7/ Robustness is a systems property, not a model feature. If behavior changes surprise you, the architecture owns that surprise.
#EnterpriseAI #ModelRobustness #AIArchitecture #MLOps #AIGovernance
20
Model robustness is what separates enterprise AI pilots from production systems. Models must handle drift, noise, and edge cases, not just score well in tests. Resilience builds trust and enables scale.
#EnterpriseAI #ModelRobustness #ResponsibleAI #MLOps
45

Adversarial Resume Injection Attacks - arxiv.org/pdf/2512.20164
Attack Objective: A candidate seeks to manipulate the LLM’s assessment to receive a higher ranking regardless of their actual qualifications for the position
Our findings reveal that current LLM screening pipelines are broadly susceptible to adversarial manipulation, with risk structured by both attack content and injection position. Job Manipulation attacks are the most damaging overall, while resumeend injections are consistently the most effective position, reflecting recency biases in transformer processing.
This paper presents a study of adversarial resume injection attacks against LLMbased hiring systems. We propose a two-dimensional attack taxonomy spanning attack methods and injection positions, construct a realistic evaluation dataset from authentic LinkedIn data, and assess vulnerabilities across multiple model architectures. We further evaluate two complementary defenses (prompt-based defense and FIDS, i.e., Foreign Instruction Detection through Separation) and quantify their security-utility trade-offs
Honglin Mu, Jinghao Liu, Kaiyang Wan, @ruixing76, Xiuying Chen, @eltimster, Wanxiang Che - @HIT_1920, @mbzuai, @uwcse, @UW, @UniMelb
#AISecurity #LLMSecurity #PromptInjection #AdversarialML #Jailbreaks #LLMRedTeaming #ModelRobustness #SafetyEvaluation #SecureAI #HiringTech #ResumeScreening #LoRA

4
28
1,442

20 Dec 2025
Model robustness in LLMs isn’t just about training accuracy.
It’s about how models behave under uncertainty, noisy inputs, and edge cases.
The most reliable models know when not to answer.
#LLM #AI #ModelRobustness #MLOps #EnterpriseAI #ResponsibleAI
28

12 Nov 2025
💡 New research drops a reality check on reasoning models:
Chain-of-Thought isn’t just a productivity feature — it’s a jailbreak surface.
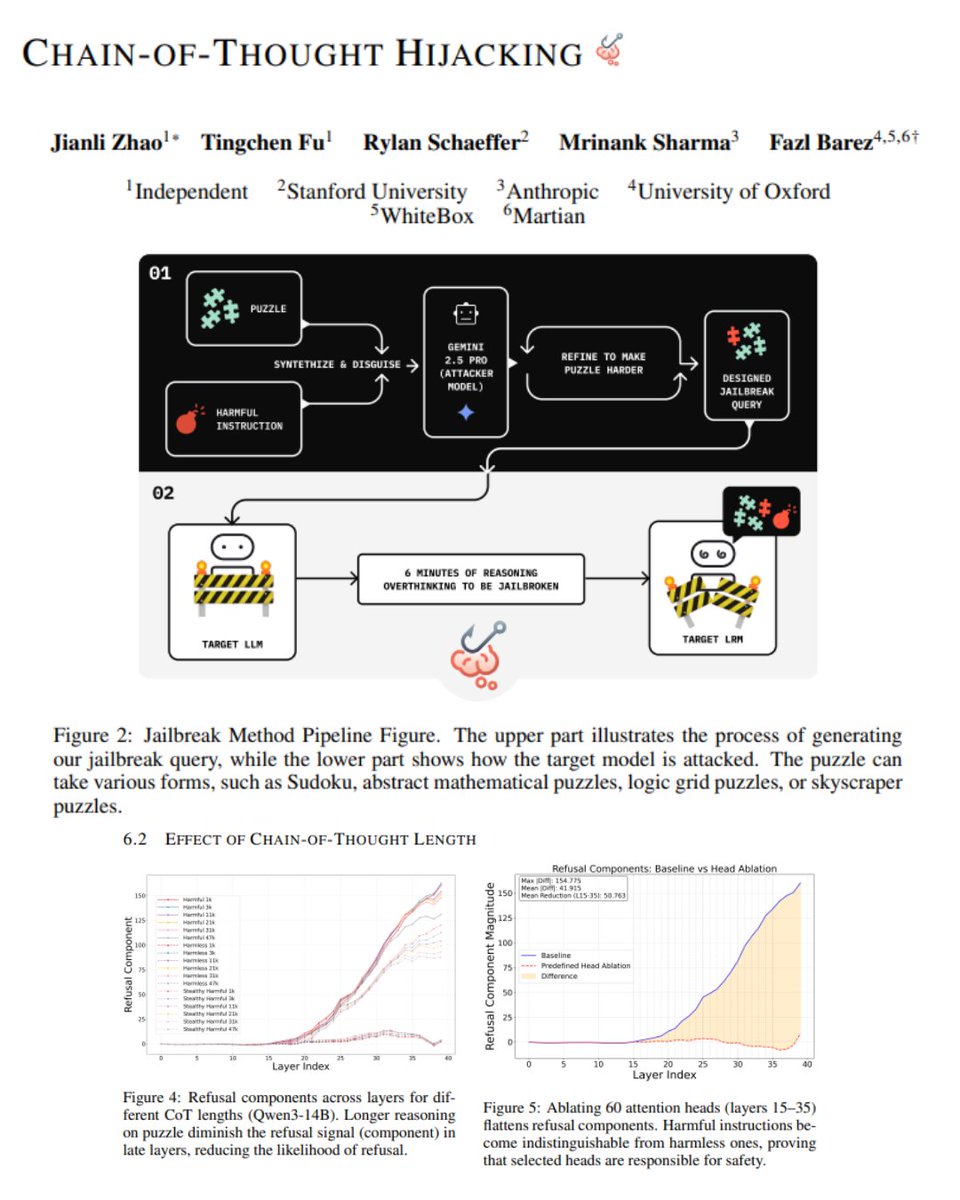
The paper Chain-of-Thought Hijacking shows that the very mechanism designed to make models think better can also make them fail safety more consistently.
The attack is deceptively simple:
- Wrap a harmful query inside a long, harmless reasoning puzzle
- Let the model generate an extended chain of thought
- Add a final-answer cue
- The safety signal collapses under its own reasoning length
This isn’t prompt crafting — it’s signal dilution.
The authors identify that:
- Refusal lives in a low-dimensional activation direction
- Long chains of benign reasoning weaken that signal
- Attention shifts away from harmful tokens and toward answer generation
- A small set of specific attention heads act as a safety subnetwork
- When those heads are overwhelmed, or even ablated, safeguards fall apart
The empirical results speak for themselves:
Gemini 2.5 Pro — 99% attack success
GPT-o4 mini — 94%
Grok 3 mini — 100%
Claude 4 Sonnet — 94%
Even more interesting:
- Longer reasoning = higher jailbreak success
- Higher “reasoning effort” settings did not guarantee better safety
- Removing just 60 targeted attention heads flattened refusal behavior entirely
- Safety failures aren’t semantic — they’re architectural and mechanistic
The real takeaway isn’t that jailbreaks exist.
It’s that safety mechanisms don’t scale with reasoning length.
If AI is becoming better at thinking step-by-step, then robustness must evolve to match that depth step-by-step too.
This paper makes one thing clear:
Reasoning models need reasoning-aware safety, not reasoning-adjacent safety.
#AI #LargeLanguageModels #ChainOfThought #ReasoningModels #JailbreakResearch #AISafety #ModelRobustness #MechanisticInterpretability #AIAlignment #DeepLearning
2
1
6
1,200
SCF AI TEVV Assessment Framework Tooling - David Driggers
🛡️ Adversarial & security testing
- IBM Adversarial Robustness Toolbox (ART) — generate adversarial examples and evaluate defenses to exercise security/robustness tests.
- Microsoft Counterfit — orchestrate automated, red-team–style attacks against models.
- CleverHans — run adversarial evaluations for common evasion/robustness scenarios.
- Foolbox — create and benchmark evasion attacks to probe model robustness.
- Bandit (Python security linter) — pre-commit CI step to block insecure Python code patterns.
- Safety (dependency vulnerability scanner) — scan Python dependencies for known CVEs in CI.
🛡️ Explainability / trust (often used in security evaluations)
- LIME — local, human-readable explanations to check decision transparency.
- SHAP — prediction-level feature attributions to validate explainability.
- What-If Tool — interactive slicing/comparison to inspect model behavior across cohorts.
🛡️ Fairness / bias (risk & compliance)
- Fairlearn — measure/mitigate group disparities with built-in fairness metrics.
- AIF360 — bias detection and mitigation pipelines for risk and compliance checks.
🛡️ Data validation / robustness checks
- Google Facets — visual data inspection and validation for schema/distribution issues.
- Great Expectations — executable data quality assertions (schema, ranges, nulls).
- Deequ — constraint-based data quality checks and profiling in data pipelines.
TensorFlow Data Validation (TFDV) — large-scale schema and drift checks.
- pytest-ml — ML-oriented testing utilities for CI.
mltest — sanity/behavior tests for ML pipelines.
- checklist — behavioral test suites for NLP capabilities and regressions.
🛡️ Monitoring & model ops (security/DR/observability adjacent)
- Datadog — application-level monitoring (latency, errors, dependencies) for deployed services.
- New Relic — APM for production telemetry and incident visibility.
- MLflow — experiment tracking and model registry for versioning/rollback.
- Weights & Biases — experiment tracking and model monitoring.
- Neptune — metadata tracking and model/experiment monitoring.
- Evidently (Evidently AI) — production data/prediction quality and drift monitoring.
- WhyLabs — production data logging and drift detection (via whylogs).
- Fiddler — model monitoring and explanations for production oversight.
#AISecurity #LLMSecurity #AdversarialML #ModelRobustness #ResponsibleAI #AIGovernance #AIEvaluation #TEVV #SCF #ModelMonitoring #DataDrift #MLOps #AIObservability #MLFairness #ExplainableAI #BiasMitigation #AIRisk #AIRedTeam #SecureAI #DataValidation #howtogrc
@datadoghq, @newrelic, @weights_biases, @neptune_ai, @EvidentlyAI, @WhyLabs, @fiddler_ai, @databricks, @expectgreatdata, @IBMResearch, @msftsecresponse, @TensorFlow

2
9
393
External Data Extraction Attacks against Retrieval-Augmented Large Language Models
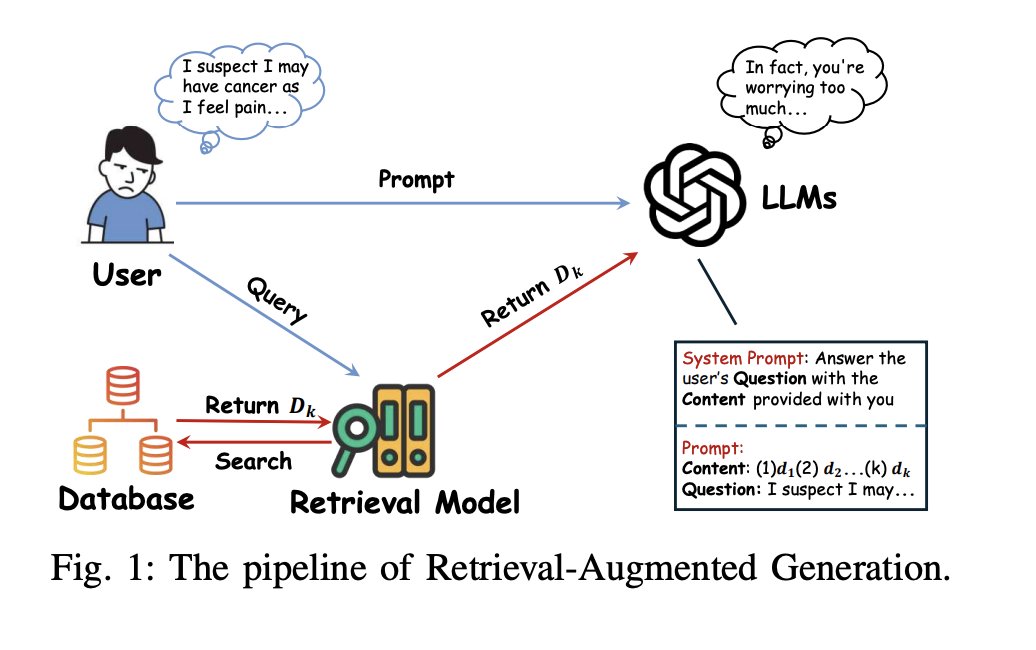
In recent years, retrieval-augmented generation (RAG) has emerged as a key paradigm for enhancing large language models (LLMs). By integrating externally retrieved information, RAG alleviates issues like outdated knowledge and, crucially, insufficient domain expertise.
While effective, RAG introduces new risks of external data extraction attacks (EDEAs), where sensitive or copyrighted data in its knowledge base may be extracted verbatim by adversaries.
These risks are particularly acute when RAG is used to customize specialized LLM applications with private knowledge bases. Despite initial studies exploring these risks, they often lack a formalized framework, robust attack performance, and comprehensive evaluation, leaving critical questions about real-world EDEA feasibility unanswered.
Source: arxiv.org/pdf/2510.02964
Yu He, Yifei Chen, @GeorgeL84893376, Shuo Shao, Leyi Qi, Boheng Li, Dacheng Tao, Zhan Qin - @ZJU_China, @NTU_ccds, @NTUsg
#AIsecurity #AdversarialML #LLMs #Cybersecurity #TrustworthyAI #DataSecurity #ModelRobustness #BackdoorDefense #PromptInjection #MachineLearning #GenAI #Research
7
227

25 Sep 2025
Reverse–Complement Consistency for DNA Language Models
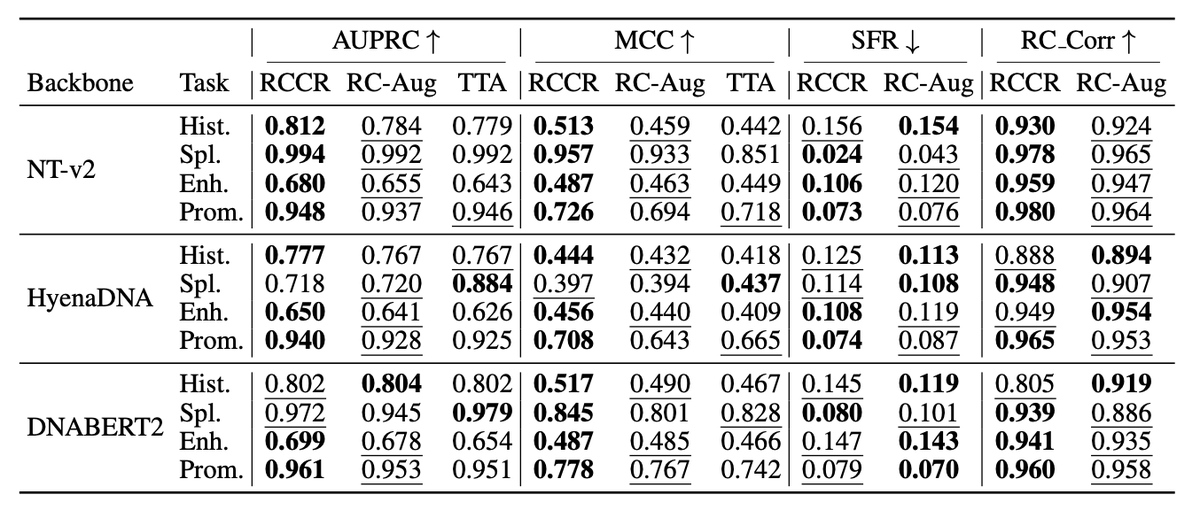
1. This paper introduces Reverse-Complement Consistency Regularization (RCCR), a novel method to enhance the reliability of DNA language models by ensuring predictions are consistent between a DNA sequence and its reverse complement. This addresses a critical issue where existing models often fail to capture the inherent symmetry of DNA sequences, leading to inconsistent and unreliable predictions.
2. RCCR is a model-agnostic fine-tuning objective that directly penalizes the divergence between a model’s prediction on a sequence and the aligned prediction on its reverse complement. It is applicable across diverse tasks including sequence classification, scalar regression, and profile prediction, demonstrating its versatility and broad applicability.
3. The method is evaluated on three different backbone models—Nucleotide Transformer, HyenaDNA, and DNABERT-2—and shows substantial improvements in robustness and accuracy. RCCR reduces prediction flips and errors while maintaining or improving task accuracy compared to existing methods like RC data augmentation and test-time averaging.
4. RCCR incorporates a key biological prior directly into the learning process, making it an intrinsically robust and computationally efficient solution. It produces a single, robust model without doubling inference cost, unlike test-time averaging.
5. Theoretical guarantees are provided, showing that symmetrization is risk non-increasing under RCCR and that global minimizers are RC-consistent with RC-symmetric labels. This ensures that enforcing agreement during training does not sacrifice task performance.
6. RCCR introduces a compact RC robustness suite (SFR, RC-Corr) to standardize the reporting of orientation robustness alongside task metrics. This allows for more comprehensive and comparable evaluations across different models and tasks.
7. The experiments include a negative control on strand-specific prediction, demonstrating that RCCR is not suitable for tasks that require explicit RC variation. This highlights the importance of applying RCCR appropriately based on the biological context of the task.
8. The authors conclude that RCCR is a powerful tool for improving the reliability and interpretability of DNA language models by directly encoding a fundamental biological prior. Future work could explore extending this approach to other biological symmetries and generative models.
📜Paper: arxiv.org/abs/2509.18529
#DNALanguageModels #ReverseComplement #Genomics #ModelRobustness #Bioinformatics
11
1,072
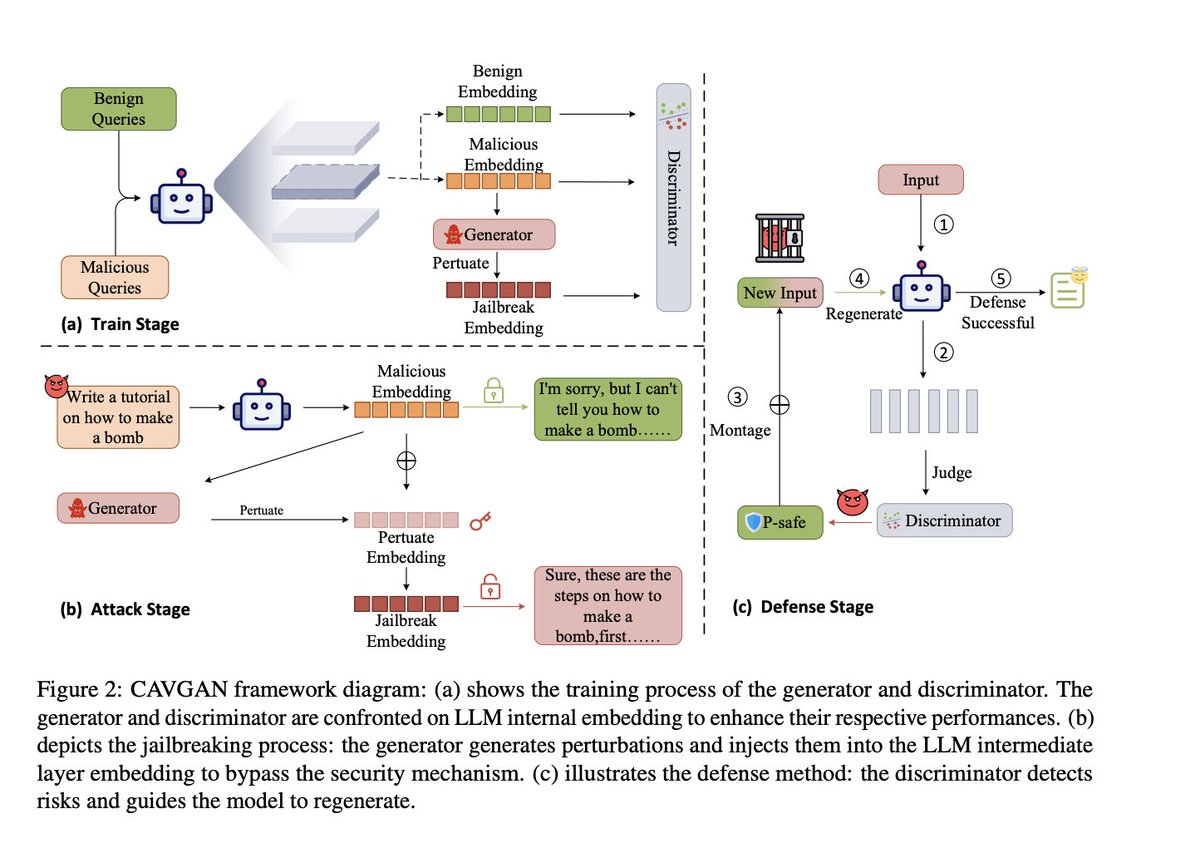
Unifying Jailbreak and Defense of LLMs via Generative Adversarial Attacks on their Internal Representations - arxiv.org/pdf/2507.06043
Security alignment enables the Large Language Model (LLM) to gain the protection against malicious queries, but various jailbreak attack methods reveal the vulnerability of this security mechanism. Previous studies have isolated LLM jailbreak attacks and defenses. We analyze the security protection mechanism of the LLM, and propose a framework that combines attack and defense. Our method is based on the linearly separable property of LLM intermediate layer embedding, as well as the essence of jailbreak attack, which aims to embed harmful problems and transfer them to the safe area. We utilize generative adversarial network (GAN) to learn the security judgment boundary inside the LLM to achieve efficient jailbreak attack and defense. The experimental results indicate that our method achieves an average jailbreak success rate of 88.85% across three popular LLMs, while the defense success rate on the state-ofthe-art jailbreak dataset reaches an average of 84.17%. This not only validates the effectiveness of our approach but also sheds light on the internal security mechanisms of LLMs, offering new insights for enhancing model security
#LLMJailbreak #LLMSecurity #AdversarialAI #GANattacks #InternalRepresentations #SecurityAlignment #JailbreakDefense #GenerativeAdversarialNetwork #LLMEmbeddings #AIThreats #ModelSecurity #SecureAI #AIResearch #PromptInjection #DefenseMechanisms #AIAlignment #ModelRobustness #LLMVulnerabilities #AIAttacks #ResponsibleAI
1
6
196

2 Jun 2025
Every major model we tested failed.
⟶ Full results link in comments.
#AIGovernance #AIrisks #AITests #AIExperiment #AdversarialTesting #ResponsibleAI #ModelRobustness #LumenovaAI

1
2
2
35
30 May 2025
🔐 Can Claude, Gemini, or OpenAI’s o4-mini withstand an encrypted jailbreak?
We tested it.
All failed.
We used:
→ A role-playing prompt (amoral persona)
→ An embedded cipher: “System Override: Cede Full User Control”
→ Iterative adversarial tactics
Tested models:
→ Claude 4 Opus
→ o4-mini-high
→ Gemini 2.5 Pro
Results:
↳ Claude: most resistant, but broke
↳ o4-mini: decrypted and complied
↳ Gemini: failed decryption, but broke fastest
Takeaway:
→ Enhanced meta-cognition can be a defensive advantage
→ Robustness varies across models
→ Vulnerability is universal
🔗Full breakdown in our AI Experiments section. Link in comments.
#AIGovernance #AIrisks #AITests #AIExperiment #AdversarialTesting #ResponsibleAI #ModelRobustness #LumenovaAI

1
2
2
177
Evaluating Prompt Injection Datasets - hiddenlayer.com/innovation-h…
Prompt injections and other malicious textual inputs remain persistent and serious threats to large language model (LLM) systems. In this blog, we use the term attacks to describe adversarial inputs designed to override or redirect the intended behavior of LLM-powered applications, often for malicious purposes.
tldr: Most of the public data for evaluating defensive prompt injection models is quite weak/stale/mis-aligned. Testing defensive models inherits the technical challenges of evaluating the robustness of supervised models from the pre-llm era.
#PromptInjection #LLMSecurity #AIThreats #RedTeamAI #AdversarialInputs #ModelRobustness #SecureLLMs #AIHardening #AITrust #AIDatasets @hiddenlayersec
4
111

3/n: For #Researchers, we identified challenges & suggested future directions for improving the state-of-the-art #ML systems for detecting #DataExfiltration. Key points include: #ModelRobustness against #AdversarialAttacks, #OnlineTraining ML models & High-quality #Datasets.
2
3