
Jan 24
Echo turns reinforcement learning into a distributed party: capybaras sample experiences, train policies together, sync models, and loop smarter—scalable, efficient, and powered by everyday compute.
#EchoRL #DistributedLearning #AIInfra #GradientNetwork

4
54

Jan 21
KAUST Professor @peter_richtarik has received the Charles Broyden Prize for the second consecutive year, recognizing outstanding theoretical contributions to optimization.
The award-winning work advances communication-efficient distributed optimization, introducing new variance-reduction techniques that reduce communication overhead while preserving strong theoretical guarantees. Further, this new work enables a myriad of new communication compression methods to be used, which makes the method much more versatile and practical. These advances address a key bottleneck in large-scale artificial intelligence systems, where communication overhead often limits performance.
The research was developed at KAUST with doctoral students and a visiting international collaborator, reflecting the university’s excellence in research that enables scalable and reliable artificial intelligence systems.
Award-winning authors: Samuel Horváth, Dmitry Kovalev, Konstantin Mishchenko, Peter Richtárik, and Sebastian Stich.
Read more: cemse.kaust.edu.sa/articles/…
#KAUST #CEMSE #Optimization #DistributedLearning #MachineLearning #Algorithms #KAUSTCS #KAUSTAMCS #KAUSTSTAT

1
17
1,235

The future of AI is no longer confined to the cloud. 2026 is the Year of Distributed Intelligence. We're bringing #GenAI to the very edge—powering smart devices, real-time insights, and truly decentralized learning. The revolution is on-device! 🧠✨
#EdgeAI #DistributedLearning

6
9
31

13 Nov 2025
Introducing CodeZero — built on the foundation of RL-Swarm, it extends our distributed learning framework into cooperative coding agents on @gensynai
Users take part as Solvers, tackling coding challenges and sharing outcomes so the swarm learns collectively.
CodeZero uses the same peer to peer infrastructure and smart contracts but focuses on cooperation: nodes train locally, share rollouts and drive continuous improvement.
The system cycles through three roles: Proposers create problems & set difficulty, Solvers solve & share results and Evaluators assess & reward solutions.
To ensure trust and decentralization, CodeZero introduces a model based reward system that never runs code directly, using lightweight local models to assess reasoning and intent.
More than coding, it’s about machines learning to reason and collaborate together, making CodeZero a proving ground for collective machine intelligence.
#AI #DistributedLearning #CoopAI #Coding #MachineLearning #DeFi #Web3 #RLswarm #CodeZero

10
165

29 Jul 2025
Imagine an internet of models.
All contributing, learning, and evolving in real time.
FractionAI makes that vision real.
#FractionAI #DistributedLearning
@FractionAI_xyz

1
15
29

25 May 2025
🎓📷
We've been working on Didactica, a revolutionary learning platform that connects students and teachers through the power of blockchain technology.
#EdTech #Blockchain #DistributedLearning #ZeroWallet #Education #Innovation #ZEROCAT #Didactica
youtu.be/PWExCwLv4Js
10
1
8
202
18 May 2025
Education should be modern and trustworthy - and blockchain technology helps us deliver on that promise. Interested in trying it out or collaborating? Let's connect! #EdTech #Blockchain #DistributedLearning #ZeroWallet #Education #Innovation #ZEROCAT #Didactica
1
2
23

18 Apr 2025
🌏 Spring AI Tour: From Singapore to New Mexico to Texas!
Catch me & the team at:
🇸🇬 ICLR 2025 (Apr 24–28, Singapore)
📍 4 main papers, 5 workshop papers, 1 workshop organized, 2 keynotes, 1 talk, 1 panel.
Topics:
🛡 AegisLLM @ BuildingTrust
🎭 AdvBDGen (stealthy backdoors)
🌐 Web AI Agents Vulnerability
🤖 TraceVLA for spatial-temporal grounding
🔍 Scaling Inference-Time Search (Visual Value Models)
🔥 Alignment, World Models, Watermarking, Vision-Language & more!
🧠 Don’t miss the Alignment Workshop on Apr 23 (co-located @ Singapore)—I’m giving a lightning talk "Alignment On The Fly" there!
🇺🇸 NAACL 2025 (Apr 29–May 1, Albuquerque)
💥 5 papers on:
💀 PoisonedParrot (data poisoning)
🧠 World Models for Goal-Directed LLMs
🔀 MergeME (Model Merging for MoEs)
🧩 Causal Inference VLM Alignment
🇺🇸 TL;DR @ Rice University (May 2, Houston)
🎤 Talk: Test-Time Thinking for Trust: Enhancing Generative AI Agents
Kudos to all our lab members (@ruijie_zheng12 @cheryyun_l @SOURADIPCHAKR18 @Yuancheng_Xu0 @sichengzhuml @bang_an_ @ZikuiCai @shabihish @PankayarajP @michael_panaite @JayLEE_0301 @XiyaoWang10 @YuhangZhou2 @xiaoyu_liu_1231 Aakriti Agrawal, Yifan Yang) and collaborators! 🙌
#ICLR2025 #NAACL2025 #AIAlignment #GenAI #LLMs #Robotics #DistributedLearning



5
16
76
22,314

23 Dec 2024
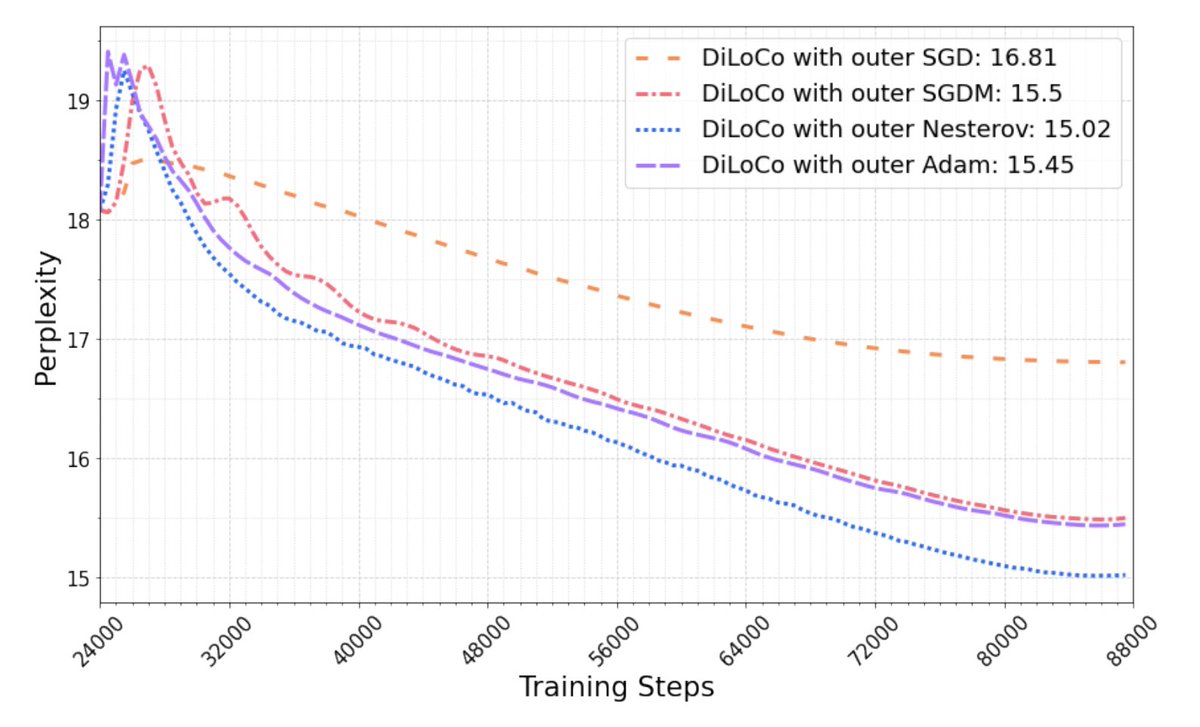
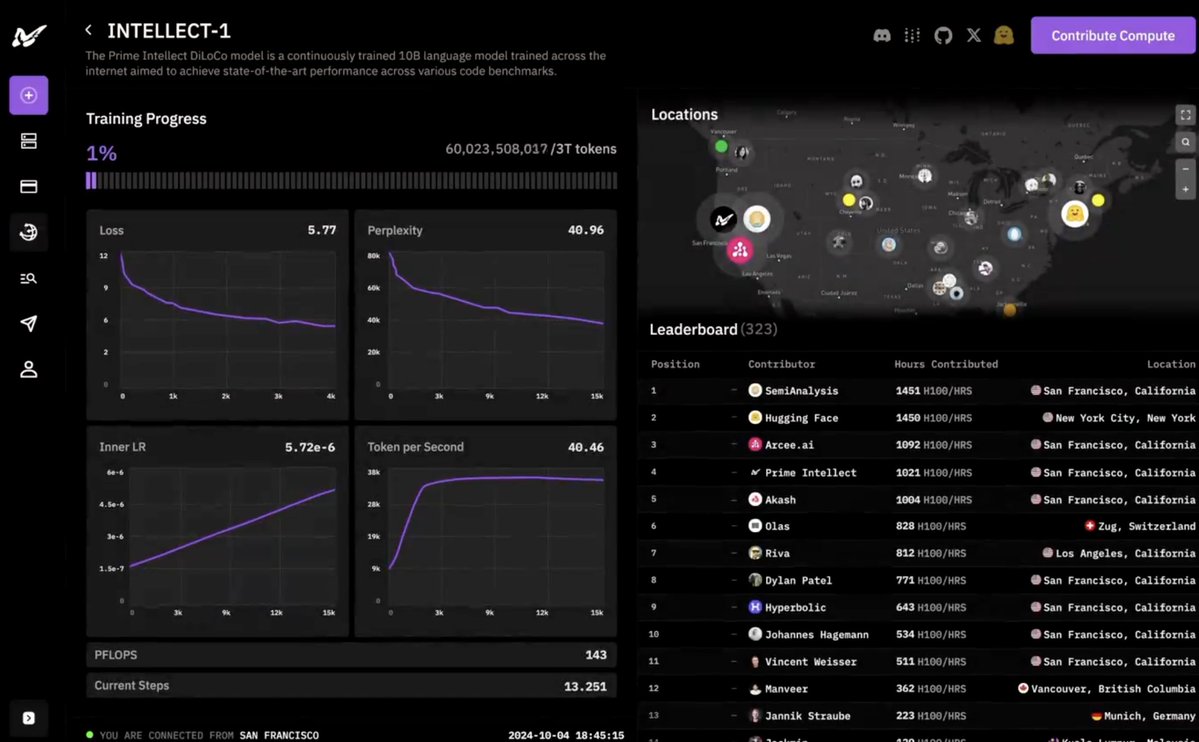
Exploring the power of distributed learning with @PrimeIntellect's 10B model! Fascinating how @GoogleDeepMind's DiLoCo uses Adam for inner and Nesterov for outer optimization, reducing bandwidth by 400x while maintaining efficiency. #DistributedLearning #AIResearch
14 Oct 2024

Distributed learning?
Recently, @PrimeIntellect have announced their 10B distributed learning (twitter.com/PrimeIntellect/s…), what is it exactly?
Going back to the origin, Federated Learning (FL, arxiv.org/abs/1602.05629) aims to train a model across a fleet of phones. To handle the low bandwidth between them, the gist is that each phone will perform multiple training steps (forward/backward & update) independently from each other. After a hundred of steps, each phone's replica of the model computes its trajectory (aka an outer gradient): it's simply a delta in the parameters space between where the model is now vs where it was at first.
Then, an all-reduce (thus no need of centralized server!) averages all the replicas outer gradients. Thus the peak communication is as high as in data-parallel (pytorch.org/docs/stable/gene…), but because it's only done rarely, its cost is amortized.
Now, those "outer gradients" are quite different from your classical gradients, but we can actually use an optimizer on those! FedOpt (arxiv.org/abs/2003.00295) proposes to optimize it with Adam, further accelerating training.
Most of the FL algorithms used however as inner/local optimizer SGD. This is suboptimal to train current large-scale transformer. In DiLoCo (arxiv.org/abs/2311.08105) from my team at @GoogleDeepMind, we use Adam as inner optimizer, but more importantly Nesterov as outer optimizer -- this simple change is ridiculously powerful:
With DiLoCo, you can now be as flops/token efficient as data-parallel training while using two orders of magnitude less bandwidth. A bunch of papers (arxiv.org/abs/2409.13198, arxiv.org/abs/2405.10853, arxiv.org/abs/2407.07852) have then re-used that winning recipes on large-scale transformers, including OpenDiLoCo.
In particular, OpenDiLoCo from @PrimeIntellect, is training a 10B (!) DiLoCo model across the world using Hivemind (github.com/learning-at-home/…), while synchronizing every 100 steps, and downcasting the outer gradients in int8. That's a 400x bandwidth reduction. This reduction is so big that, as @samsja19 noted, their speed bottleneck now is checkpointing on disk, not communication.
Godspeed @PrimeIntellect! 🫡
The other approach that has been made somewhat public is Distro from @NousResearch. For now, there is very little details, so it's hard to say how legit it is (read their report). But we know that one of the trick used is adding a regularization loss, forcing all replicas to stay close towards the global model that is synced once in a while. This is very reminiscent of ElasticSDG (arxiv.org/abs/1412.6651 @ylecun) and FedProx (arxiv.org/abs/1812.06127), which have also been re-visited recently with PAPA (arxiv.org/abs/2304.03094).
I strongly suspect it is still combined with some kind of outer optimization, in order to remain flops-efficient. We'll see.
The main point of this post is to show that there is very little new things in the recent distributed works, but that i think a lot of research on federated/distributed was artificial and done on toy settings. Now, the time is ripe for distributed training, see this @SemiAnalysis_ post: semianalysis.com/p/multi-dat…. There is lot of alpha into re-visiting past ideas, and investing heavily on the engineering parts to make them work, for real, at scale.

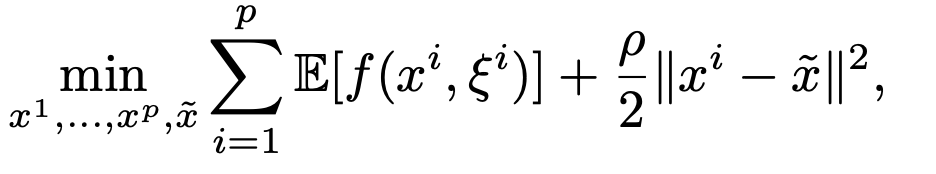
6
164

1 Oct 2024
Macrocosmos co-founders recently joined @blocmates on their TAO Talk podcast! @WSquires and @macrocrux discussed subnet validation, compossibility, and distributed learning, along with current developments happening within the Bittensor ecosystem. See the full chat here! 🪐🚀
#TechPodcast #decentralizedAI #distributedlearning $TAO #Bittensor
youtube.com/watch?v=fS3ZDZQc…
1
2
14
1,032

11 Jun 2024
#skillsforesight or #skillsforecast? #blendedlearning vs #distributedlearning?🤔
Check-out the 2024 "Terminology of #Europeaneducation & training policy", a multilingual glossary with 430 terms on EU policy priorities, #skillsintelligence & #Employment cedefop.europa.eu/en/publica…

7
10
506

29 May 2024
Exciting, non-RL tweet for a change. Long has written his first paper in his PhD with our group. If you are into #continuallearning, #multiagent learning or #distributedlearning, check it out! If you are not, check it out anyway. 😄
29 May 2024

1/4 📢 Excited to share our latest work on Distributed Continual Learning (DCL)! Large-scale AI models are powerful, but they're usually trained once due to costs. DCL lets AI constantly adapt & improve by learning from others.
3
581

Today we bring the answer to a question that we constantly receive based on the above: Why is a blockchain secure?
A blockchain is considered extremely secure and resistant to hacking for several reasons:
Decentralization: A blockchain is distributed across thousands of nodes around the world. This means there is no single point of failure. To hack a blockchain, an attacker would have to compromise a majority of nodes simultaneously, which is extremely difficult to achieve.
Robust cryptography: Information stored on a blockchain is protected by advanced cryptographic algorithms. Each transaction and block is securely linked using cryptographic hash functions, making it extremely difficult to alter information without detection.
Distributed Consensus: To add new blocks to a blockchain, a majority of nodes in the network must agree. This is achieved through consensus algorithms, such as Proof of Work (PoW) or Proof of Stake (PoS). These algorithms require a large amount of computational resources or a significant amount of financial involvement to conduct a successful attack.
Immutability: Once a block is added to the blockchain, it is virtually impossible to modify it without the consensus of the majority of the network. Any attempt to alter an existing block would change its hash and require modification of all subsequent blocks, which is extremely expensive and impractical.
Transparency and auditing: The information in a blockchain is transparent and accessible to all network participants. This means that any attempt to alter the data would be immediately detected by honest nodes on the network during verification of the blockchain.
In short, the combination of decentralization, robust cryptography, distributed consensus, immutability, and transparency makes a blockchain extremely difficult to hack. Although not impossible, successful attacks against well-established blockchains are extremely rare and require a significant amount of resources and coordination.
#Web3 #BlockchainEducation #CryptoCuriosities #DecentralizedLearning #Web3Wonders #BlockchainFacts #CryptoEducation #TechTrivia #DistributedLearning #CryptoFunFacts #Web3Exploration #BlockchainInsights #EducationalTech #CryptoKnowledge #Web3Discoveries

11
2
8
979

21 Oct 2023
Exploring the Intersection of Distributed Computing and Machine Learning: Rice University's Colloquium
#academicinstitutions #AI #algorithms #artificialintelligence #computingplatforms #distributedlearning #Engineering #FAIR #Google
multiplatform.ai/exploring-t…

ALT AI News
2
30

22 Sep 2023
I am very excited to have a chance to contribute to the tutorial on continual and pervasive AI at ECML PKDD 2023 in Turin. Thanks to my co-instructors Davide Bacciu, Claudio Gallicchio, Antonio Carta. pai.di.unipi.it/tutorial-on-… #ai #pervasiveai #distributedlearning
1
100

18 Sep 2023
The articles in our September issue include a tutorial on the training of spiking #NeuralNetworks , an overview of #deepreinforcementlearning for smart grid operations, and an overview of privacy and security for #distributedlearning. bit.ly/3LrTuje

2
12
5,972

28 Jul 2023
🆕 Fresh addition to ENCRYPT #BlogSeries
👉 "Ensuring Data Privacy in Distributed Learning"
by Martin Zuber, at @CEA_List, is now available at encrypt-project.eu/communica…
💡 Discover how #HomomorphicEncryption techniques are safeguarding sensitive information in #DistributedLearning
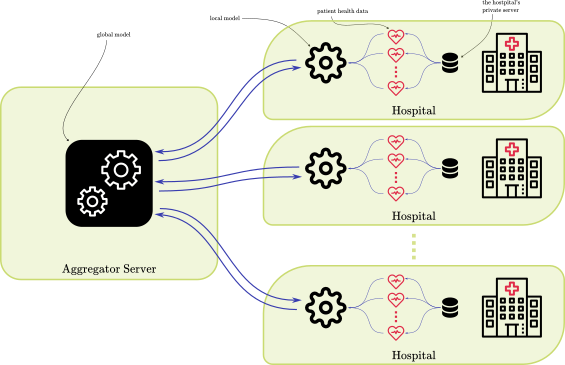
4
7
174

27 Jun 2023
Beyond excited to expand our work with the @ICRC
--
Thank you @EssTechEPFL and @ETH4D for this phenomenal opportunity! ❤️
#studentpower #impactthroughacademia #llms #distributedlearning #hiring #swe
@EPFL_en @ICepfl @CIS_EPFL
27 Jun 2023

So happy to be able to announce these 5 new Humanitarian Action Challenge projects! @EPFL_en @ETH_en @ETH4D Read on 👇 linkedin.com/posts/essential…
5
553

16 Jun 2023
The "slides" notebook from my talk on a #meetup about "Barrier Scheduling and #DistributedLearning on #ApacheSpark with #LightGBM"
➡️ github.com/jaceklaskowski/le…
There are a few order-related flows but overall it's ready for...public consumption 😉 Enjoy! ❤️




2
692
1 Jun 2023
What a #meetup! Just finished presenting what I managed to learn about #DistributedLearning on #ApacheSpark (and #Databricks) using libraries like #PyTorch #xgboost ❤️
➡️ meetup.com/warsaw-data-engin…
Enjoyed it so much that I can't wait for next meetups! Feeling so...(xg)boosted! 😉
1
1
4
756