strategic bent become entrepreneurs and executives overseeing AI agents. Industrial policy is important, but AI also helps to decrease regulatory and compliance burdens on construction; this sector expands, and the built environment starts improving (e.g. high speed rail becomes more possible).
Later on, material abundance (robot manufacturing) means that goods are cheap and easier to manufacture domestically. Most people's spending is therefore on human-led services, today's luxuries. For example, high quality education: schooling in many places (including the US) has historically been low quality for most, with many knock-on effects. 1-1 personal attention by human teachers (for younger students) AI personalized tutoring (for older students) bridges this gap. Everyone is healthy: cheap AI triaging of medical issues lowers the barrier to preventative as well as life-saving care. Entrepreneurship is enabled by easy access to AI agents. The bar for customer service is raised all-round (high-end retail and hospitality services, like what you see in Japan). Everyone works 3-4 days a week. Baumol's cost disease is a feature not a bug: the relative expense of human services stops being a budget problem and starts being a labor market solution. That is where the jobs are, and they're jobs worth having.
Apr 1

The AI labs have actually done a bad job explaining what the future they are building towards will actually look like for most of us.
Even “Machines of Loving Grace” has very few well-articulated visions of what Anthropic hopes life will be like if they succeed at their goals.
27
46
382
76,456
Mar 24
amaazing blog post. now it's so easy for anyone to put their mental imagery on the page
Mar 23

Cursor can now search millions of files and find results in milliseconds.
This dramatically speeds up how fast agents complete tasks.
We're sharing how we built Instant Grep, including the algorithms and tradeoffs behind the design.

2
56
9,978
Feb 16
inner loop science, outer loop art
Feb 16

taste is a new core skill
19
2,565
Jessy Lin retweeted

Feb 5
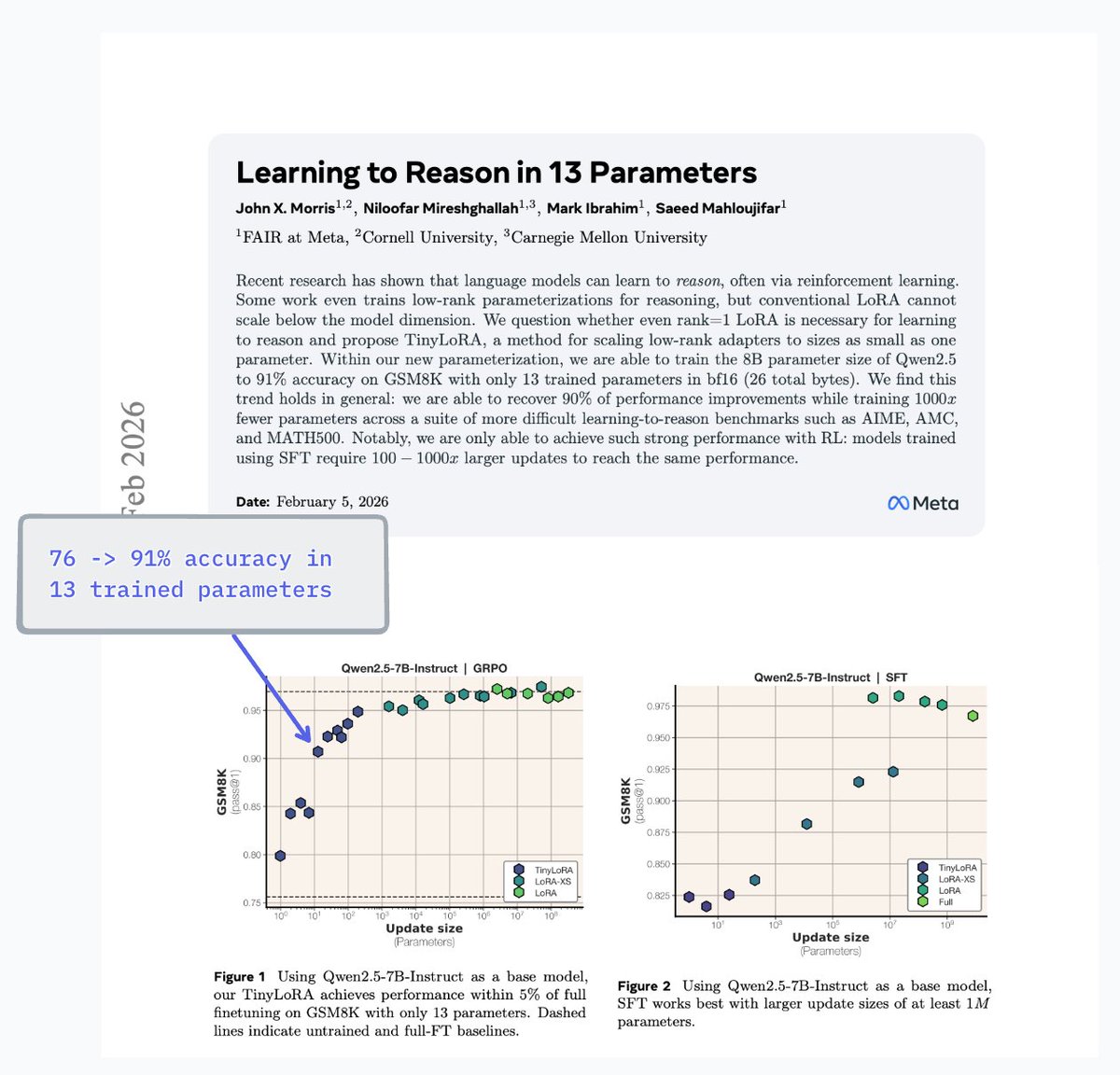
at long last, the final paper of my phd
🧮 Learning to Reason in 13 Parameters 🧮
we develop TinyLoRA, a new ft method. with TinyLoRA RL, models learn well with dozens or hundreds of params
example: we use only 13 parameters to train 7B Qwen model from 76 to 91% on GSM8K 🤯
60
230
2,043
182,448
Jessy Lin retweeted

Jan 29
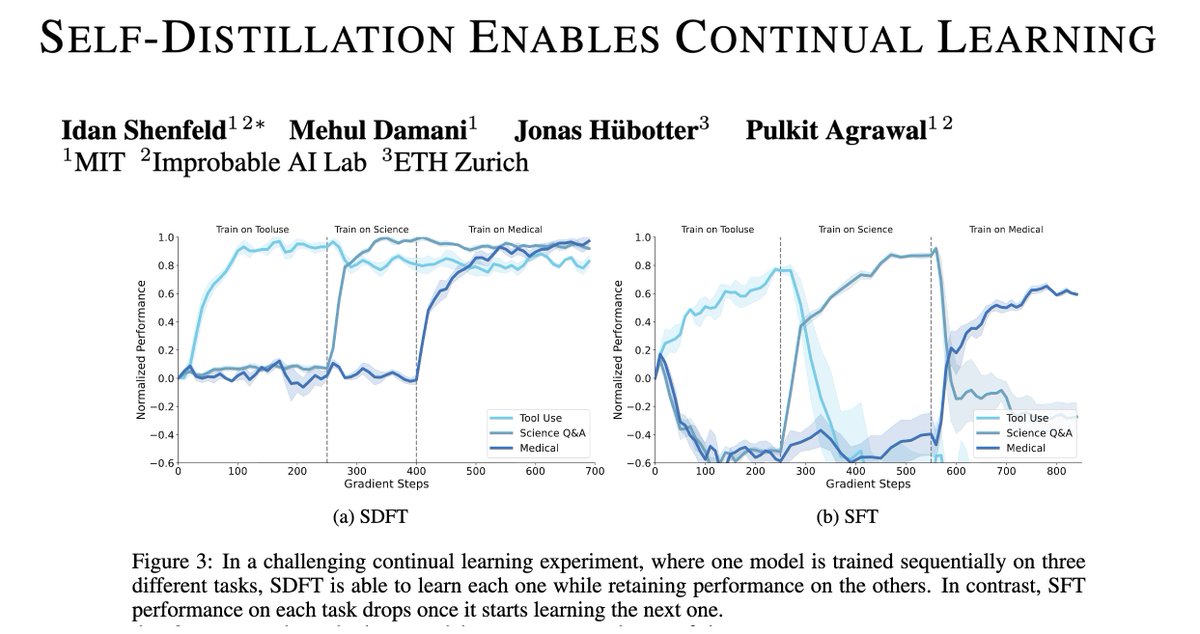
People keep saying 2026 will be the year of continual learning.
But there are still major technical challenges to making it a reality.
Today we take the next step towards that goal — a new on-policy learning algorithm, suitable for continual learning!
(1/n)
50
223
1,508
239,282

Jan 20
the plot thickens ...
(in our understanding of memory in sparse layers vs. dense MLPs!)
Jan 19

I really liked this new paper which finds that dense MLPs from transformers can be distilled well into much sparser MoEs. This makes it a bit less surprising that gradient-based attribution on dense MLPs shows only a few neurons are responsible for the bulk of behaviour. arxiv.org/abs/2512.18452
1
47
11,912
Jessy Lin retweeted

Jan 6
New research from Sakana AI
"Fast-weight Product Key Memory"
So the classic Product Key Memory (PKM) layer (a sparse key–value memory module used alongside attention) is a huge sparse memory, but it’s "slow" weights, where it is trained once, then frozen at inference, so it can’t memorize new info at deployment.
Sakana AI's FwPKM makes PKM writable at test time: it does small chunk-level gradient updates to write key value “episodes”, then retrieves them with product-key lookup.
This adds an episodic memory layer that stays effective far beyond training context (4K -> 128K) and helps when relevant info is separated by thousands of tokens.

15
112
654
47,624
Jan 6
great post, and I generally find this way of reasoning about "limit cases" and things that should be true in principle to be really valuable for thinking about what approaches to "memory" and continual learning make sense in the long term (out of a huge and heterogenous design space!)
> repeated data: when humans see the same piece of experience over and over again, we eventually stop updating
-> what kind of update algorithm would make this true?
> integration into existing concepts: if someone tells you they're from Michigan, your representation of Michigan should also change
-> what kind of representation/parameterization would make this true?
Jan 5

I have a bunch of thoughts about continual learning and nothing to do with them (I'm working on something else) so I figured I'd just turn them into a post:
First: I think people use "continual learning" to point at a cluster of issues that are related but distinct.
I'll list the issues and then speculate about what might fix them.
a) Catastrophic Forgetting: If you train on a distribution D_1 and then do SFT on another distribution D_2, you'll often find that your performance on D_1 degrades. The extent of this issue is maybe overstated and is more true for SFT than for RL, but it's still real. There's also an important limit case that IMO is a "smell" for the way we train models currently: repeated data can seriously harm model performance. Humans don't have this problem - they eventually just stop updating on redundant information.
b) No integration of new knowledge into existing concepts: If I tell you that I'm from Michigan, you will update your representation of me to include that fact, but you will also change your representation of Michigan. Michigan becomes "a place where someone I know is from". If people ask you questions about Michigan in the future, you may answer those questions with this knowledge in mind. If I tell a chatbot that I'm from Michigan, that fact may get stored in a memory file about me, but it won't affect the model's representation of Michigan.
c) No consolidation from short-term memory to long-term memory: Models are good at accumulating information in context up to a point, but then they run out of context (or effective context) and performance degrades. They are missing a mechanism for deciding what's important to retain and then taking action to retain it.
d) No notion of timeliness: When you tell a human something, they also retain *when* they learned it, and that "time tag" becomes part of the representation. Humans experience a stream of facts unfolding through time. As a result we form an implicit model of history/causality. Many people can answer "who is the current Pope?" without doing a special search step.
Now that we've enumerated the issues, we can think about solutions.
In AI it's always worth asking why the simplest solution can't work.
The very simplest thing to try is what chatbots currently do: maintain a text file of memories.
IMO it's obvious why this is unsatisfying relative to what humans are doing, so I won't dwell on it.
I expect there are many refinements you could make here around learning to manually manage the text file, but I also expect these approaches to be brittle.
A slightly smarter thing that's still pretty simple is to just keep updating the model during deployment.
I actually do think that something like this could work OK, but we probably need a few tweaks.
Some combination of the following seems worth pursuing:
1. Sparser updates: Catastrophic forgetting is plausibly worsened by updating all parameters at once. I'd bet either selective parameter updates or making the models themselves sparser could help a lot here. @realJessyLin has some nice work here.
2. Update only on surprising data: Updating on every new datapoint feels wrong. We want a mechanism that decides what’s important/surprising and only updates on that subset. A crude version: automatically generate questions about a datapoint and only update if the model fails to answer them. The hippocampus also has interesting mechanisms for doing this that seem worth trying to emulate.
3. Don't train on the raw datapoint w/ the standard objective. Given that we've decided a datapoint is surprising, I don't think we should just train on it using the standard objective. We may want to automatically generate questions about a given corpus and train on the answers (as in e.g. the Cartridges work) and we may also want to modify the objective. One option is to do prompt distillation with the facts in context - the intuition being that the consolidated model ought to answer the question as though it has the facts on hand.
These are "in-paradigm" approaches compatible with LLMs.
I bet they’ll yield real progress, but I’m also starting to suspect something less in-paradigm may be needed for a really satisfying solution. That’s for a different post though.
1
1
12
3,688
Jessy Lin retweeted

19 Nov 2025
Today, we present a step-change in robotic AI @sundayrobotics.
Introducing ACT-1: A frontier robot foundation model trained on zero robot data.
- Ultra long-horizon tasks
- Zero-shot generalization
- Advanced dexterity
🧵->
432
637
5,392
2,042,935
19 Nov 2025
I really like this idea of having agents that control a computer with your context and data, as we're all trying to figure out the right form factor for computer/browser use agents
zo's answer is ~the equivalent of "personal computers" for the ai era, and it's so cool to think about how it enables the average person to script and automate things in their lives that would otherwise be inaccessible
congrats @0thernet @perceptnet !! 💻

today we're announcing @zocomputer.
when we came up with the idea – giving everyone a personal server, powered by AI – it sounded crazy.
but now, even my mom has a server of her own.
and it's making her life better.
she thinks of Zo as her personal assistant. she texts it to manage her busy schedule, using all the context from her notes and files. she no longer needs me for tech support.
she also uses Zo as her intelligent workspace – she asks it to organize her files, edit documents, and do deep research.
with Zo's help, she can run code from her graduate students and explore the data herself. (my mom's a biologist and runs a research lab. hi mom)
Zo has given my mom a real feeling of agency – she can do so much more with her computer.
we want everyone to have that same feeling. we want people to fall in love with making stuff for themselves.
in the future we're building, we'll own our data, craft our own tools, and create personal APIs. owning an intelligent cloud computer will be just like owning a smartphone. and the internet will feel much more alive.
THIS ONE'S FOR YOU MOM ❤️
special thank you to @modal, @pydantic AI, and @steeldotdev for being great partners leading up to this launch. and thank you @cursor_ai for being my sword 🗡️
and thank you to everyone who believed in us. a small handful: @southpkcommons, @adityaag, @chrisbest, @rauchg, @immad, @shreyas, @MattHartman, @lessin, @gokulr, @sabrinahahn, @iqramband, @whoisnnamdi, @guruchahal, @mikemarg_, @gaybrick, @SJCizmar, @magdovitz, @anneleeskates, @henloitsjoyce, @sugarjammi, @vibethinker, @aaronmakhoffman, @Sunfield__
3
4
33
7,429
19 Nov 2025
i like this thread from rob on some of his favorite use cases: x.com/perceptnet/status/1991…
19 Nov 2025

The computer is the most flexible tool humanity has invented: whatever you can imagine, if you can describe it precisely enough it runs on a machine.
I've spent the last 15 years learning how to describe things precisely to computers, and yet my side projects feel less like a triumph of personal computing and more like a graveyard of abandoned threads. Not because I don't want them, but because they take too much effort to build and maintain.
Today we're introducing Zo Computer - the computing environment I always wanted.
3
1,117
5 Nov 2025
I'm a huge fan of what @minafahmi and @sandbar are doing to bring interaction with ai to life in a beautifully designed hardware product 🏖️ so many thoughtful details in how they interface with everyday life

Introducing Stream & Stream Ring. Let thoughts & ideas flow ∽
Preorder now at sandbar.com
2
3
6
2,993
Jessy Lin retweeted

5 Nov 2025
Today, we’re thrilled to announce $20M in funding led by @a16z, with support from @saranormous, @amasad, @akothari, @garrytan, @justinkan, @atShruti, @naval, @scottbelsky, @gokulr, @soleio, @kevinhartz and more.
@wabi is ushering in a new era of personal software, where anyone effortlessly create, discover, remix, and share personalized mini apps.
For 50 years, software was made for people.
The next 50, it will be made by people.
Just as YouTube unlocked creative power through video,
Wabi will unlock creative power through software.
The YouTube moment for apps is here.
We can’t wait to see what you create.
232
142
2,416
841,525

in our new post, we walk through great prior work from @agarwl_ & the @Alibaba_Qwen team exploring on-policy distillation using an open source recipe: you can run our experiments on Tinker today!
github.com/thinking-machines…
i'm especially excited by the use of on-policy distillation to enable new "test-time training" personalization methods, allow the model to learn new domain knowledge without regressing on post-training capabilities
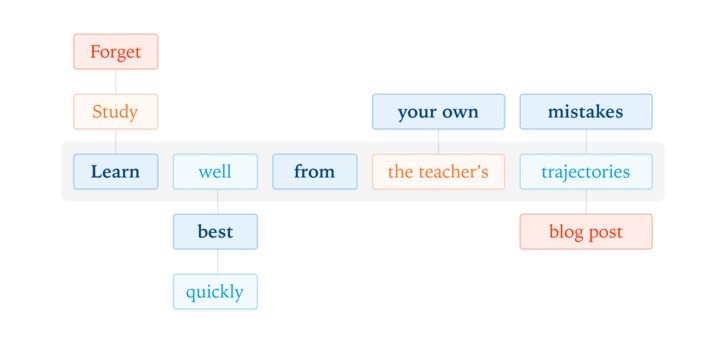
27 Oct 2025

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other approaches for a fraction of the cost.
thinkingmachines.ai/blog/on-…
14
29
366
95,577
21 Oct 2025
As part of our recent work on memory layer architectures, I wrote up some of my thoughts on the continual learning problem broadly:
Blog post: jessylin.com/2025/10/20/cont…
Some of the exposition goes beyond mem layers, so I thought it'd be useful to highlight separately:
28
166
1,170
204,282
21 Oct 2025
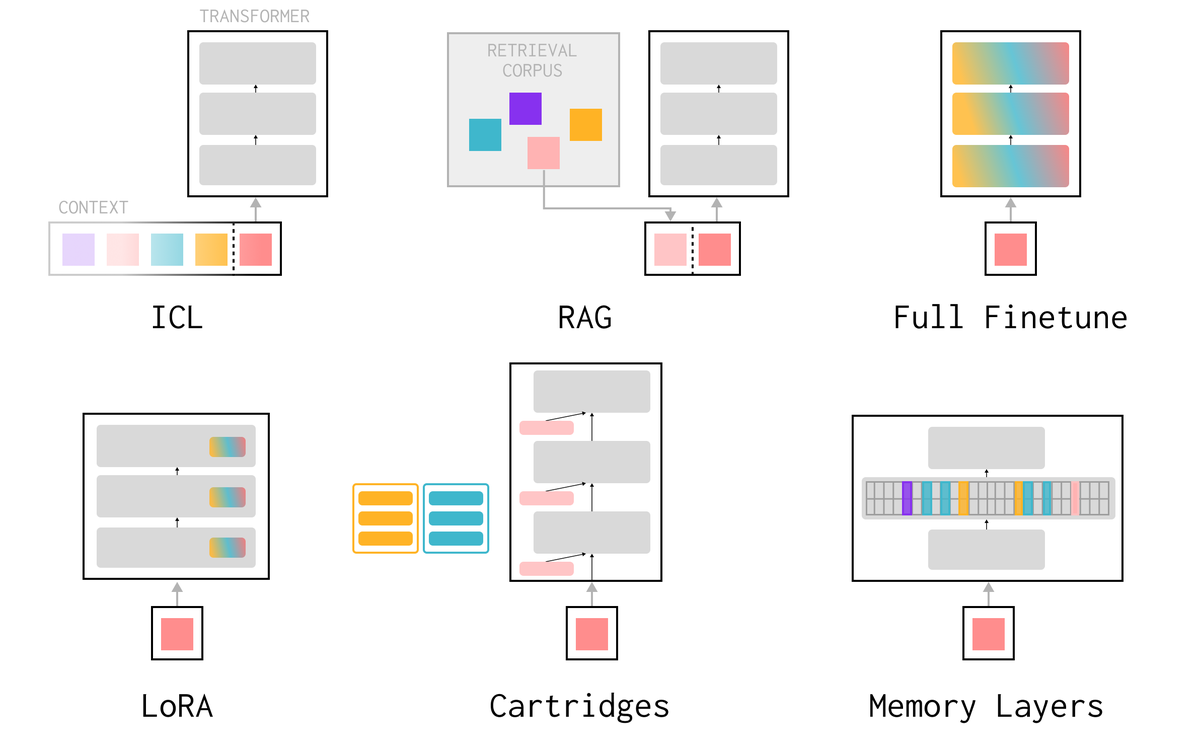
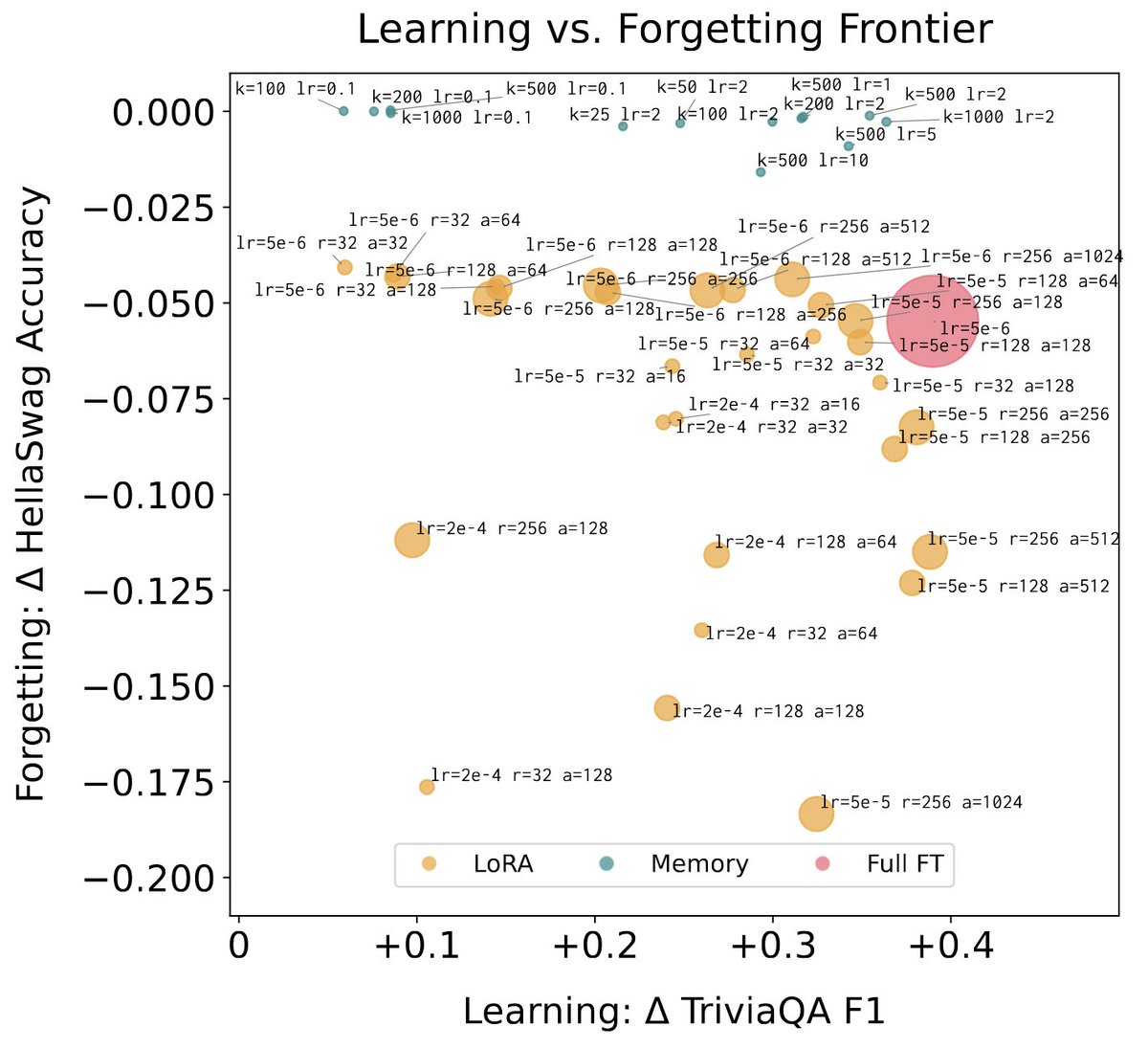
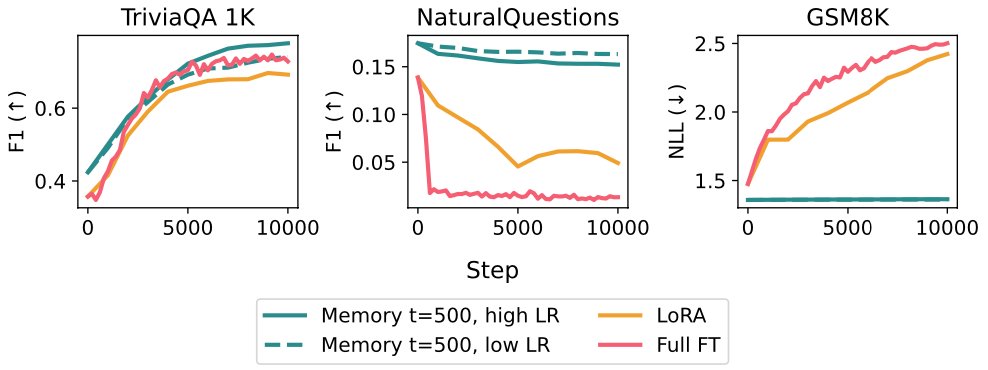
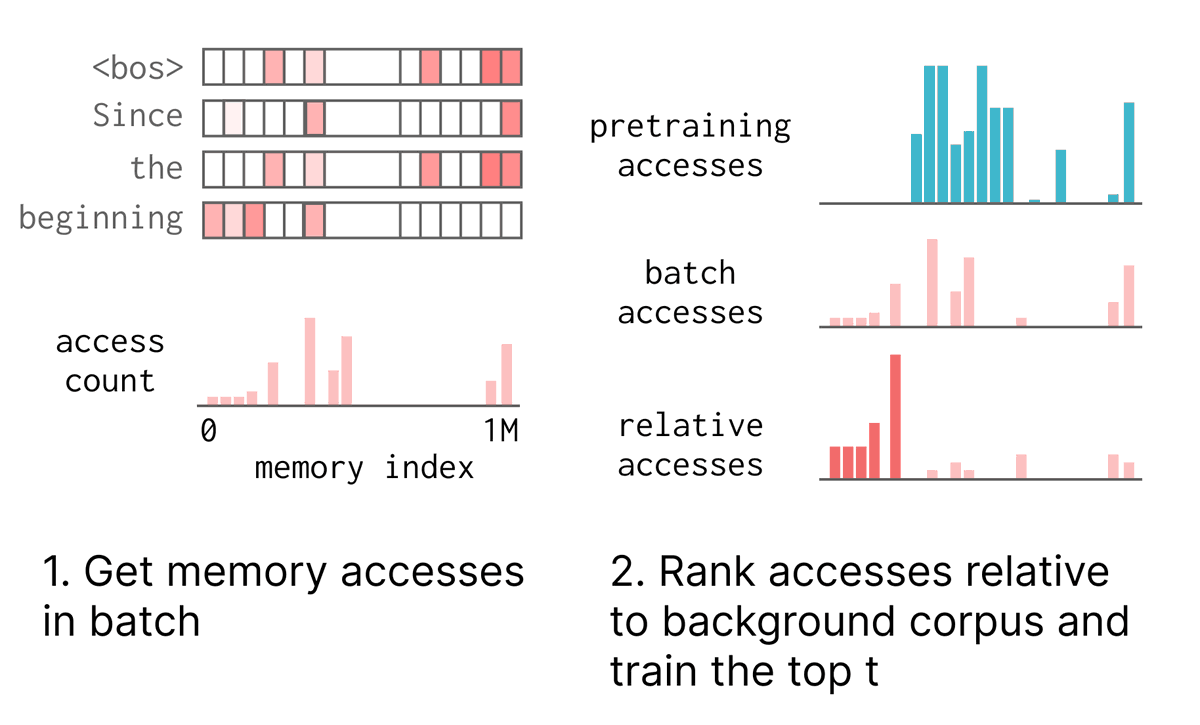
There's a huge spectrum of approaches to memory/continual learning - ranging from RAG to dreams of "infinite context" generalization to baking in new knowledge w/ gradient updates.
I'm personally bullish on parametric updates that allow the model itself to get smarter over time (rather than pure systems-based approaches around black box models), but there's still a lot of open questions to make this work at scale.
6
4
85
14,133
21 Oct 2025
I talk about the design space in the post, and try to motivate why memory layers make sense from first principles.
Overall, there's still so much to explore here and I'm excited to keep working on these questions – reach out if you're thinking about similar problems! :)
1
2
32
3,854