
3 Sep 2025
🔥 Read our Highly Cited Paper
📚 Impact of Incorporating Two Types of #DriedRaspberryPomace into #GlutenFreeBread on Its Nutritional and #Antioxidant Characteristics
🔗 mdpi.com/2076-3417/14/4/1561
👨🔬 Anna Pecyna et al.
🏫 @UPLublin
#polyphenols #nutritionalproperties #bioactivecompounds #principalcomponentanalysis

2
29

Race: A Social Construct Or Genetic Biomarker? / American Council on Science and Health
A new study from the NIH's All of Us program is shaking up long-held assumptions by revealing that genetic ancestry rarely aligns with racial labels-and that the interplay between biology and society is far messier than we like to admit. Race might be a helpful lens for understanding inequality, but it's a terrible shortcut for decoding our DNA #DrChuckDinerstein
acsh.org/news/2025/06/11/rac…
@MateusHG13 @AllofUsResearch @JonathanKahn4 @AJHGNews @genome_gov @NHGRI_Director @tarazona_santos @AJHGNews @MarlaMendesA @MJAckermanMDPhD @acegid_igh @CesarFortesLima @RarePOV @eperlste @OnceUponAGene @kareem_carr @GENbio @MithiVita @dysclinic @ZernickaGoetz @prettycoco23 @GhanaboyPharmd @FundSickleCell @RareDiseases @OnceUponAGene @EdEsplin @mfwangler @GeneticLiteracy @BenLocwin @Labcorp @_atanas_ @AdamRutherford @thepostdoctoral @victor_snail @annagloyn @julemieux1 @patbhamilton @ATJCagan @SinaiGenHealth @StopSarcoidosis @MJAckermanMDPhD @GillianHSapia @SciFleur @RebeccaHamel1 @SREJournal @JamieMetzl @hsiung_chris @mmbronstein @ResearchAmerica @uscensusbureau
#ProfessorCharlesRotimi #GenomeResearch #Ancestry #SocialContructofRace #GeneticDiversity #Ethnicity #PrincipalComponentAnalysis #PCA #DecodingDNA #GlobalMeltingPot #RacialAdmixture #GlobalAncestralClusters
3
7
576
12 May 2025
🔥 Read our Paper
📚 Slope Stability Prediction Using Principal Component Analysis and Hybrid Machine Learning Approaches
🔗 mdpi.com/2076-3417/14/15/652…
👨🔬 by Daxing Lei,Yaoping Zhang,Zhigang Lu,Hang Lin,Bowen Fang andZheyuan Jiang.
🏫 GanNan University of Science and Technology
#slopestability #factorofsafety #principalcomponentanalysis #machinelearning #neuralnetwork

3
83

4 Jan 2025
Principal component analysis for preschoolers. If you know you know 🤣 #principalcomponentanalysis #scientistsofx #science #statistics #geneticist

1
7
2,563



24 Jun 2024
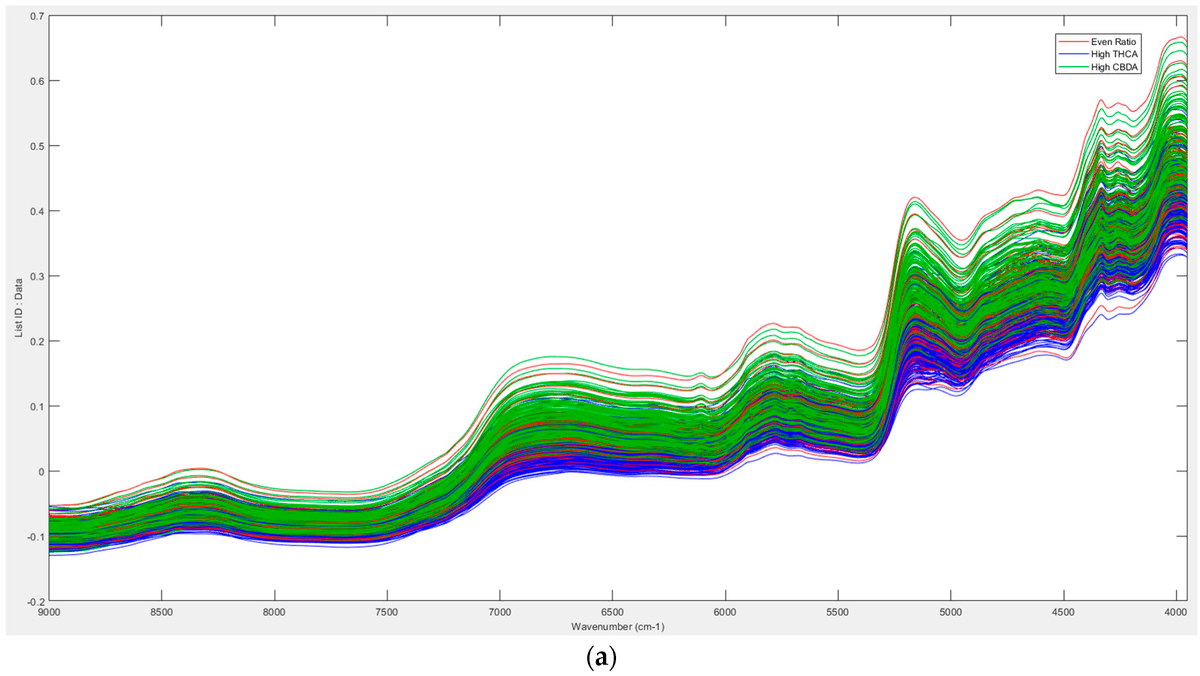
Developing Prediction Models Using Near-Infrared #Spectroscopy to Quantify Cannabinoid Content in Cannabis Sativa
mdpi.com/1424-8220/23/5/2607
#cannabinoids #partialleastsquareregression #principalcomponentanalysis
2
75

27 May 2024
Choice of the Right Supporting Electrolyte in Electrochemical Reductions: A Principal Component Analysis | Journal of the American Chemical Society @uni_mainz #Electrolyte #Elctrochemical #Reduction #Principalcomponentanalysis pubs.acs.org/doi/10.1021/jac…
7
2,762

10 May 2024
📢Call for Submissions to the Special Issue: "Advances in Molecular Dynamics and Molecular Modeling"
✏️Guest edited by Dr. Franci Merzel
🔗brnw.ch/21wJDPM
💻#molecular_dynamics #multiscale_modeling #PrincipalComponentAnalysis #theoretical_chemistry

1
3
348

3 May 2024
#mdpienergies #highlycitedpaper
Inverter-Fed Motor Drive System: A Systematic Analysis of Condition Monitoring and Practical Diagnostic Techniques
👉 ow.ly/SMmj50RvlKY
#conditionmonitoring #inductionmotors #pulsewidthmodulationinverters #principalcomponentanalysis

1
2
81

25 Apr 2024
Mutation Trajectory of #Omicron #SARSCoV2 Virus, Measured by #PrincipalComponentAnalysis
👉mdpi.com/2760216
Konishi & Takahashi analyze SARS-CoV-2 #mutations to predict future impacts
#conservation #variants #hostspecificity
2
111

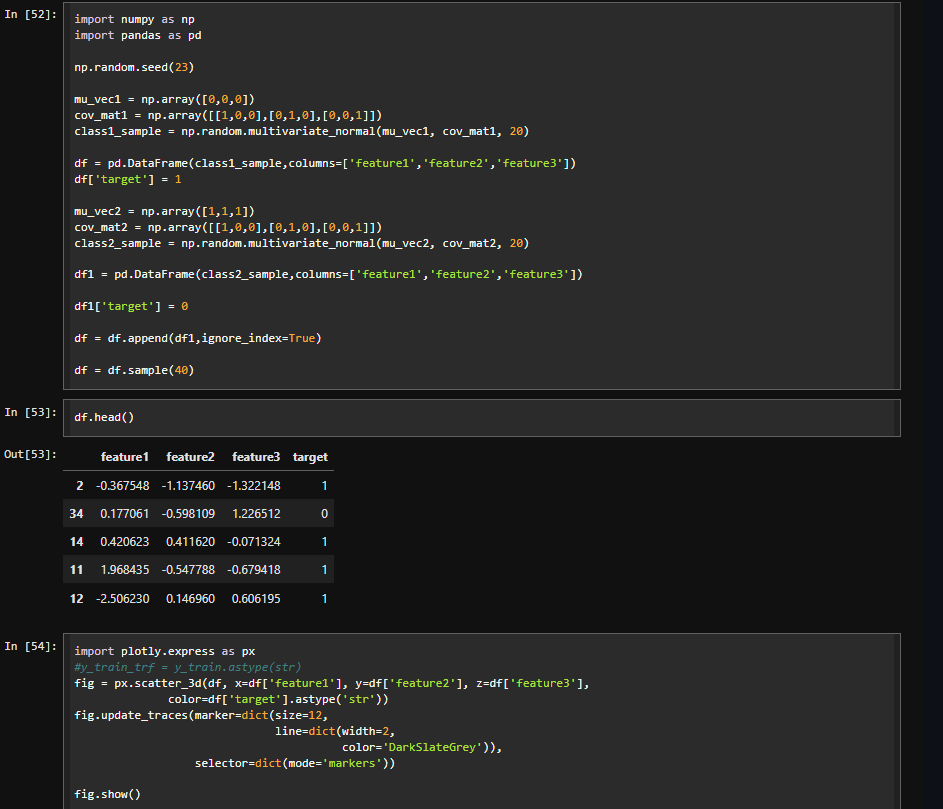
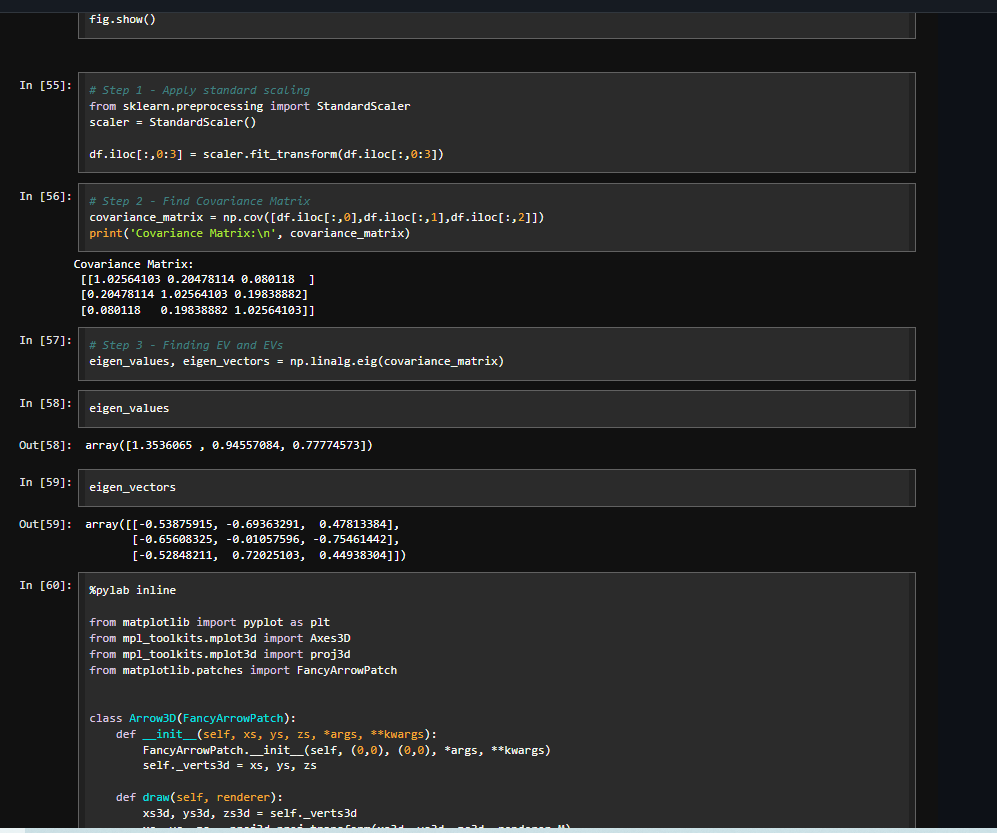
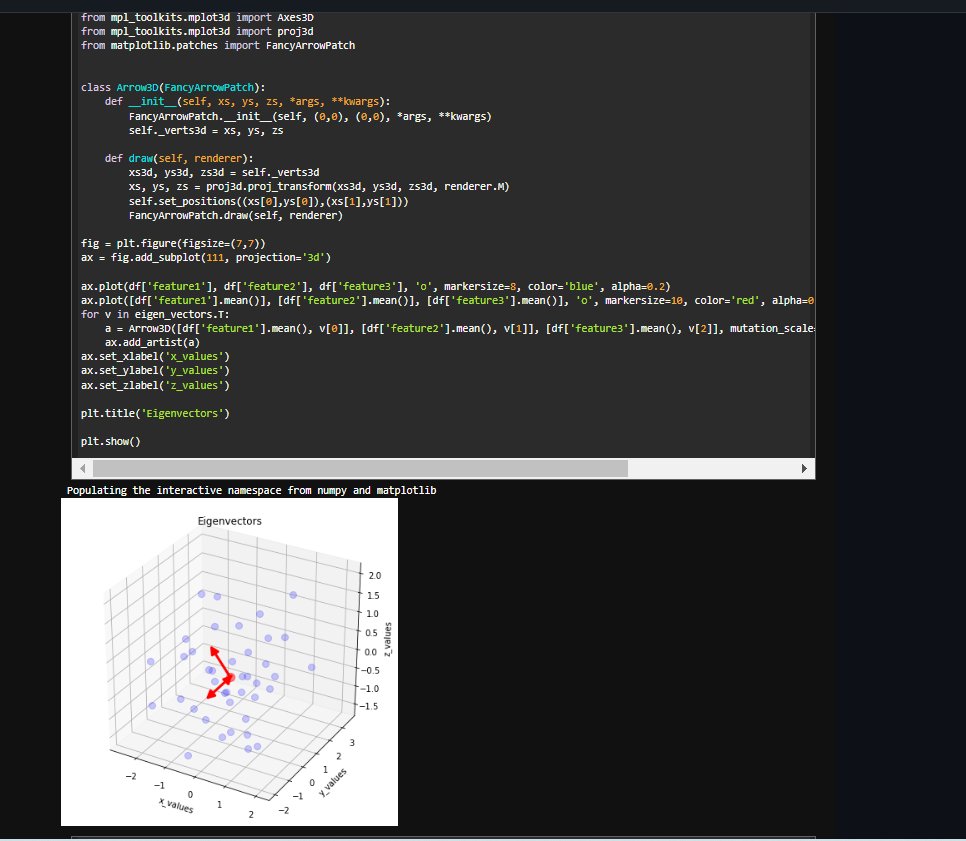
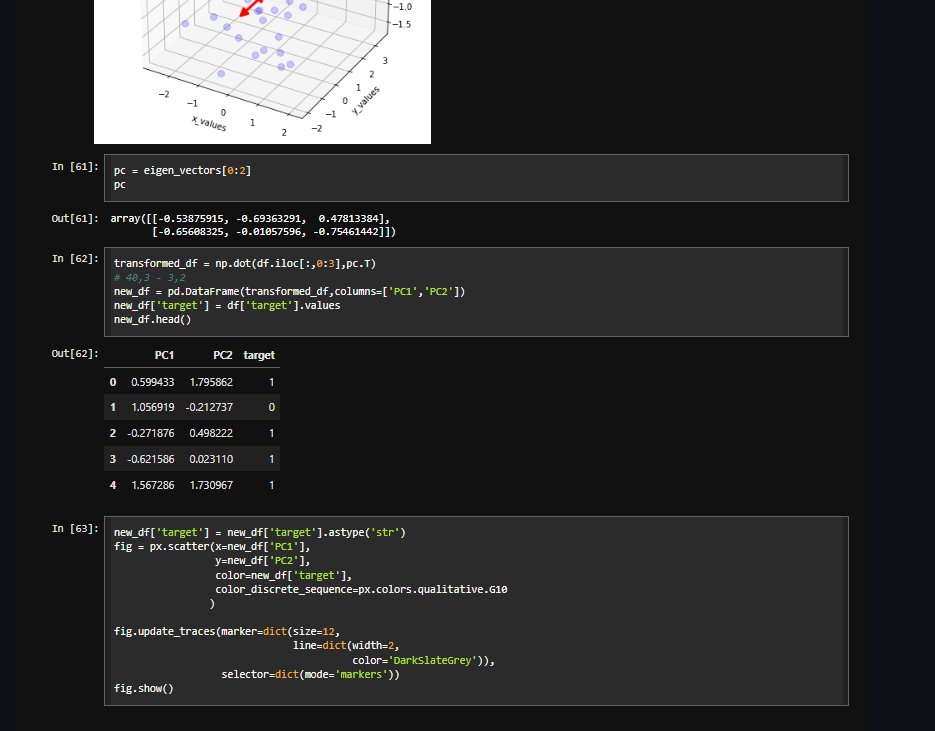

🔔 New article:
Zhuo et al. propose a 2D, superpixelwise #PrincipalComponentAnalysis (#SuperPCA) dimension reduction method for #hyperspectral image #FeatureExtraction.
🔗 doi.org/10.1080/01431161.202…
#IJRS #RemoteSensing #HSI #PCA

7
34
1,888

31 Jan 2024
Groundwater Assessment in Udham Singh Nagar, Uttarakhand, India Using Multivariate Statistical Techniques, WQI, and HPI
cwejournal.org/vol3no3/pgrou… - Read the Article here
#FactorandClusterAnalyses #HeavyMetalPollutionIndex #PrincipalComponentAnalysis #WaterQualityIndex
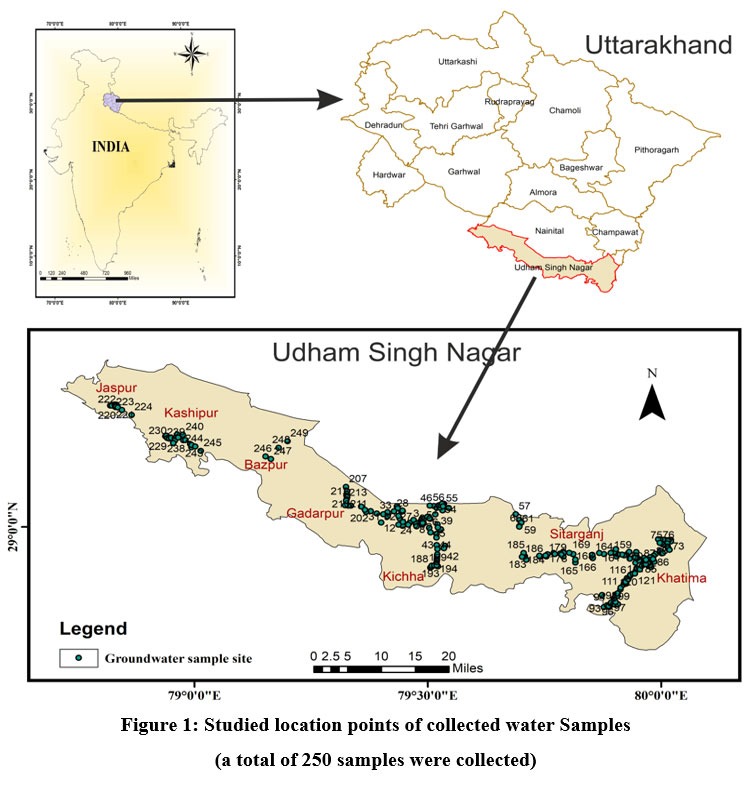
18

30 Aug 2023
Here are eleven of the most widely used statistical methods in #CorpusLinguistics. #CorpusStatistics
#Frequency Analysis: This is the cornerstone of corpus linguistics, used to identify the frequency of words, phrases, or syntactic structures. Biber’s “Variation Across Speech and Writing” (1988) is a classic study that employed frequency analysis to distinguish between spoken and written registers. #FrequencyAnalysis
#Collocation Analysis: This method identifies words that tend to appear together more often than would be expected by chance. Stefanowitsch and Gries’ “Collostructions” (2003) is a notable study in this area. #CollocationAnalysis
#Concordance Analysis: This involves examining all the occurrences of a particular word or phrase within its context. John Sinclair’s work, particularly in “Corpus, Concordance, Collocation” (1991), has been foundational. #ConcordanceAnalysis
#Keyness Analysis: This method identifies statistically significant words in a corpus compared to a reference corpus. Paul Rayson’s “Matrix: A Statistical Method and Software Tool for Linguistic Analysis” (2003) is a key reference.
#KeynessAnalysis
#Cluster Analysis: This is used to group similar items in a corpus, often revealing patterns or themes. Douglas Biber’s “University Language” (2006) employed cluster analysis to study academic registers. #ClusterAnalysis
#Mutual Information: This measures the strength of association between two words. Church and Hanks’ “Word Association Norms, Mutual Information, and Lexicography” (1990) is a seminal paper that introduced this concept.
#MutualInformation
#Log-Likelihood Ratio: This is used to test the significance of the difference between two proportions, often in comparing corpora. Dunning’s “Accurate Methods for the Statistics of Surprise and Coincidence” (1993) is a key study here. #LogLikelihoodRatio
Principal Component Analysis (#PCA): This reduces the dimensionality of the data while retaining most of the original variance. Baayen et al.’s “Mixed-effects modeling with crossed random effects for subjects and items” (2008) utilized PCA.
#PrincipalComponentAnalysis
#Chi-Square Test: This tests the independence of two categorical variables. It was notably used in McEnery, Xiao, and Tono’s “Corpus-Based Language Studies” (2006).
#ChiSquareTest
#T-Score: This measures the “bond” between two words in a collocation. “Collocations in Use” (Hill and Lewis, 1997) is a study that employed T-Scores. #TScore
#Log-Dice Statistics: This method is an advancement over Mutual Information and is particularly useful for large corpora. It provides a normalized score that allows for better comparison of word associations across different datasets. Rychlý’s “A Lexicographer-Friendly Association Score” (2008) is a seminal paper that introduced log-dice statistics as a lexicographer-friendly measure. #LogDiceStatistics
Each of these methods has its own advantages and specific applications, making them invaluable in the toolkit of any corpus linguist. Whether you’re exploring lexical trends or syntactic structures, these methods offer robust, reliable ways to make sense of the data.
1
16
37
2,064

20 Jun 2023
Immerse yourself in the world of Principal Component Analysis with our newest blog post!
.
.
.
#PrincipalComponentAnalysis #DataScience #AI #ArtificialIntelligence #Technology #Tech #Robotics #innovation #development




1
2
39
20 Jun 2023
Understanding Principal Component Analysis - Uncovering the Invisible
.
.
.
#PrincipalComponentAnalysis #DataScience #AI #ArtificialIntelligence #Technology #Tech #Robotics #innovation #development
1
4
74

12 May 2023
⏪📑Memories #2018 @IEEEXplore #UPSEcuador @upsalesianaec 🔗𝑳𝒊𝒏𝒌: doi.org/10.1109/ACCESS.2018.…
#Classifier #PrincipalComponentAnalysis #FailureAnalysis #Embeddings #SomosEcosistema #SomosUPS #UPSEcuador #UPSCuenca #DivulgaciónCientíficaUPS #InvestigaciónUPS

2
4
19

11 May 2023
This thread is saved to your Notion database.
Tags: [Statistics, Principalcomponentanalysis]
10

#MachineLearning for #Healthcare: Applying Dimensionality Reduction with #PrincipalComponentAnalysis to #CancerData.
blog.bigml.com/2018/12/11/ap…
#MLadoption #MLplatform #NoCode #LowCode #UseCase #BigML #Cancer #Health #PCA

1
3
220

20 Apr 2023
There is a genre of expository writing (or speaking) that could be called 'explain a topic on five increasing levels of sophistication'.
This thread colllects examples of that genre (by others).
I start with #PrincipalComponentAnalysis (a concept mostly used in #Statistics)

1
2
417