Constraint-Aware Optimization for Robust Protein Stability Prediction
1. The paper proposes an optimization-level framework (no architecture changes) to improve robustness of multimodal protein stability (ΔΔG) predictors built on the SPURS-style backbone (ESM2 sequence ProteinMPNN structure, fused per-residue features, MLP head with ΔΔG = score(mut) − score(wt)).
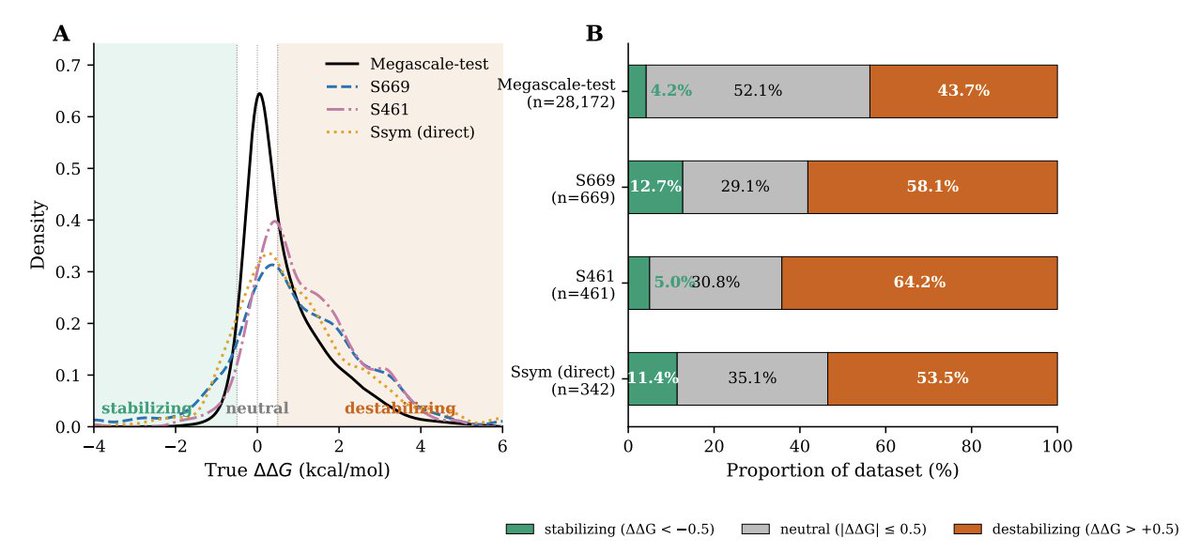
2. Core motivation: strong in-distribution performance on Megascale does not translate to out-of-distribution (OOD) proteins; datasets are heavily label-imbalanced (stabilizing mutations are rare, ~4–13% across common benchmarks), and predictors show persistent forward–reverse bias on paired-mutation tests (Ssym).
3. The framework combines three losses that target different failure modes: (i) Balanced MSE (BMC) to counter ΔΔG label imbalance, (ii) a Siamese anti-symmetric regularizer to encourage thermodynamic reversibility, and (iii) a new OOD-margin consistency loss that penalizes prediction sensitivity to small perturbations of the per-position fused representation.
4. Headline OOD results across 3 seeds and 11 benchmarks: Spearman on S669 improves from 0.486 to 0.540 (σ=0.002), and on S461 from 0.653 to 0.711. Additional smaller gains are reported on S8754, S2648, S4346, and Ssym-direct; performance drops modestly on in-distribution Megascale-test (0.749 → 0.713), interpreted as a robustness tradeoff.
5. BMC is used as a distribution-aware regression objective with a learnable noise scale, designed to increase gradient pressure on underrepresented ΔΔG regions (especially stabilizing tail) rather than letting MSE/Huber be dominated by neutral/destabilizing examples.
6. The Siamese anti-symmetric loss is applied by evaluating both wt→mut and mut→wt with shared weights and penalizing (f→ f←)^2. Ablations suggest it contributes additively with BMC on the hardest OOD sets, but it can hurt ΔTm benchmarks (e.g., S571), consistent with ΔTm not obeying the same magnitude constraints as ΔΔG.
7. The OOD-margin loss is a representation-stability regularizer: add small Gaussian noise to the fused residue representation after the encoder forward pass, re-run only the MLP head, and penalize (ŷclean − ŷnoisy)^2. It adds ~10% per-step training cost and shows a localized optimum around noise scale σ≈0.20 (too large degrades both OOD gains and in-distribution fit).
8. Mechanistic diagnostic on Ssym: anti-symmetric training does not eliminate systematic forward–reverse bias (offsets remain ~0.3–0.4 kcal/mol). The paper argues gains mainly come from implicit regularization/optimization dynamics rather than strict enforcement of thermodynamic constraints; even an explicit bias-corrected anti-symmetry loss reduces bias but does not improve OOD Spearman.
9. Practical engineering angle: for retrieving rare stabilizing mutations (ΔΔG ≤ −0.5) on S669, the combined objective improves top-50% stabilizing recall (0.659 → 0.685), suggesting better candidate yield in typical screening-style prioritization where the stabilizing tail matters more than average error near neutrality.
10. Negative results help delineate what does not help OOD here: auxiliary multitask supervision with K50 adds little (ΔΔG already highly correlated with K50), and ProteinMPNN-based structural relaxation/perturbation features did not improve key wild-type-based OOD sets (S669/S461), reinforcing that optimization behavior itself can be a bottleneck.
💻Code: github.com/shiv-ram-repo/con…
📜Paper: arxiv.org/abs/2606.08100
#ProteinStability #DDG #ProteinEngineering #ComputationalBiology #MachineLearning #FoundationModels #OODGeneralization #RepresentationLearning #ESM2 #ProteinMPNN
5
28
1,668
Multi-Task Fine-Tuning Enables Robust Out-of-Distribution Generalization in Atomistic Models
1. A new study proposes multi-task fine-tuning (MFT) to enhance the out-of-distribution (OOD) generalization of atomistic models, addressing a critical issue in molecular and materials design where models often fail to generalize beyond known data regimes.
2. The research identifies a key problem: standard fine-tuning of pretrained models leads to "representation collapse," erasing crucial chemical and structural priors learned during pretraining and severely degrading OOD performance.
3. MFT jointly optimizes downstream property prediction with a physically grounded force-field objective inherited from pretraining, preserving essential chemical priors while allowing task-specific adaptation.
4. Across various molecular and materials benchmarks, MFT consistently improves OOD generalization, approaching the theoretical limit set by in-distribution accuracy and outperforming standard fine-tuning and state-of-the-art task-specific models.
5. The study demonstrates that MFT mitigates representation collapse, maintaining clear separation of atomic and edge representations, which is crucial for robust OOD performance.
6. MFT also enhances data efficiency, achieving strong OOD performance even with limited training data, making it highly practical for real-world applications where labeled data is scarce.
7. The findings highlight the importance of balancing representation stability and plasticity during fine-tuning, offering insights for designing next-generation atomistic models for reliable scientific discovery.
📜Paper: arxiv.org/abs/2601.08486v1
#AtomisticModels #MultiTaskFineTuning #OODGeneralization #MolecularDesign #MaterialsScience

1
2
18
2,031

19 Nov 2025
🤔 Have you ever wondered what’s actually on the surface of Mars?
🌊 Do you think Mars might have had water millions of years ago?
In collaboration with the @NASAJPL, we introduce Mars-Bench, the first benchmark that helps us answer such questions using machine learning. Our paper has been accepted at @NeurIPSConf 2025; discover more about Mars-Bench:
📄 Paper - arxiv.org/pdf/2510.24010
🌐 Project page - mars-bench.github.io/
#Mars #MarsScience #MarsExploration #SpaceExploration #SatelliteData #RoverData #NASA #JPL #Research #PlanetaryScience #EarthandPlanetaryScience #RemoteSensing #GeospatialAI #FoundationModels #Benchmarking #DistributionShift #OODGeneralization #NeurIPS2025 #ComputerVision #AI4Science

1
4
16
1,822

31 Oct 2025
Dynamically Assembling Biological Intelligence to Predict Novel Cellular Phenotypes
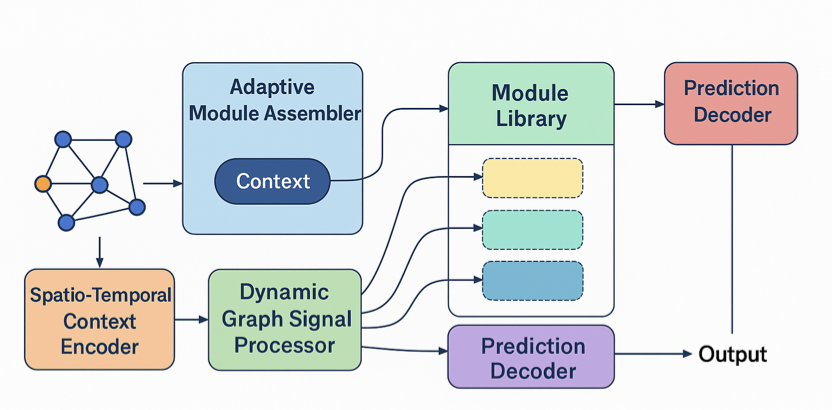
1. The article introduces Bio-AMLM, a groundbreaking framework designed to enhance out-of-distribution (OOD) generalization in predicting cellular responses. Unlike traditional models, Bio-AMLM dynamically constructs a bespoke analytical pipeline for each biological query, leveraging a library of pre-trained, functionally specialized biological modules.
2. The core innovation of Bio-AMLM lies in its Adaptive Inference Planner. This planner, guided by a biological context encoder, intelligently selects, configures, and links specialized modules to form an optimal analysis chain. This dynamic assembly allows the model to adapt its analytical logic to new types of biological problems, significantly improving its robustness and accuracy.
3. Bio-AMLM was rigorously tested on several challenging bio-simulation benchmarks, including Gene-Edit-Bench, Drug-Response-Bench, and Toxicity-Bench. The results were impressive: Bio-AMLM consistently outperformed state-of-the-art approaches, demonstrating superior performance in predicting cellular behavior under complex OOD conditions.
4. The framework's modular nature not only enhances its adaptability but also improves interpretability. Domain experts rated Bio-AMLM highly for its interpretability and robustness in novel tasks, finding the visualized analysis chain highly insightful for downstream wet-lab experiments.
5. Future work will focus on expanding the biological module library to include modules for immunology and single-cell transcriptomics, exploring reinforcement learning for the inference planner, and validating Bio-AMLM's predictions through prospective wet-lab experiments.
📜Paper: biorxiv.org/content/10.1101/…
#BioAMLM #ComputationalBiology #OODGeneralization #DynamicAssembly #BiologicalPrediction
6
1,490
16 Jun 2025
Robust Molecular Property Prediction via Densifying Scarce Labeled Data
1.A key challenge in drug discovery is predicting properties of out-of-distribution (OOD) molecules using models trained on limited, in-distribution (ID) labeled data. This paper proposes a meta-learning approach to address that.
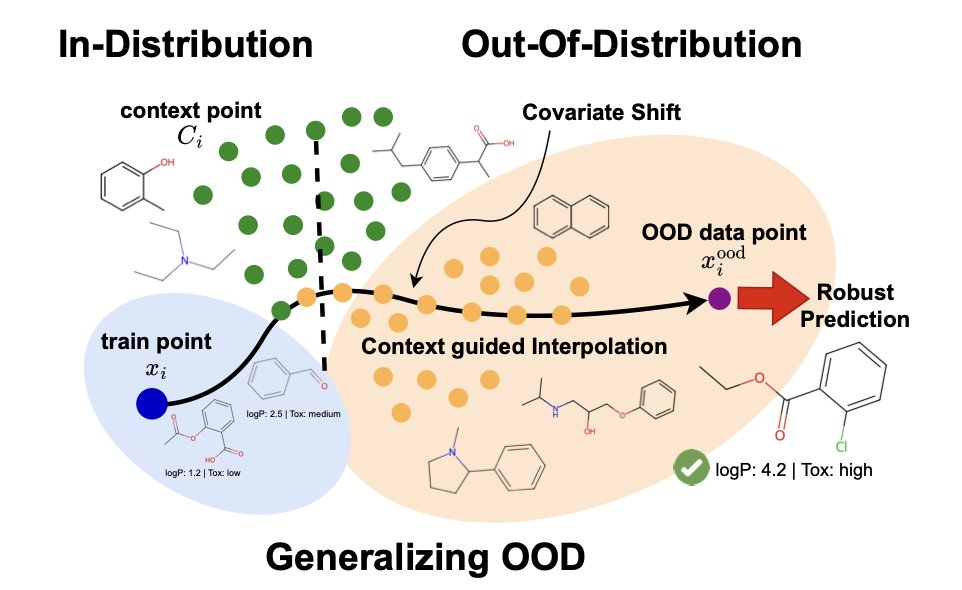
2.The method densifies the sparse labeled training set using abundant unlabeled molecules, guiding the model to better generalize under covariate shift. This is crucial because many real-world drug candidates lie outside the training distribution.
3.Central to their framework is a permutation-invariant learnable set function that interpolates labeled training examples with domain-informed context points drawn from the unlabeled pool. This mixing is learned during training.
4.Unlike standard Mixup or Manifold Mixup, their approach performs interpolation in feature space using a learnable set encoder, and trains it with bilevel optimization—a critical step that substantially improves robustness.
5.The inner loop updates the prediction model using densified inputs, while the outer loop updates the interpolation function to minimize meta-validation loss on randomly labeled data, simulating label noise and improving generalization.
6.Empirical results on the Merck Molecular Activity Challenge show significant improvements over strong baselines, especially under heavy covariate shifts (e.g., HIVPROT), with their method outperforming Mixup and Manifold Mixup variants.
7.t-SNE visualizations reveal that their model learns clearly separated latent representations for ID, OOD, and interpolated inputs, unlike Mixup-based baselines which show significant overlap—highlighting better structure in latent space.
8.Ablation studies confirm that both the use of domain-informed context points and bilevel optimization are necessary for strong OOD performance. Interestingly, training with pseudo-labels from a standard normal distribution works well.
9.The proposed approach is generic and can be used with different mixers, like DeepSets or Set Transformers. Both variants outperform other interpolation strategies on diverse molecular descriptors (bit vectors and count vectors).
10.Overall, this work presents a robust and practical method for property prediction in low-label, high-shift molecular discovery scenarios, and offers a promising direction for leveraging unlabeled data via meta-learned interpolation.
📜Paper: arxiv.org/abs/2506.11877v1
#MachineLearning #DrugDiscovery #MetaLearning #MolecularPropertyPrediction #OODGeneralization #DeepLearning
3
13
80
10,359
16 Jun 2025
Robust Molecular Property Prediction via Densifying Scarce Labeled Data
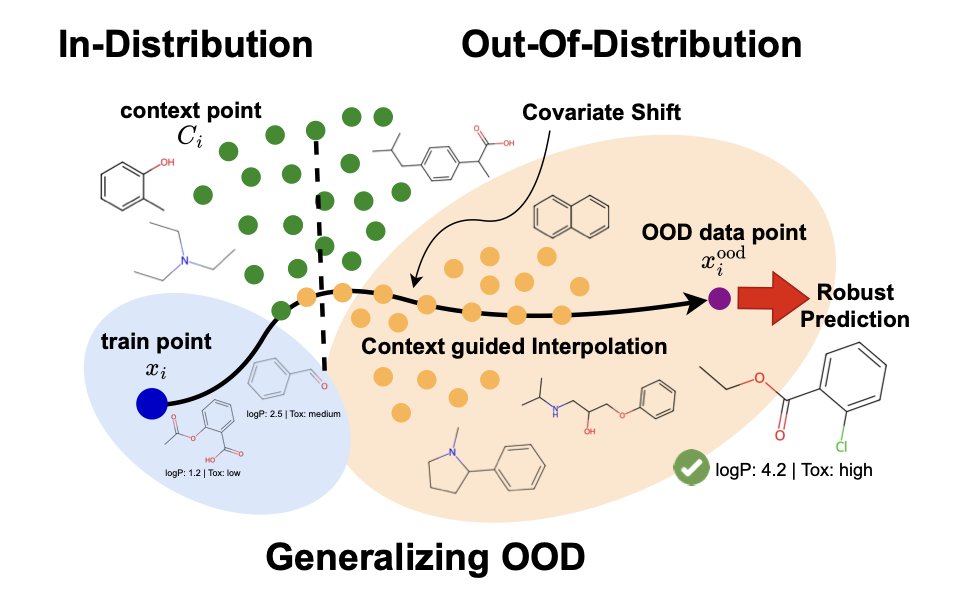
1.A key challenge in drug discovery is predicting properties of out-of-distribution (OOD) molecules using models trained on limited, in-distribution (ID) labeled data. This paper proposes a meta-learning approach to address that.
2.The method densifies the sparse labeled training set using abundant unlabeled molecules, guiding the model to better generalize under covariate shift. This is crucial because many real-world drug candidates lie outside the training distribution.
3.Central to their framework is a permutation-invariant learnable set function that interpolates labeled training examples with domain-informed context points drawn from the unlabeled pool. This mixing is learned during training.
4.Unlike standard Mixup or Manifold Mixup, their approach performs interpolation in feature space using a learnable set encoder, and trains it with bilevel optimization—a critical step that substantially improves robustness.
5.The inner loop updates the prediction model using densified inputs, while the outer loop updates the interpolation function to minimize meta-validation loss on randomly labeled data, simulating label noise and improving generalization.
6.Empirical results on the Merck Molecular Activity Challenge show significant improvements over strong baselines, especially under heavy covariate shifts (e.g., HIVPROT), with their method outperforming Mixup and Manifold Mixup variants.
7.t-SNE visualizations reveal that their model learns clearly separated latent representations for ID, OOD, and interpolated inputs, unlike Mixup-based baselines which show significant overlap—highlighting better structure in latent space.
8.Ablation studies confirm that both the use of domain-informed context points and bilevel optimization are necessary for strong OOD performance. Interestingly, training with pseudo-labels from a standard normal distribution works well.
9.The proposed approach is generic and can be used with different mixers, like DeepSets or Set Transformers. Both variants outperform other interpolation strategies on diverse molecular descriptors (bit vectors and count vectors).
10.Overall, this work presents a robust and practical method for property prediction in low-label, high-shift molecular discovery scenarios, and offers a promising direction for leveraging unlabeled data via meta-learned interpolation.
📜Paper: arxiv.org/abs/2506.11877v1
#MachineLearning #DrugDiscovery #MetaLearning #MolecularPropertyPrediction #OODGeneralization #DeepLearning
1
12
884

10 Sep 2024
Introducing #Nesa’s AI Chief, Dr. Yuzhe Yang! Dr. Yang is a #Forbes30Under30 winner and holds a PhD from #MIT in #AI. Named a #RisingStar in AI by the #WorldAIForum (#WAIFO), he earned an #MIT #CSAIL monthly feature in 2022. His AI research was recognized as one of the #10NotableAdvances by #NatureScience.
Dr. Yang is a trusted #MachineLearning expert with multiple published papers in #ICML for #UnbiasedLearning, #ICLR for #RepresentationLearning, ICML for #AlgorithmicFairness, and #ECCV for #OODGeneralization. His work on in-home human #SleepSensing has even been deployed in hospitals for passive #COVID19 monitoring.
Over the years, his work has been covered by dozens of mainstream media outlets, and Dr. Yang has given #AI talks at top institutions across #NorthAmerica. He earned prestigious fellowships such as the #TakedaPhDFellowship and the #MathworksPhDFellowship, won the #BestProjectAward from #IEEE, and received a national #Scholarship from the #MinistryOfEducation of China. Dr. Yang is also a #BaiduPhDScholar and a #NeurIPS Top Reviewer. He holds a #BSc with Highest Honors in #ComputerScience from #PekingUniversity.
@yang_yuzhe

9 Sep 2024

🚀 Introducing Nesa - The Future of AI on Blockchain 📷
Nesa is not just another blockchain project; it's a revolutionary Layer-1 platform designed for #AI, ensuring #Privacy and #Security are at the forefront. Here's why Nesa stands out:
Decentralized AI Inference: Nesa leverages #ZeroKnowledgeMachineLearning (ZKML) and other advanced cryptographic techniques to execute AI models on-chain, keeping your data private and secure.
Innovative Architecture: With a model-agnostic hybrid sharding approach, Nesa distributes computational loads efficiently across a decentralized network, making AI accessible and scalable.
Empowering Users: By eliminating intermediaries, Nesa gives you control over your data, fostering a trustless environment where AI computations are verifiable and private.
Community and Growth: Already, Nesa has formed strategic partnerships and is expanding its ecosystem, proving its commitment to a decentralized, privacy-focused AI future.
Join the revolution in AI technology with Nesa, where your data's privacy is non-negotiable. #Nesa #DecentralizedAI #BlockchainTechnology @nesaorg



2
127