
Feb 25
🧐 Delve into our paper:
arxiv.org/abs/2602.20068
Many thanks to my Supervisor Prof. @KostasKamnitsas @UniofOxford and co-authors @ZiyunLiang_ & @Hermionegrace76 ! Funded by @EPSRC.
I look forward to attending #CVPR2026 in Denver this June!
🏁(9/9)
#ML #AI #Outofdistribution

2
165

27 Nov 2025
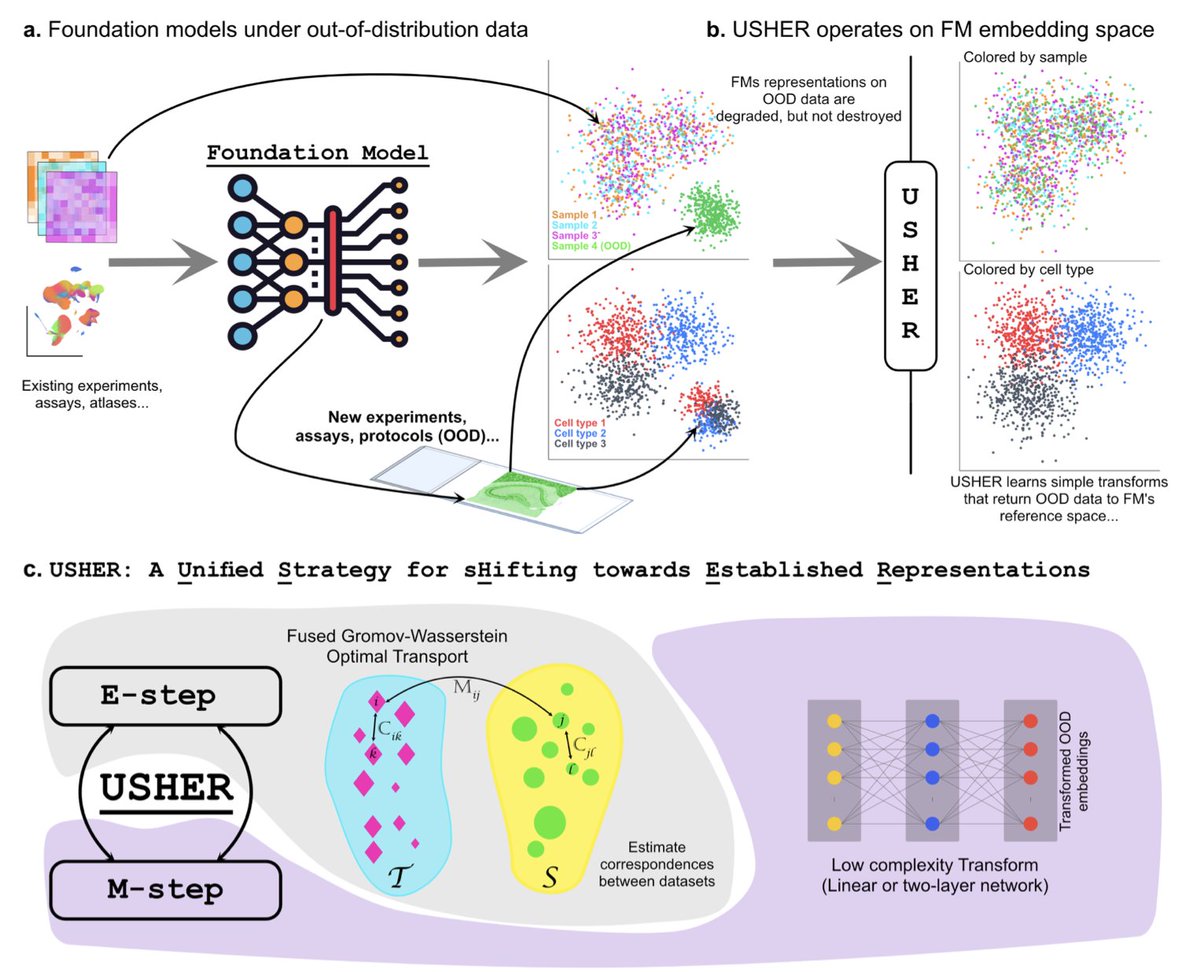
Transforming Biological Foundation Model Representations for Out-of-Distribution Data
1. This study introduces USHER, a novel framework designed to adapt foundation model representations to handle out-of-distribution (OOD) data effectively. USHER addresses a critical challenge in biological data analysis where models trained on specific datasets fail to generalize to new experimental protocols or assays.
2. The core innovation of USHER lies in its ability to transform OOD embeddings back to the reference space of a foundation model using an expectation-maximization procedure. This method leverages Fused Gromov-Wasserstein optimal transport to align embeddings while preserving local structure, ensuring biological relevance.
3. USHER demonstrates significant improvements in integrating single-cell transcriptomics data from Xenium assays with standard scRNA-seq data. By correcting platform-specific biases, USHER enhances cell type clustering and enables cross-platform integration, which is crucial for comprehensive biological studies.
4. In addition to transcriptomics, USHER is also applied to histopathology imaging data, where it corrects artifacts introduced by MALDI mass spectrometry. This correction enables accurate cell-type classification and protein abundance imputation, showcasing USHER’s versatility across different biological data modalities.
5. A key advantage of USHER is its generalizability. The framework not only works for the specific samples used in training but also applies to other samples from similar experimental conditions, making it a powerful tool for adapting foundation models to new datasets without extensive retraining.
6. The study highlights that conventional batch correction methods fail to address the challenges posed by OOD data in biological foundation models. USHER’s approach of learning simple, low-complexity transformations provides a robust alternative that maintains the integrity of the original embeddings.
7. The authors emphasize the importance of preserving the biological structure captured by foundation models even when encountering OOD data. USHER achieves this by making only modest adjustments to the embedding space, ensuring that downstream tools relying on these models remain compatible.
📜Paper: biorxiv.org/content/10.1101/…
#ComputationalBiology #FoundationModels #DataIntegration #SingleCell #Histopathology #OutofDistribution #USHER
1
4
18
1,312
6 May 2025
BOOM: Benchmarking Out-Of-distribution Molecular Property Predictions of Machine Learning Models
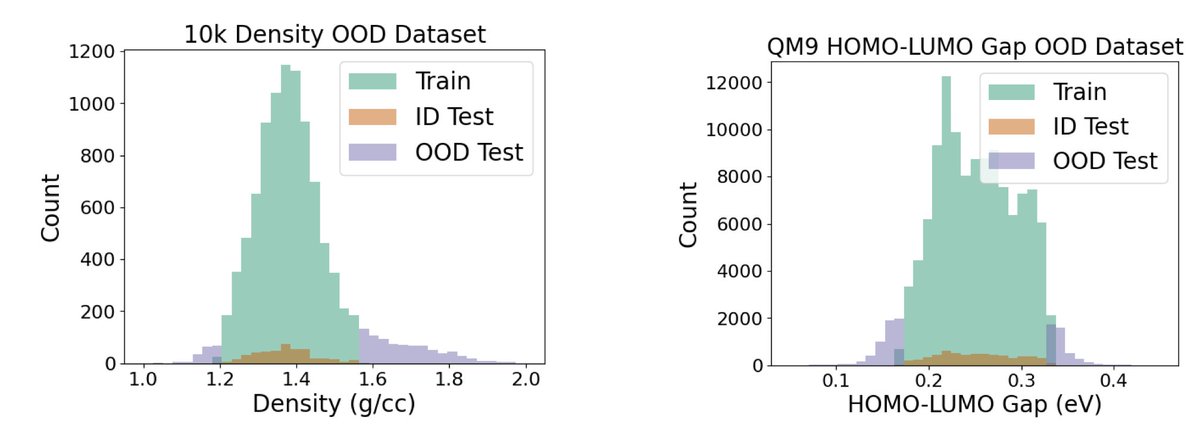
1. BOOM is the first systematic benchmark focused on evaluating the out-of-distribution (OOD) generalization performance of molecular property prediction models, a critical challenge for enabling ML-guided discovery of novel molecules.
2. The authors assess 12 ML models across 10 molecular properties using over 140 model-task combinations, revealing that even top models exhibit up to 3x higher error on OOD data compared to in-distribution (ID) test sets.
3. No current model shows robust OOD performance across all tasks. MACE leads in OOD performance on 5 of 10 tasks, while ET dominates ID tasks, indicating that strong in-distribution accuracy does not guarantee generalization.
4. Pretraining strategies like masked language modeling (MLM) significantly improve ID performance but fail to enhance, and sometimes degrade, OOD performance—highlighting a key limitation in current chemical foundation models.
5. The benchmark defines OOD splits based on the tails of molecular property distributions, aligning with real-world discovery goals where desirable molecules often lie outside known distributions.
6. 3D-aware models, especially those with E(3)-equivariance like EGNN and MACE, outperform SMILES-based transformers in OOD settings. Representation choice is thus more critical than scale for extrapolation.
7. Hyperparameter tuning targeting OOD performance offers some benefit, particularly for simple properties like density or heat of formation, but is not sufficient to close the generalization gap.
8. Data augmentation by including a small number of OOD molecules in training substantially improves generalization for 7 of 8 tasks tested, suggesting that even modest exposure to rare examples helps overcome distributional shifts.
9. ModernBERT, though a transformer model, incorporates architecture changes that improve OOD performance in tasks like HoF and Cv, narrowing the gap with graph-based models and showing promise for LLM-style scalability.
10. The study identifies specific property types (e.g., dipole moment, HOMO, LUMO) as persistent weak points for OOD prediction, likely due to the absence of explicit electronic structure features in most models.
11. BOOM provides an open-source benchmark, dataset, and codebase to standardize OOD evaluation and accelerate the development of chemically generalizable machine learning models.
12. This work positions OOD generalization—not just ID accuracy—as a new frontier for chemical ML, essential for reliable property extrapolation and robust molecular discovery.
📜Paper: arxiv.org/abs/2505.01912
#Chemoinformatics #OutOfDistribution #MachineLearning #MolecularDesign #GraphNeuralNetworks #MolecularProperty #Benchmarking #ML4Science #GNN #SMILES #Pretraining #DataAugmentation #BOOM

4
15
1,210
6 May 2025
BOOM: Benchmarking Out-Of-distribution Molecular Property Predictions of Machine Learning Models
1. BOOM is the first systematic benchmark focused on evaluating the out-of-distribution (OOD) generalization performance of molecular property prediction models, a critical challenge for enabling ML-guided discovery of novel molecules.
2. The authors assess 12 ML models across 10 molecular properties using over 140 model-task combinations, revealing that even top models exhibit up to 3x higher error on OOD data compared to in-distribution (ID) test sets.
3. No current model shows robust OOD performance across all tasks. MACE leads in OOD performance on 5 of 10 tasks, while ET dominates ID tasks, indicating that strong in-distribution accuracy does not guarantee generalization.
4. Pretraining strategies like masked language modeling (MLM) significantly improve ID performance but fail to enhance, and sometimes degrade, OOD performance—highlighting a key limitation in current chemical foundation models.
5. The benchmark defines OOD splits based on the tails of molecular property distributions, aligning with real-world discovery goals where desirable molecules often lie outside known distributions.
6. 3D-aware models, especially those with E(3)-equivariance like EGNN and MACE, outperform SMILES-based transformers in OOD settings. Representation choice is thus more critical than scale for extrapolation.
7. Hyperparameter tuning targeting OOD performance offers some benefit, particularly for simple properties like density or heat of formation, but is not sufficient to close the generalization gap.
8. Data augmentation by including a small number of OOD molecules in training substantially improves generalization for 7 of 8 tasks tested, suggesting that even modest exposure to rare examples helps overcome distributional shifts.
9. ModernBERT, though a transformer model, incorporates architecture changes that improve OOD performance in tasks like HoF and Cv, narrowing the gap with graph-based models and showing promise for LLM-style scalability.
10. The study identifies specific property types (e.g., dipole moment, HOMO, LUMO) as persistent weak points for OOD prediction, likely due to the absence of explicit electronic structure features in most models.
11. BOOM provides an open-source benchmark, dataset, and codebase to standardize OOD evaluation and accelerate the development of chemically generalizable machine learning models.
12. This work positions OOD generalization—not just ID accuracy—as a new frontier for chemical ML, essential for reliable property extrapolation and robust molecular discovery.
📜Paper: arxiv.org/abs/2505.01912
#Chemoinformatics #OutOfDistribution #MachineLearning #MolecularDesign #GraphNeuralNetworks #MolecularProperty #Benchmarking #ML4Science #GNN #SMILES #Pretraining #DataAugmentation #BOOM
8
999
4 Oct 2024
📣 New publication to be presented at @UNSURE_Workshop #MICCAI2024!
⚠️Individual #outofdistribution detection methods have strengths and weaknesses.
💡 Combining complementary methods can mitigate their weaknesses!
🧐 Dive into our research: link.springer.com/chapter/10…
🧵(1/10)
2
11
38
2,605

Excellent paper by @scemama_paul & Ariel Kapusta
“Our results suggest that combining #Bayesian #deeplearning models with split #ConformalPrediction can, in some cases, cause unintended consequences such as reducing #OutOfDistribution coverage”
#Uncertainty
1
60
3 Oct 2023
📢 New publication to be presented @unsure_workshop #MICCAI2023!
⚠️Mahalanobis distance for #outofdistribution detection has shown mixed performance.
💡 Further research to find best practices required!
🧐 Dive into our research: arxiv.org/abs/2309.01488
#reliableAI
🧵(1/7)
1
6
19
3,515

26 Apr 2023
🚀 Fortuna starts supporting #OutOfDistribution (#OOD) #UncertaintyQuantification methods!
We released #SNGP, a method that properly captures the lack of confidence in the model predictions as we move away from the data. ⭐️
Look, using SNGP is so easy! tinyurl.com/p25292vy
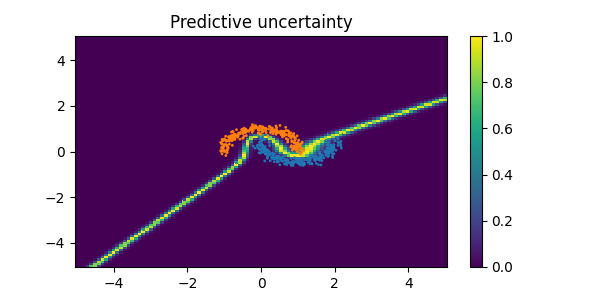
ALT Predictive uncertainty on two-moon dataset using a standard training procedure (MAP). The method is highly overconfident as we move away from the data!
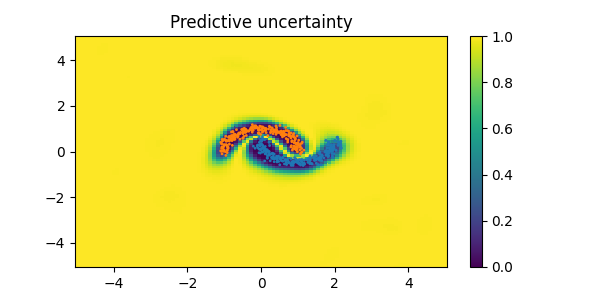
ALT Predictive uncertainty on two-moon dataset using SNGP. The method is properly uncertain far from the data!
7
279
13 Apr 2023
Quantification of uncertainty #OutOfDistribution (OOD) is a huge challenge and a fervent research field.
Fortuna (github.com/awslabs/fortuna) will soon support specific #OOD solutions. ⭐
To check what methods Fortuna already supports, see tinyurl.com/et34ue2u
#MachineLearning
2
12
729

11 Jan 2023
Insightful article by @_travistang who improved ResNet image classifier by 4 percentage points using cleanlab to fix issues in training dataset without changing model at all. To further improve results, try outlier detection too:
`from cleanlab.outlier import OutOfDistribution`
11 Jan 2023

Cleanlab: Correct your data labels automatically and quickly via #TowardsAI → towardsai.net/p/l/cleanlab-c… #MachineLearning #ML #ArtificialIntelligence #MLOps #AI #DataScience #DeepLearning #Technology #Programming #News #Research #Coding #AIDevelopment
2
12
844

30 Aug 2022
Happy to announce that we pushed an updated version of our #astronomy paper --arxiv.org/abs/2112.14072!
By leveraging #ArtificialIntelligence, including #domainadaptation, we significantly improve upon the extraction of star-formation-histories of #outofdistribution galaxies.
2
2
10

7 Jun 2022
Pleased to share that my paper "Robust Intent Classification Using Bayesian LSTM for Clinical Conversational Agents (CAs)" has finally been published.
#conversationalagents #patientsafety #healthcare #machinelearning #outofdistribution
link.springer.com/chapter/10…
4

13 Apr 2022
Our paper on #distributionshift in human neuroscience now accepted at @PLOSBiology.
Congrats to @oualid_benkarim for leading this quantitative analysis!
#untracked #diversity #outofdistribution
@enigmabrains @ABCD_ReproNim @BertrandThirion @phyzang
18 Jun 2021

New preprint, led by @oualid_benkarim, examining
out-of-distribution prediction in #ABIDE #HBN:
Analytical tools are needed to get a handle on
#untracked #diversity in multi-site cohorts
biorxiv.org/content/10.1101/…
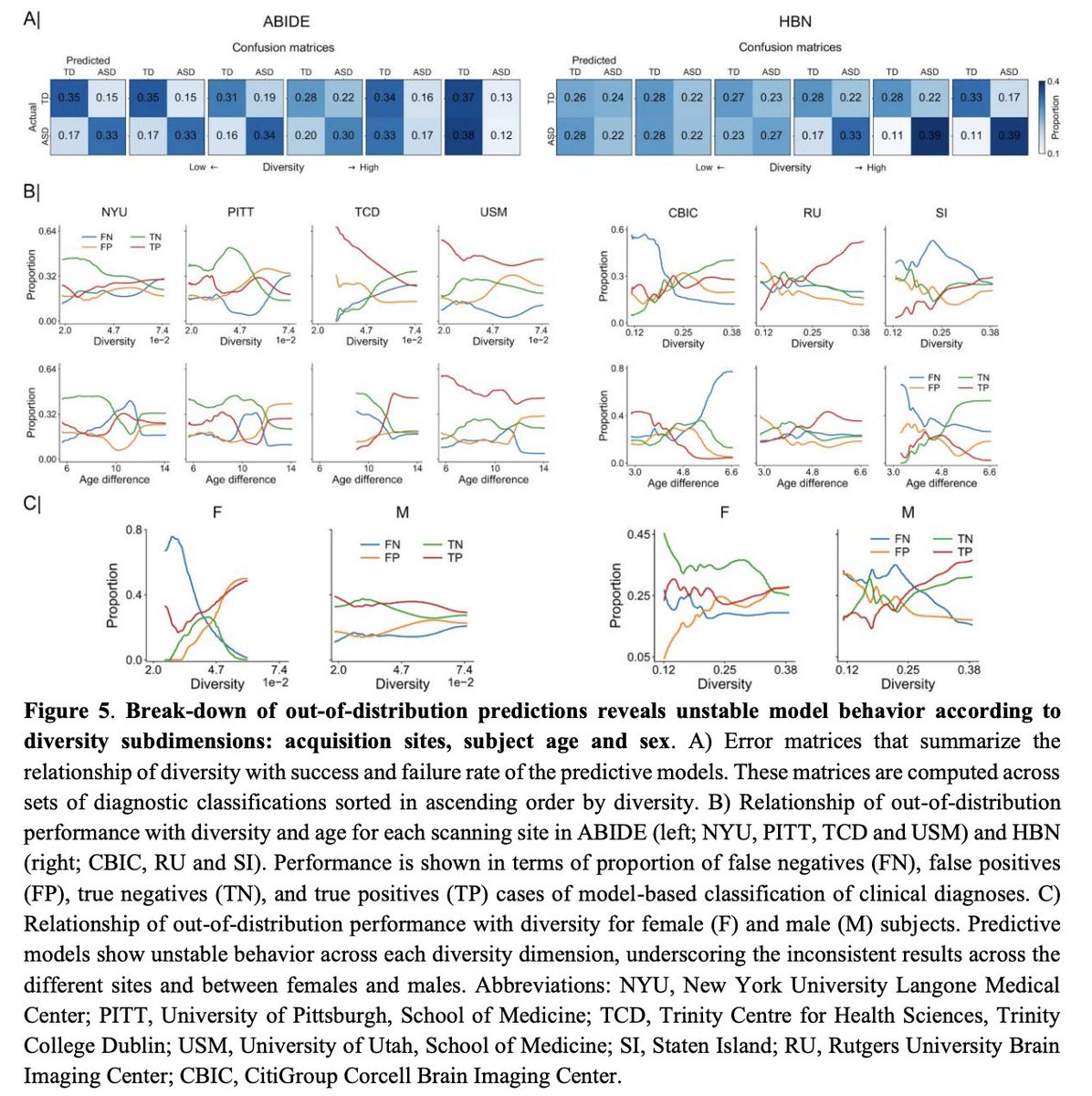
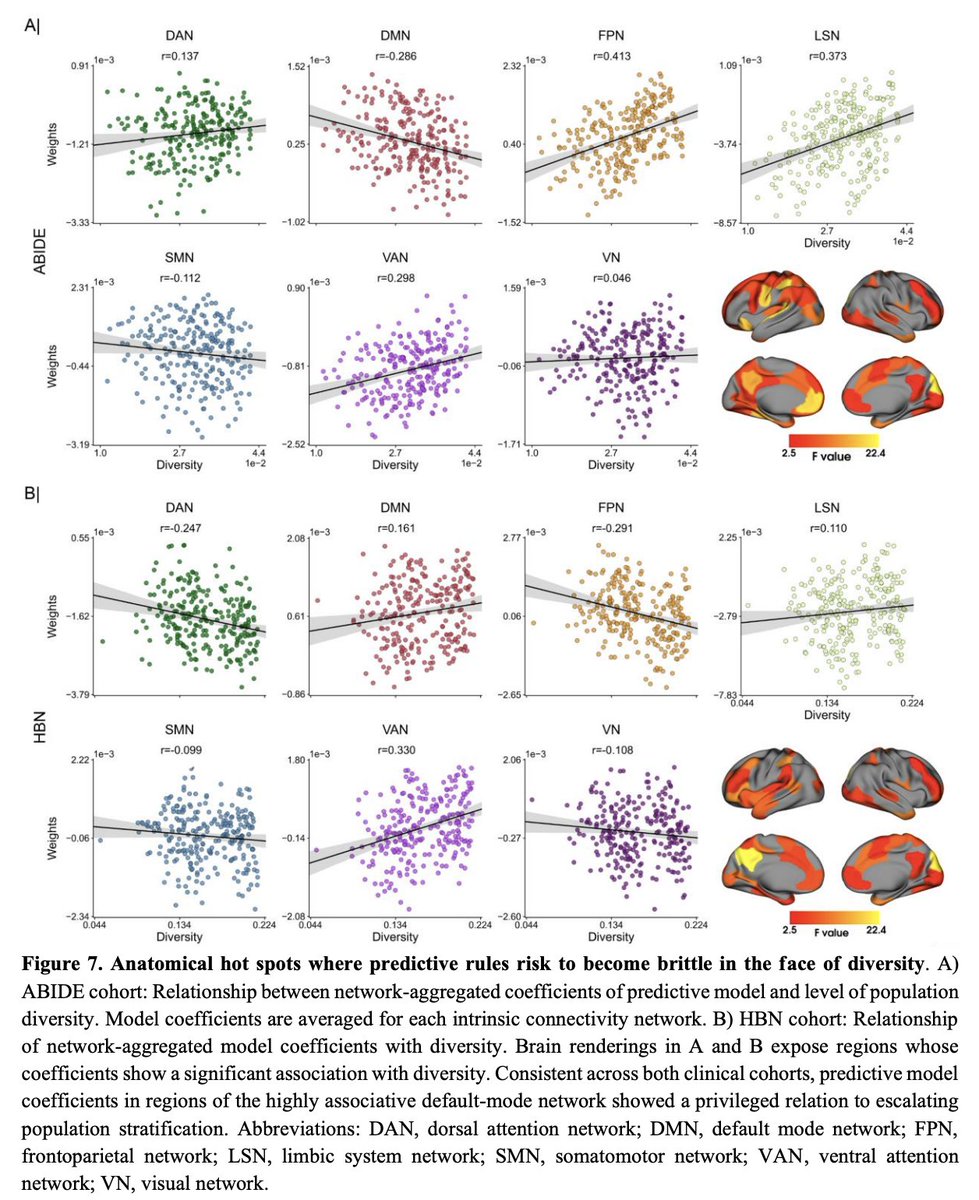
5
12

2 Mar 2022
We propose Detect-and-Segment, a two stage #DeepLearning approach to produce #wound #segmentation maps with high #generalization capabilities. The DS approach showed high performance on #OutOfDistribution testing and enabled the reduction of segmentation labels used for training.

ALT Detect-and-segment (DS) approach (grey box). The raw wound image (a) is processed with a wound detector neural network (b) to localize the wound within the image. The preprocessing module (c) performs cropping, zero-padding and resizing of the image to exclude uninformative background pixels. The segmentation model (d) produces the final segmentation mask (e).
1
2
13 Jul 2021
New preprint by @GoogleResearch:
#Deeplearning models with higher expressive capacity can be more robust to #outofdistribution prediction
arxiv.org/abs/2106.15831
@KordingLab @neuro_data @BoWang87

2
6
26

29 Feb 2020
Questions in science/med require solving many related but different ML tasks, task-specific labels are scarce, test data are distributionally different from train data. Our approach paves the way to learning in these hard regimes #TransferLearning #OutOfDistribution
29 Feb 2020

Excited to share our spotlight paper at #ICLR2020 "Strategies for Pre-training GNNs." We develop effective strategy/methods for pre-training GNNs and systematically study its effectiveness.
Web site: snap.stanford.edu/gnn-pretra…
Paper: openreview.net/forum?id=HJlW…
1
4
24