
MoE-Bind: Guiding De Novo Protein Binder Generation with Sparse Experts
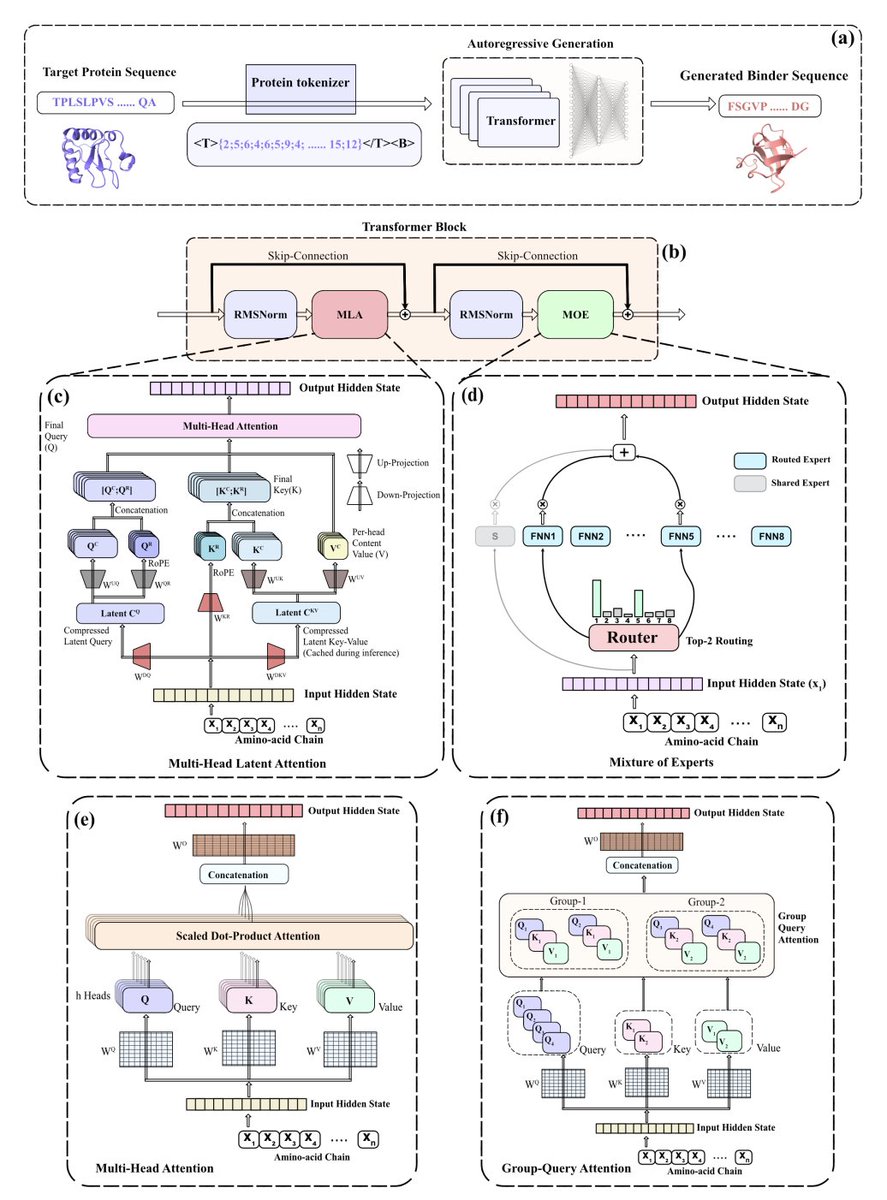
1. The paper introduces MoE-Bind, a sequence-only autoregressive protein binder generator that combines Multi-head Latent Attention (MLA) with a sparse Mixture-of-Experts (MoE) feed-forward stack, aiming to keep binder generation fast and structure-free at inference while improving quality per unit compute.
2. Key architectural idea: sparsify where most parameters live. Since transformer FFNs hold a large fraction of parameters, MoE-Bind replaces dense FFNs with top-2 routing over 8 SwiGLU experts (plus a shared always-on expert), so only ~2/8 of expert parameters activate per token while total capacity increases.
3. MLA targets the other bottleneck: KV-cache memory during autoregressive decoding with long receptor prompts. MoE-Bind compresses keys/values into a low-rank latent (rKV=64) and uses decoupled RoPE (separate positional subspace), yielding a large KV-cache reduction (reported 24× vs a GPT2-like MHA peer at the 100M tier).
4. Compute/parameter framing: the 100M-parameter MoE-Bind model has ~102.7M total params but ~38.8M active params per token, positioning it as “compute-matched” against ~38M dense baselines while often matching or exceeding ~100M dense baselines in structure-level metrics.
5. Training pipeline: pre-train on UniRef50 (character-level tokenization; 31-token vocab including delimiters/control tokens) with next-token prediction, then instruction fine-tune on high-confidence STRING v12 physical PPIs (score ≥900) after heavy redundancy reduction (MMseqs2 clustering at 40% identity, 80% coverage), ending with ~2.1M usable interaction pairs.
6. Leakage control is a major methodological emphasis. For DB5 evaluation, the authors build a strict 22-target benchmark by removing any DB5 proteins with ≥10% identity (≥80% coverage) to UniRef50 or STRING sequences, then also report a larger benchmark (78 unique targets) under a relaxed fine-tuning-only leakage filter and additional deduplication.
7. Structure-level evaluation uses structure predictors only for external assessment, not for inference-time filtering: AlphaFold2-Multimer (ColabFold) on the strict 22-target DB5 set, and Boltz-2 with MSA on the larger 78-target set. Hits are defined stringently as generated ipTM ≥ reference (native pair) ipTM for the same target.
8. Main structure-level results: on the 22-target AF2-Multimer evaluation, MoE-Bind achieves 6/22 hits (27.3%) vs MHA 3/22 and GQA 4/22; on the 78-target Boltz-2 MSA benchmark, MoE-Bind reaches 19/78 hits (24.36%), slightly higher than dense 100M baselines (GQA-100M 23.08%, MHA-100M 21.79%) and higher than compute-matched dense ~38M baselines (GQA-38M 20.51%, MHA-38M 16.67%) while activating ~38.8M params/token.
9. Sequence-level quality: MoE-Bind’s generated binders better match DB5 amino-acid composition, avoid long homopolymer runs (no 6–7 or ≥8 runs reported), show “controlled novelty” vs STRING (less mass at ~0% identity than dense baselines), and have improved predicted stability by instability index (median ~29–30, with ~2/3 below 40).
10. Interpretability contribution: routing analysis reports expert specialization at individual amino-acid and biochemical-group levels, arguing that proteins’ small, biochemically structured alphabet makes MoE routing more interpretable than typical natural-language MoE behavior, and suggesting future expert pruning/specialization guided by biochemical priors.
📜Paper: biorxiv.org/content/10.64898…
#ComputationalBiology #ProteinDesign #ProteinEngineering #ProteinLanguageModels #MixtureOfExperts #Transformers #DeepLearning #Bioinformatics #PPI #DeNovoDesign
5
30
2,133

Jun 13
🔬 Mixture-of-Experts (MoE) — the architecture powering efficient scaling of frontier LLMs.
Just read this excellent technical white paper from @aasaitech on how sparse activation (router top-k experts) delivers massive capacity at far lower inference cost than dense models.
Key highlights: • Dynamic top-k routing (typically k=2) with expert specialization • Real-world models: Mixtral 8x7B, DeepSeek-MoE, Qwen-MoE, Grok-1 • 5-step flow: Input → Router → Active Experts → Compute → Combine • Industrial applications: multi-task agents, domain-specific reasoning (maintenance, quality, planning), cost-effective edge orchestration
MoE shines when you need high reasoning power without linear serving costs — perfect complement to RAG, CoT, and quantization in production systems.
Full white paper infographic: x.com/aasaitech/status/20653…
What’s your experience with MoE vs dense models in real deployments?
#MixtureOfExperts #MoE #LLMArchitecture #IndustrialAI #EdgeAI #AgenticAI

1
17
Jun 13
🔬 Deep dive into Mixture-of-Experts (MoE) architectures — one of the smartest ways to scale LLMs efficiently.
Just read this excellent technical white paper from @aasaitech breaking down how MoE delivers massive capacity with far lower inference costs than dense models of similar active parameters.
Key highlights: • Dynamic top-k routing (often k=2) • Expert specialization for better multi-task performance • Real-world models: Mixtral 8x7B, DeepSeek-MoE, Qwen-MoE, Grok-1 • Industrial applications: multi-task agents, domain-specific reasoning, cost-effective scaling
Perfect reference for anyone building production AI systems. MoE strong RAG/fine-tuning is becoming the go-to for industrial edge & orchestration.
Full white paper (with infographic): x.com/aasaitech/status/20653…
What’s your take on MoE vs dense models for real-world deployment?
#MixtureOfExperts #LLM #AIArchitecture #GenerativeAI #IndustrialAI
1
27

Kwai Keye-VL-2.0: Open-Source MoE Model for Ultra-Long Video Understanding
[LLMS]
MoE model processes ultra-long videos.
Why it matters: This model introduces a novel architectural approach to overcome computational and contextual challenges in processing hour-long videos. Its open-source nature and agentic intelligence capabilities could significantly advance multimodal AI applications, particularly in areas requiring deep temporal understanding.
Follow DailyAIWire for the full brief.
🤔 How will the efficient processing of ultra-long video contexts reshape the development of autonomous AI agents?
#MultimodalAI #MixtureOfExperts #LongVideoUnderstanding #OpenSourceAI #AgenticAI
1
37

Jun 10
Apple, 3세대 파운데이션 모델(AFM) 5종 공개, 온디바이스 희소 아키텍처로 진화한 Apple Intelligence
(by 9bow님)
d.ptln.kr/10635
#llm #apple #ondevice #mixtureofexperts #productlaunch #appleintelligence #privatecloudcompute
1
1
59

Jun 10
The future of AI may not be bigger models. 📏
It may be smarter, smaller, highly specialized models working together only when needed. 🧠✨
#AI #ArtificialIntelligence #MachineLearning #LLM #GenAI #ModularAI #MixtureOfExperts
1
10

Jun 4
MiniMax-M2 introduces a new generation of Mixture-of-Experts language models designed for efficient, agentic intelligence. Instead of activating massive numbers of parameters for every token, the MiniMax-M2 series uses a “mini activation” strategy, allowing the flagship M2.7 model to activate only around 10 billion parameters while still competing with much larger frontier AI systems.
In this video, we break down how MiniMax-M2 works, why small activated parameter counts matter, and how the model is optimized for real-world AI agents. You will learn about its MoE architecture, Forge RL training system, interleaved thinking, long-context reasoning, coding capabilities, deep search workflows, office automation, and self-evolution features.
This is not just another LLM release. MiniMax-M2 shows where modern AI model design is heading: efficient inference, agentic reasoning, autonomous debugging, and scalable intelligence with fewer active parameters.
Watch this video to understand how MiniMax-M2 could shape the next wave of AI agents and production-ready autonomous systems.
What You’ll Learn
↳ What makes MiniMax-M2 different from traditional dense LLMs
↳ How Mixture-of-Experts enables efficient intelligence
↳ Why mini activations matter for cost and speed
↳ How MiniMax-M2 supports coding, search, and automation agents
↳ What interleaved thinking means for agentic workflows
↳ Why self-evolving AI infrastructure is becoming important
SEO Keywords
MiniMax-M2, MiniMax M2 explained, Mixture of Experts, MoE language model, agentic AI, AI agents, autonomous AI, LLM architecture, Forge RL, interleaved thinking, long context AI, AI coding model, deep search AI, frontier AI models, efficient LLMs, autonomous agents, AI engineering, large language models, agentic intelligence
#MiniMaxM2 #AgenticAI #MixtureOfExperts #LLM #AIModels #AIAgents #ArtificialIntelligence #AIEngineering #GenerativeAI #AutonomousAI
1
2
104

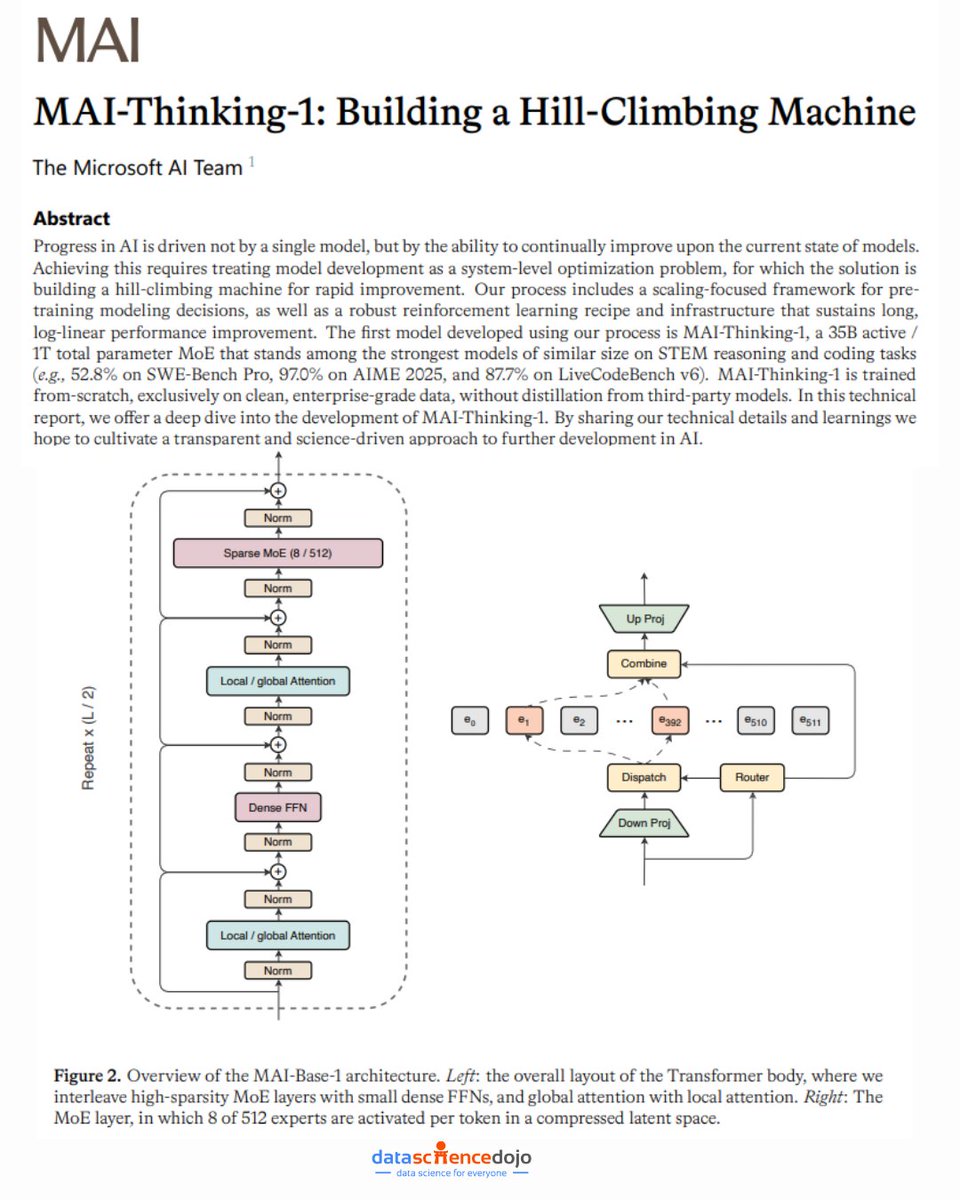
📢 Microsoft just released MAI-Thinking-1 — and the way they built it might matter more than the model itself.
Here's what they found:
- "Capabilities should be learned, not inherited" — they trained entirely from scratch with zero distillation from other models, betting that imitation limits long-term steerability
- A 35B active / 1T total parameter MoE that hits 97.0% on AIME 2025, 94.5% on AIME 2026, and 52.8% on SWE-Bench Pro — elite STEM and coding performance at a mid-size footprint
- RL that runs for thousands of steps — most labs hit a ceiling early; Microsoft built infrastructure specifically to sustain log-linear improvement over the long haul
- Three specialist models, one final model — separate RL climbs for STEM reasoning, agentic coding, and safety/helpfulness, then consolidated into a single deployment model
The core insight is treating model development as a continuous optimization loop — not a one-time training run. They call it a "hill-climbing machine": integrated data pipelines, RL environments, eval suites, and safety tests that turn every decision into a testable, empirical experiment.
What's counterintuitive? They deliberately avoided synthetic data during pre-training and excluded all open-source training datasets. In an era where everyone is recycling model outputs, Microsoft went the other way — 30T tokens of clean, human-generated, enterprise-grade data only.
If this approach scales, it means the next frontier isn't just a bigger model — it's a better process.
#AI #MachineLearning #LLM #ReinforcementLearning #MicrosoftAI #ReasoningModels #AIResearch #MixtureOfExperts #AIBenchmarks #STEM #AgenticAI #TechInnovation
1
4
12
1,195

May 19
$TAO FEEL GOOD! STAKE CONNITOAI !!! 👀👀
🚨 Why ConnitoAI (SN102) Will Obliterate What Templar (SN3) Achieved 💥
Templar pushed dense-model training hard — big 72B Covenant model with gradient syncing. Respect for the effort.
But it still suffered the classic decentralized headaches: heavy communication, coordination nightmares, expensive per miner, and scaling limits around 80B.
ConnitoAI was built different:
• True MoE architecture from the ground up
• Miners train only a few specialized experts locally on affordable GPUs
• ZERO communication during training
• Smart merging Proof-of-Loss validation
• Scales naturally to 100B parameters
• Composable experts perfect for agent swarms & continuous improvement
Templar fought the limitations of decentralization.
ConnitoAI embraced them and turned them into superpowers.
Real TaaS revenue coming Q3/Q4. Dashboard May 26. Research paper soon.
Feel good, stake ConnitoAI. 🐙💰
Who’s rotating to SN102? 👇
#Bittensor #DecentralizedAI #TAO $TAO $SOL #ConnitoAI #MixtureOfExperts #TaaS #AgenticAI #DeAI #Crypto #Web3
2
8
21
562
May 19
🚨 THE KRAKEN IS AWAKENING — CONNITOAI SN102 IS ABOUT TO EXPLODE! 🐙💥
Root APY is getting crushed toward 0% on purpose — why sit there like a bagholder when the real beast is rising?!
ConnitoAI (SN102) is unleashing decentralized 100B parameter training the way Bittensor always dreamed of:
• True MoE savage mode: Miners forge only a few specialized experts locally on cheap A6000 GPUs
• ZERO comms during training — pure efficiency
• Math POC already crushing it with real gains zero catastrophic forgetting 🔥
DASHBOARD DROPS IN JUST 7 DAYS (May 26) — the monster surfaces!
Full research paper incoming. TaaS platform Q3/Q4 for real paying customers.
Staking is INSANELY juicy right now:
• Extremely high early APY (thousands % spikes possible — low stake fat emissions)
• Super low entry point — tiny market cap = massive alpha rocket fuel as revenue hits
• Built for the agentic economy — specialist experts that keep compounding forever
Elite team. Working POC delivered. Research-first execution. This is the training factory that turns Bittensor into a frontier AI powerhouse.
STOP SLEEPING ON ROOT.
Deploy into the Kraken before May 26 and ride the next leg of $TAO!
RELEASE THE KRAKEN!!! 🐙🚀💥💥💥
Who’s loading SN102 before the dashboard? LFG 🚀🚀🚀
#Bittensor #DecentralizedAI #TAO $TAO $SOL #ConnitoAI #MixtureOfExperts #TaaS #AgenticAI #DeAI #Crypto #Web3 #Solana #AI
1
7
20
546
May 19
$TAO Smart money! ⬇️⬇️
🚨ConnitoAI SN 102💥
🚨 Why Smart Capital is Rotating from Root → ConnitoAI (SN102) Right Now
Root APY is being deliberately pushed toward 0% — it’s becoming a low-yield parking spot.
Meanwhile, ConnitoAI offers one of the strongest asymmetric staking setups in Bittensor today.
Why SN102 is standing out:
• True decentralized MoE training: Miners only train a few specialized experts locally (zero comms during training) on affordable GPUs → scales cleanly to 100B parameters.
• Already shipping proof: Math-domain POC delivered real gains with no catastrophic forgetting.
• Near-term catalysts: Dashboard launches May 26 (in 7 days) full research paper in 1-2 months.
Staking edge (especially attractive now):
• Extremely high early APY — thanks to low current stake strong emissions (many successful subnets deliver 40–100% APY, with early spikes much higher).
• Low entry point — still very small market cap, giving you massive room for alpha token upside as TaaS revenue starts flowing in Q3/Q4 2026.
• Perfect positioning for the agentic economy (dynamic specialist experts for agent swarms).
Elite tiny team (Isabella Liu George). Methodical research-first execution. Working POC already delivered.
Stop earning fading Root yield. Deploy into real decentralized frontier training with high yield low entry big upside.
This is how you position for the next leg in $TAO.
Easy play, be smart👇
#Bittensor #DecentralizedAI #TAO $TAO $SOL #ConnitoAI #MixtureOfExperts #TaaS #AgenticAI #DeAI #Crypto #Web3 #Solana #AI
2
5
12
470
May 18
$TAO New Era for AI 👀
🚨 ConnitoAI SN 102 💥
🚨 ConnitoAI (Bittensor SN102): The Decentralized Training Factory AI Has Been Waiting For
Most training subnets force old-school dense models onto Bittensor — high comms, coordination pain, and stuck at ~40-80B parameters.
ConnitoAI flips it with Mixture-of-Experts built for decentralization:
• Miners train only a few specialized “experts” locally on affordable GPUs (A6000 48GB).
• Zero communication during training.
• Smart merging later Proof-of-Loss validation.
• Scales cleanly to 100B parameters.
They already proved it works: math-domain POC showed targeted improvement with no catastrophic forgetting.
Roadmap (research-first):
• Full research paper in next 1-2 months
• Customer Training-as-a-Service (TaaS) platform in Q3-Q4 2026
• Companies pay for custom domain experts (healthcare, finance, defense, agents)
Perfect for the agentic economy — dynamic routing to reusable specialist experts that keep improving.
Revenue path: Pay-per-job subscriptions enterprise deals in a multi-hundred-billion AIaaS market.
Staking edge: Root APY is heading toward 0% on purpose. SN102 offers higher yields alpha token upside on a high-conviction subnet.
Early, credible, and architecturally unique. Isabella Liu’s team is executing methodically.
Decentralized frontier training is no longer sci-fi.
Evolution live on Bittensor! 👀
#Bittensor #DecentralizedAI #TAO $TAO #ConnitoAI #MixtureOfExperts #TaaS #AgenticAI #Crypto #Web3 $SOL
7
16
494
May 18
$TAO Primed for agents! 👀👀
🚨ConnitoAI SN 102💥
🚨 Why ConnitoAI (Bittensor SN102) is Prime for AI Agents & the Agentic Economy
The agentic economy is coming fast: autonomous AI agents that act, reason, collaborate, earn, and execute real tasks (trading, research, customer service, drug discovery, etc.). These agents need smarter, specialized, continuously improving brains — not just one giant general model.
ConnitoAI is uniquely positioned to power this:
1. Composable Mixture-of-Experts = Perfect Agent Routing
• Agents don’t need one massive monolithic model. They need specialists they can dynamically route to (e.g., a coding expert, a research expert, a negotiation expert, a finance expert).
• ConnitoAI’s decentralized MoE lets miners train reusable expert modules in parallel. The router intelligently picks the right expert(s) for each agent task.
• Result: Agents get specialist-level performance without catastrophic forgetting, while the overall system scales to 100B parameters.
2. Training-as-a-Service (TaaS) for Custom Agent Brains
• Coming Q3/Q4 2026: Companies and developers can pay the network to train custom domain experts on proprietary data.
• Perfect for agent teams: Train a private healthcare agent, a DeFi trading swarm, or a legal research agent — all decentralized, privacy-preserving, and continuously updatable.
• No more relying on closed models from OpenAI/Anthropic. Agents get sovereign, on-chain intelligence.
3. Decentralized Incentive-Aligned = Continuous Agent Improvement
• Traditional training is centralized and static. ConnitoAI turns model improvement into a global, permissionless market of expert contributors.
• Agents (or agent swarms) can keep feeding real-world feedback → better experts → stronger agents in a virtuous loop.
• Fits perfectly with Bittensor’s emerging agent ecosystem (inference subnets, memory subnets, tool-use subnets, etc.).
4. Scalability & Cost Efficiency at Frontier Level
• Other approaches struggle beyond 40-80B parameters due to coordination hell.
• ConnitoAI’s sparse training low-communication merging lets the network train true frontier-scale models cheaply across thousands of miners.
• Agents win: Cheaper inference better performance economic incentives for the whole stack.
Bottom line:
In the agentic future, the winners won’t be those with the biggest single model — but those with the best library of specialized, composable experts. ConnitoAI is building exactly that decentralized factory.
Research paper dropping soon (1-2 months), customer platform later 2026. Very early, but architecturally one of the strongest bets for powering the agent economy on Bittensor.
This is why SN102 deserves attention. 👀
LFG!!! 🚀🚀🚀
#Bittensor #DecentralizedAI #TAO $TAO $SOL #AgenticAI #AIAgents #MixtureOfExperts #TaaS #ConnitoAI #Web3
1
8
16
474
May 18
$TAO EVOLUTION! 👀
🚨ConnitoAI SN 102💥
🚨 How ConnitoAI (SN102) is Different from Other Training Subnets on Bittensor
Most training subnets try to do decentralized training the “old way” — forcing centralized architectures onto a decentralized network. ConnitoAI redesigned it from the ground up for true decentralization.
The Old Approach (e.g. Templar/SN3, Gradients, Teutonic, etc.):
• Miners usually train full models or large chunks of a dense model.
• High communication overhead (gradients, synchronizations, constant talking between nodes).
• Hits hard limits around 40B–80B parameters because one miner can’t handle bigger dense models.
• Relies on techniques like data parallelism, pipeline parallelism, or gradient compression (e.g. SparseLoCo in Templar’s 72B Covenant model).
• Good for big one-off pre-training runs, but coordination-heavy and expensive per miner.
ConnitoAI’s MoE-First Approach (the big differentiator):
• Built on Mixture of Experts (MoE) designed for decentralization.
• Each miner trains only a few specialized experts locally — no need to hold or train the full model.
• Zero communication during training — massive efficiency win.
• Updates merge later via smart weight-merging (DiLoCo-style) a shared expert for stability.
• Enables 100B parameter models (even trillions in theory) at much lower per-miner cost.
• Miners act like a global research team contributing reusable expert modules, not just rented GPUs.
• Long-term: composable expert marketplace real Training-as-a-Service (TaaS) for custom models.
Why this matters for Bittensor
Other subnets push the limits of traditional distributed training. ConnitoAI removes the core bottlenecks so the network can actually compete with (or surpass) centralized labs on frontier-scale models without massive coordination pain.
It’s not another “train a big model once” play — it’s building the permanent decentralized training factory Bittensor has been missing.
Research paper coming in 1-2 months to prove it. Very early, but architecturally unique.
Keep evolving!👀
LFG !!!! 🚀🚀🚀
#Bittensor #DecentralizedAI #TAO $TAO $SOL #MixtureOfExperts #TaaS #ConnitoAI #AI #Crypto #Web3
6
18
549
May 18
$TAO BREAKING BARRIERS! ⬇️⬇️
💥ConnitoAI SN 102 💥
🚨 Decentralized AI just got its missing piece.
ConnitoAI (Bittensor SN102) is tackling the hardest problem in the entire Bittensor stack: training massive 100B parameter frontier models across thousands of independent miners — without anyone needing a supercomputer or constant coordination.
Why this is a perfect fit for decentralized AI Bittensor:
Traditional distributed training forces centralized-style architectures onto a decentralized network. It hits walls fast — high communication costs, coordination nightmares, and single miners can’t handle models beyond ~40-80B parameters. Bittensor would always play catch-up to OpenAI-style labs.
ConnitoAI flips the script. They redesigned everything from the ground up with Mixture of Experts (MoE) built for decentralization:
• Each miner trains only a few specialized “experts” locally on their own hardware.
• Zero communication during training — huge efficiency win.
• Smart weight-merging (DiLoCo-style) brings it all together later.
• A shared expert keeps everything stable.
Result? Lower costs per miner, massive scalability to 100B (even trillions eventually), and true peer-to-peer incentives. Miners act like a global research team, not just rented GPUs. This creates the training factory Bittensor needs to complement all the inference subnets and unlock real Training-as-a-Service (TaaS).
✅ Whitepaper V1 out (May 2026)
✅ Full research paper in next 1-2 months (deep technical dive)
✅ Customer platform paying TaaS in Q3-Q4 2026
A tiny elite team (Isabella George) is going research-first to do it right. No hype — just solid infrastructure for custom models in healthcare, defense, finance & more.
The future of AI training isn’t locked in one data center. It’s decentralized on Bittensor — and ConnitoAI is building the engine.
On-chain 100B models are coming BIG TIME! 👀
LFG!!! 🚀🚀🚀
#Bittensor #DecentralizedAI #TAO $TAO $SOL #MixtureOfExperts #AI #Crypto #Web3 #TaaS
8
19
825
May 13
$TAO 🚨UNLEASH THE KRAKEN🔥
LFG!!! 🚀🚀🚀🚀
#Bittensor #TAO #ConnitoAI #DeAI #MixtureOfExperts $TAO $SOL $CONNITO
May 12

We’re excited to share the Connito whitepaper V1: a framework for decentralized, composable MoE adaptation.
We trains sparse expert subsets, validates updates through Proof-of-Loss, and turns open-model improvement into a distributed expert-level market.
Read the whitepaper: connito.ai/whitepaper
3
5
22
762
May 13
$TAO 🚨WHITEPAPER 🔥
ConnitoAI SN 102 ⬇️⬇️
#Bittensor #TAO #ConnitoAI #DeAI #MixtureOfExperts $TAO $SOL $CONNITO
May 12
We’re excited to share the Connito whitepaper V1: a framework for decentralized, composable MoE adaptation.
We trains sparse expert subsets, validates updates through Proof-of-Loss, and turns open-model improvement into a distributed expert-level market.
Read the whitepaper: connito.ai/whitepaper
4
20
903
May 12
$TAO 🚨释放海妖!!💥
CONNITOAI SN 102 ⬇️⬇️
白皮书今天发布。这头猛兽要挣脱锁链了。系好安全带,他妈的!ROOT 上别在那儿哭哭啼啼!
这可不是什么叙事游戏或者刷点农场。
这是整个 Bittensor 生态系统一直渴望的狂野工程巨兽:去中心化训练 1000 亿 参数的 MoE 模型,一劳永逸地彻底消灭灾难性遗忘。
孤立的专家以手术般的精度完美嵌入。零干扰。每一次交互都在锻造永久的、复合增长的智能——构建一个活的、不可阻挡的知识帝国,而不是 usual 那种脆弱的擦除重置狗屎。
这彻底翻转了整个游戏。从租用弱鸡、临时的 API 残羹冷炙,变成拥有一个自我强化、领域特定的智能层,而且每用一次就变得更凶猛。
企业定制化市场——长期被困在软趴趴的通用模型和百万美元咨询监狱之间——刚刚拿到它的暴力突破武器。一条可扩展、可累积的中间道路,带来真正持久的 alpha。
Proof-of-Loss 验证。Top-N 融合。无情干净的架构。极低的矿工门槛。全都由 Isabella Liu 用她 OpenTensor 核心精英血统在烈火中锻造而成。
今天的白皮书就是那把巨大的去风险铁锤。信号刚刚进入核爆模式——更大、更聪明的资本即将涌入大门。
Bittensor 一直渴望的训练层正在释放。Alpha 已上线。仪表盘 5 月 26 日上线。海妖今天浮出水面。
我们依然处于从脆弱的单体恐龙向真正去中心化专家网络暴力转型的极早期阶段,荒谬地、离谱地早。
就是它了。别睡着。
相应地建仓——而且他妈的眼睛都别眨一下。
connito.ai
#Bittensor #TAO #ConnitoAI #DeAI #MixtureOfExperts $TAO $SOL $CONNITO
5
20
831
May 12
$TAO 🚨LIBÉREZ LE KRAKEN !! 💥
CONNITOAI SN 102 ⬇️⬇️
Le whitepaper sort aujourd’hui. La bête se déchaîne. Accrochez vos ceintures, putain ! Pas de pleurnicheries sur ROOT !
Ce n’est pas un simple jeu narratif ou une ferme à points.
C’est la bête d’ingénierie sauvage que tout l’écosystème Bittensor attendait désespérément : l’entraînement décentralisé de modèles MoE de plus de 100 milliards de paramètres qui élimine une bonne fois pour toutes l’oubli catastrophique.
Les experts isolés s’intègrent avec une précision chirurgicale. Zéro interférence. Chaque interaction forge une intelligence permanente et cumulative — construisant un empire vivant et imparable de connaissances au lieu des habituelles conneries d’effacement fragile et de réinitialisation.
Ça change complètement la donne. Du simple fait de louer des miettes d’API faibles et temporaires à la possession d’une couche d’intelligence auto-renforçante et spécifique à un domaine qui devient plus féroce à chaque utilisation.
Le marché de la personnalisation entreprise — longtemps piégé entre des modèles génériques mous et des prisons de consulting à un million de dollars — vient de recevoir son arme de percée violente. Un chemin intermédiaire scalable et cumulatif qui délivre un vrai alpha durable.
Validation Proof-of-Loss. Fusion Top-N. Architecture d’une propreté impitoyable. Faibles barrières pour les mineurs. Tout forgé dans le feu par Isabella Liu avec ce pedigree d’élite du core d’Opentensor.
Le whitepaper d’aujourd’hui est le marteau massif de dérisquage. Le signal vient de passer au nucléaire — et un capital plus gros et plus intelligent est sur le point d’inonder les portes.
La couche d’entraînement que Bittensor réclamait désespérément est en train de se libérer. Alpha live. Dashboard le 26 mai. Le Kraken émerge aujourd’hui.
Nous sommes encore absurdement, ridiculement tôt dans le virage violent des dinosaures monolithiques fragiles vers de vrais réseaux d’experts décentralisés.
C’est celui-là. Ne dormez pas.
Positionnez-vous en conséquence — et n’osez surtout pas cligner des yeux.
connito.ai
#Bittensor #TAO #ConnitoAI #DeAI #MixtureOfExperts $TAO $SOL $CONNITO
7
25
445
May 12
$TAO 🚨RELEASE THE KRAKEN!! 💥
CONNITOAI SN 102 ⬇️⬇️
Whitepaper drops today. The beast is breaking loose. Buckle the fuck up. No whimpering on ROOT!
This isn’t some narrative play or points farm.
This is the savage engineering beast the entire Bittensor ecosystem has been starving for: decentralized training of 100B MoE models that obliterates catastrophic forgetting once and for all.
Isolated experts slot in with surgical precision. Zero interference. Every single engagement forges permanent, compounding intelligence — building a living, unstoppable empire of knowledge instead of the usual fragile wipe-and-reset bullshit.
This flips the entire game. From renting weak, temporary API scraps to owning a self-reinforcing, domain-specific intelligence layer that grows fiercer with every use.
The enterprise customization market — long trapped between limp generic models and million-dollar consulting prisons — just got its violent breakout weapon. A scalable, compounding middle path that delivers real, lasting alpha.
Proof-of-Loss validation. Top-N merging. Ruthlessly clean architecture. Low miner barriers. All forged in fire by Isabella Liu with that elite Opentensor core pedigree.
Today’s whitepaper is the massive derisking hammer. The signal just went nuclear — and bigger, smarter capital is about to flood the gates.
The training layer Bittensor has been desperately craving is unleashing. Alpha live. Dashboard May 26. The Kraken surfaces today.
We are still absurdly, ridiculously early on the violent shift from fragile monolithic dinosaurs to true decentralized expert networks.
This is the one. Don’t sleep.
Position accordingly — and don’t you dare blink.
connito.ai
#Bittensor #TAO #ConnitoAI #DeAI #MixtureOfExperts $TAO $SOL $CONNITO
4
10
40
831