
Apr 29
What is the relation between gradient boosting and AdaBoost?
Jr Analyst: Boosting is sequentially building models trying to predict errors made by previous model
Sr Data Scientist: youtu.be/IMvqD0hGYEA?si=YIAm…
Happy learning!
#ensemblemethods
#machinelearning
#datascience
1
45

30 Sep 2025
Towards robust databases: an ensemble-based workflow for error detection applied to chemical data
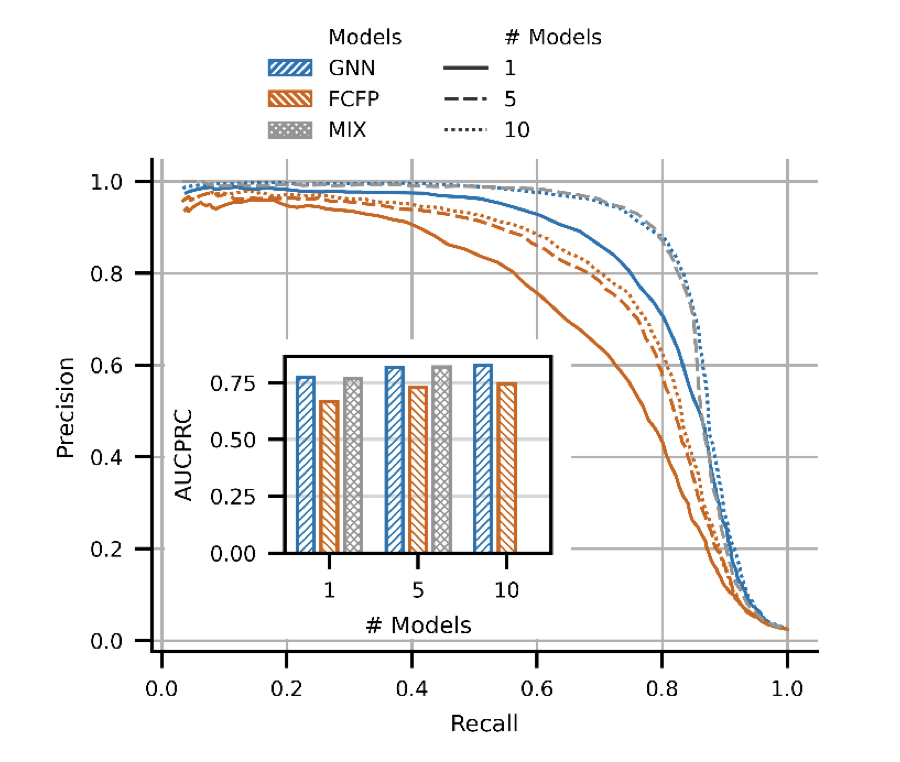
1. This study introduces a validated and refined “yellow cards” error detection workflow for chemical data, which can be applied to any property connected to molecular structure. The workflow uses five predictive models to flag potentially erroneous entries with high precision.
2. The core innovation lies in the ensemble approach: each model assigns a “yellow card” to the 5% of entries with the worst prediction accuracy. Entries receiving five “yellow cards” are considered erroneous. This method effectively leverages model diversity to enhance error detection.
3. The study confirms five key hypotheses: models generalize well and ignore errors during training; prediction errors across different model architectures are weakly correlated; the group with the most “yellow cards” is dominated by erroneous entries; the U-shaped distribution of entries across groups and inverted-U pattern in standard deviations serve as robust indicators of workflow performance.
4. The “yellow cards” workflow outperforms simpler methods like absolute error or percentile-based approaches in precision-recall metrics. This makes it a superior choice for identifying and filtering out errors in large chemical datasets.
5. The researchers provide a detailed, actionable plan for applying this method to new datasets, emphasizing model diversity, hyperparameter optimization, threshold selection, and iterative refinement using diagnostic plots. This plan is designed to be adaptable to various molecular properties.
6. The study uses two computational datasets (descriptor-based and QM9-based) with controlled errors to rigorously test and validate the workflow. This approach allows for a thorough assessment of the method’s performance and versatility.
7. The findings have broad implications for improving data quality in chemistry and molecular sciences, potentially enhancing the reliability of machine learning models trained on such data. This work paves the way for more robust and reliable data curation practices.
📜Paper: doi.org/10.26434/chemrxiv-20…
#ChemistryData #ErrorDetection #MachineLearning #DataQuality #EnsembleMethods
1
2
5
1,262

13 Nov 2024
Ensemble methods combine the predictions of multiple models, leading to higher accuracy, greater stability, and reduced bias.
These methods bring some serious power to your toolkit. Learn more here! 👇
hubs.la/Q02Y6ryG0
#EnsembleMethods #DataScience #AI #MLTechniques
2
1,307

9 Nov 2024
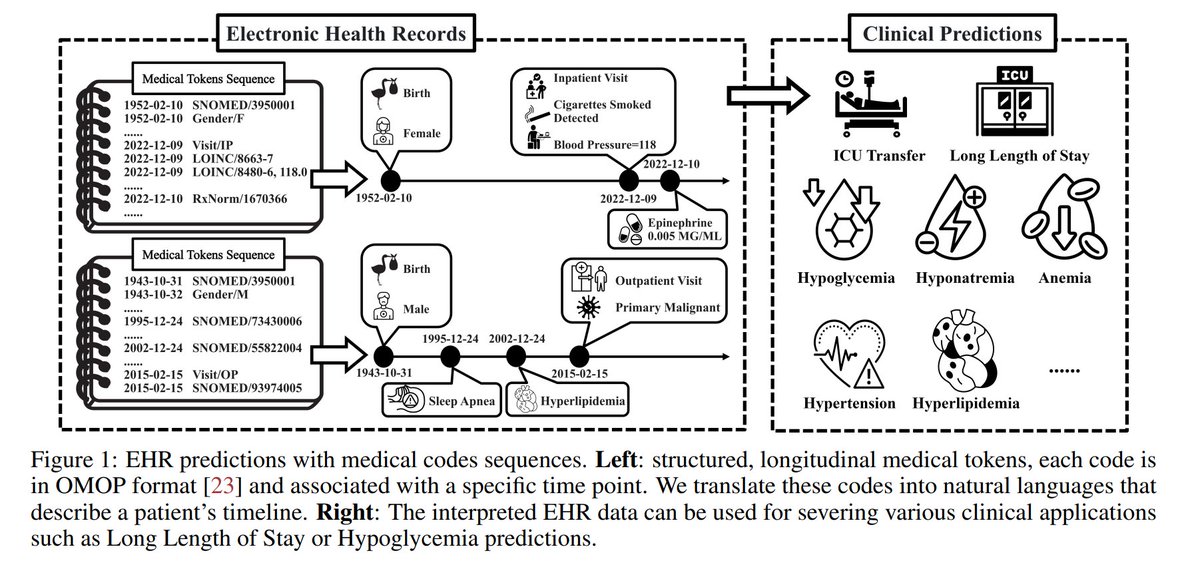
8/25 Uncertainty Quantification for Clinical Outcome Predictions with (Large) Language Models
This paper investigates uncertainty quantification of Language Models (LMs) for clinical prediction tasks using EHRs, addressing the need for reliable automated predictions in healthcare.
Using multi-tasking and ensemble methods in both white-box (accessible parameters and logits) and black-box (e.g., GPT-4) settings, they demonstrate uncertainty reduction on longitudinal clinical data from over 6,000 patients across ten clinical prediction tasks.
Results show that ensembling and multi-task prompting reduce uncertainty, improving transparency and reliability in AI healthcare.
#UncertaintyQuantification #LanguageModels #EHR #ClinicalPrediction #AIHealthcare #EnsembleMethods #MultiTaskLearning
Paper Link: arxiv.org/abs/2411.03497
1
2
146
4 Oct 2024
Tired of building models that underperform? Ensemble methods are here to save the day!
Discover popular techniques like bagging, boosting, and stacking. Check out our blog post for a comprehensive guide!
hubs.ly/Q02SfVbr0
#MachineLearning #EnsembleMethods #AI
1
6
1,589

6 Jun 2024
When forecasting #stockprices, we can use traditional time series analysis techniques in #machinelearning, such as ARIMA or SARIMA models, LSTM networks are tailored to handle sequential data like stock prices #PredictiveModels #Stocks #EnsembleMethods
1
2
65

15 Dec 2023
Methods to Reduce Underfitting in Machine Learning! 📊
#Underfitting #MachineLearning #Regularization #DataAnalysis #Analytics #FeatureEnhancement #BigData #EnsembleMethods #Regularization #NeuralNetworks #RandomForests #DataCleaning #DataAnalytics #DataScience #BuymoreAnalytix

1
6
75

11 Sep 2023
📢 New Blog: "Ensemble Methods in AI: Building Stronger Models" 🤖✨ Discover the power of ensemble techniques in #AI and #MachineLearning. Boost accuracy and robustness. Read now: njoroge.tomorrow.co.ke/blog/…
#DataScience #EnsembleMethods
2
26

18 Jun 2023
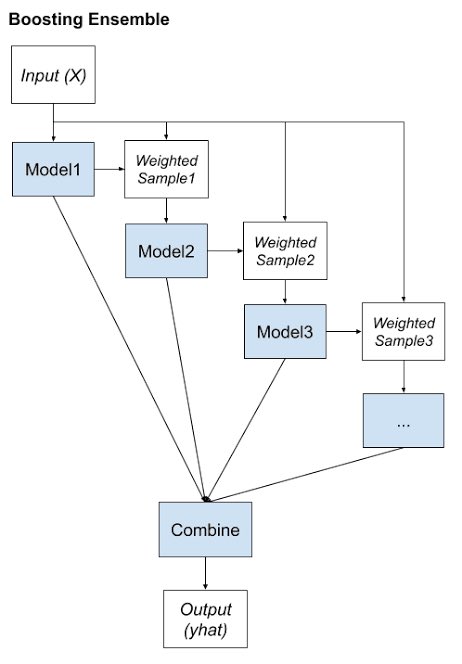
ML101
Ensemble Methods in Machine Learning show the power of collaboration. Techniques like Bagging reduce variance by averaging multiple models trained on bootstrapped datasets. Boosting iteratively trains weak learners to reduce bias, inspired by the concept of weighted majority voting. The math behind these methods reveals how aggregating multiple perspectives can lead to more robust and accurate decisions. Who knew democracy had such deep roots in ML? #MachineLearning #AI #EnsembleMethods #Mathematics
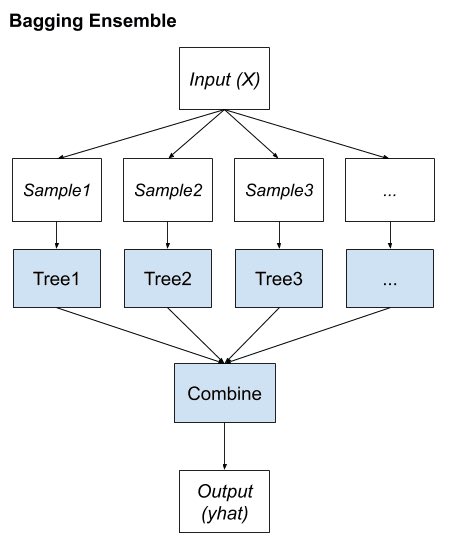
1
202

13 Feb 2023
Ensemble methods in machine learning utilize a combination of different base models to produce a single, more robust and accurate predictive model.
#ensemblemethods #machinelearning #regression #Classification #datascience #artificialintelligence #PredictiveModeling #basemodels
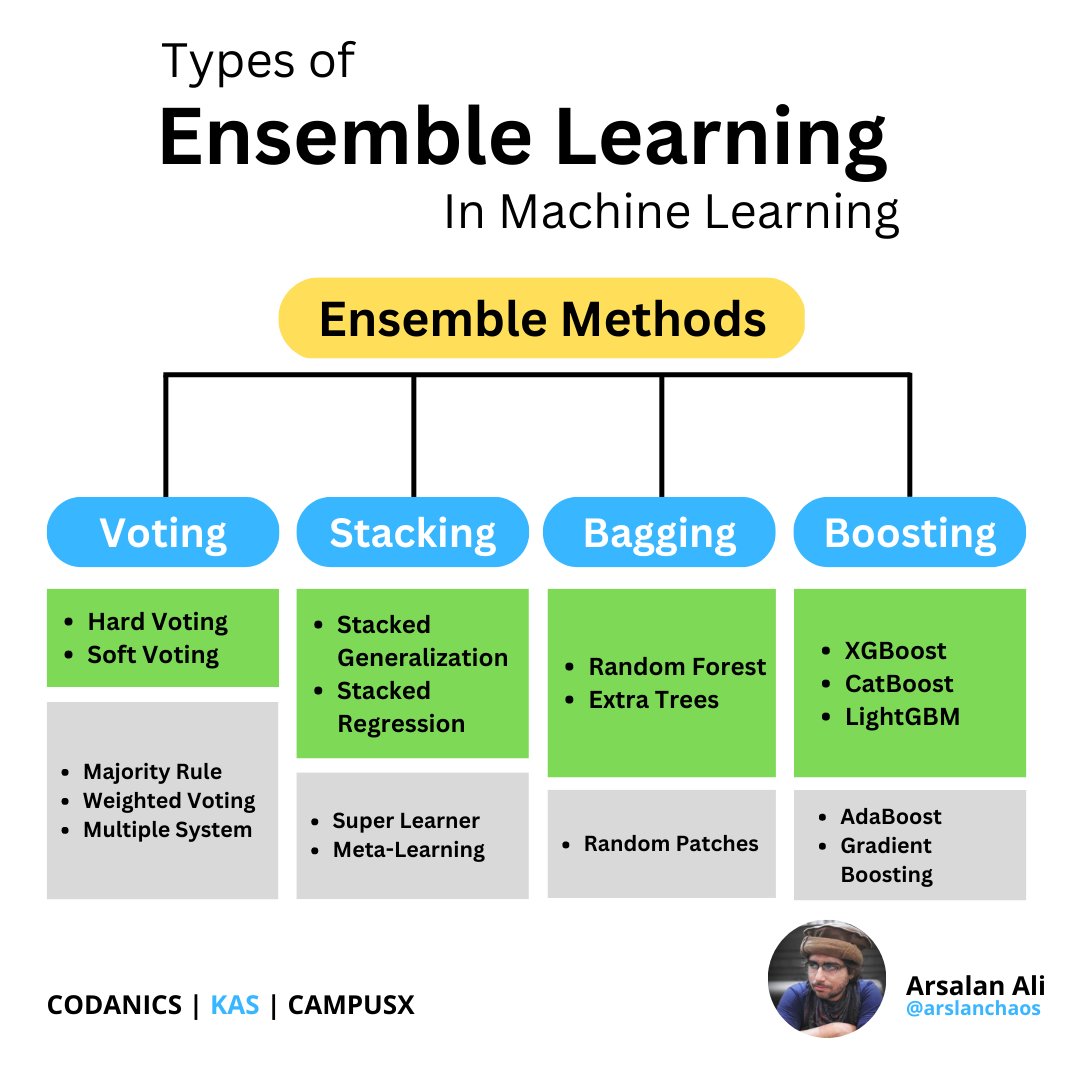
4
9
403

17 Jan 2023
#highlycitedpaper
The Use of Ensemble Models for Multiple Class and Binary Class Classification for Improving Intrusion Detection Systems
mdpi.com/1424-8220/20/9/2559
#intrusiondetectionsystem #ensemblemethods #featureselection #machinelearning #artificialintelligence
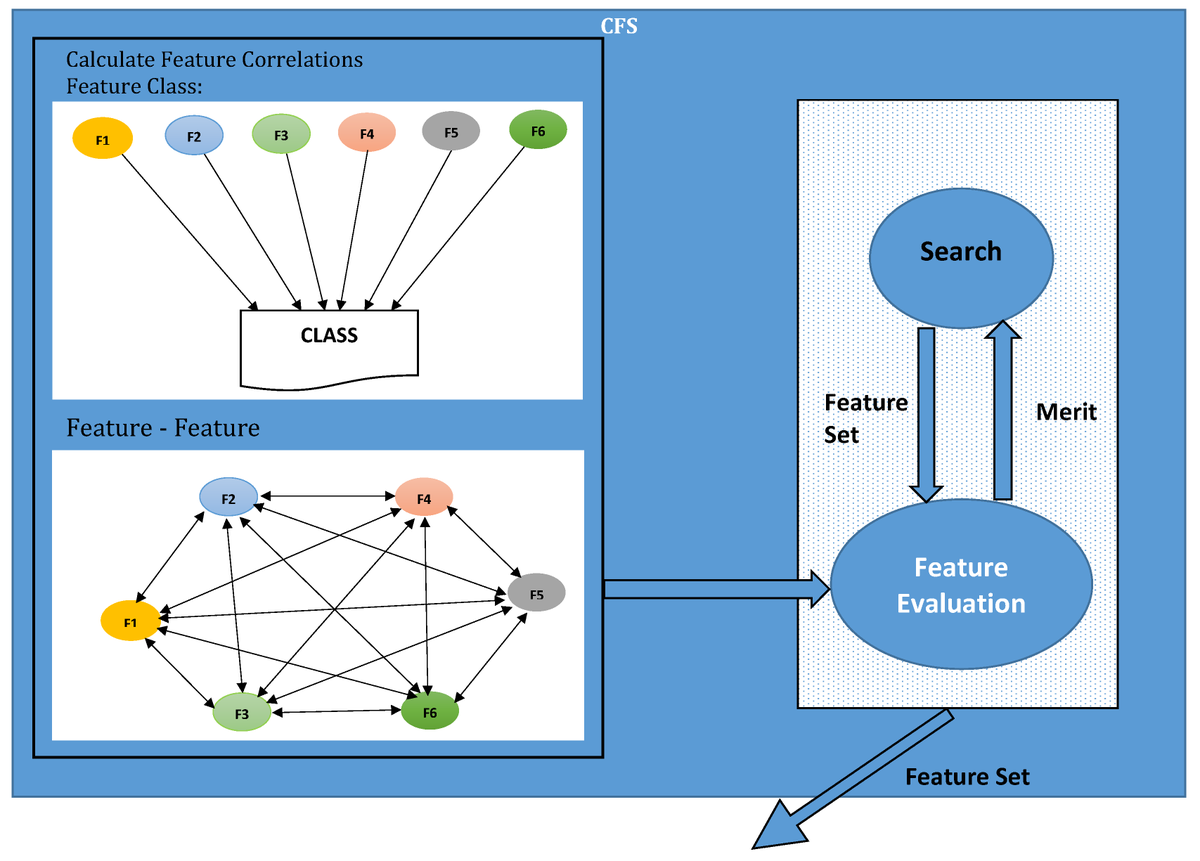
2
280

16 Jun 2021
Join us in 2 weeks with Turing Technologies and Melius Investments as we discuss the possibilities of Ensemble Methods in Active Portfolio Management. hubs.la/H0QqmG40
#Smartleaf #fintech #ensemblemethods #wealthtech #webinar

1
2

28 Apr 2021
oa.upm.es/66868/ On the adaptability of ensemblemethods for distributed classificationsystems: A comparative analysis
2

11 Apr 2021
#slideshare: Start implementing the most important ensemble ML methods with Ensemble Methods for Machine Learning. mng.bz/BKRl @gkunapuli #ensemblemethods #ML #machinelearning

3
26 Mar 2021
See how to use scikit-learn’s homogeneous parallel ensemble modules in practice. Case Study: Breast Cancer Diagnosis link.medium.com/3Pm2sRiMWeb #EnsembleMethods #MachineLearning #Algorithms #HealthTech
2
5
22 Sep 2020
Sometimes you need more than a single model or algorithm to resolve a machine learning problem.
Sometimes Ensemble Methods for Machine Learning is your only solution. mng.bz/Mo7o @gkunapuli
#ensemblemethods #ML #machinelearning

1
3
15 Sep 2020
Start implementing the most important ensemble ML methods with Ensemble Methods for Machine Learning. mng.bz/oRep @gkunapuli #ensemblemethods #ML #machinelearning
2
2
9 Sep 2020
Dig deep into the wisdom of crowds and get multiple Ml models work together on solving the problem, with Ensemble Methods for Machine Learning. mng.bz/oRep @gkunapuli #ensemblemethods #ML #machinelearning
1
2

2 Jul 2020
I still occasionally read those rag b/c between them all Istart to see the image of what’s really going on by identifying which elements each focuses on and conversely downplays.
It’s like #ensemblemethods in #MachineLearning. Noise will destructively interfere, leaving signal.
1

3 Jan 2020
Crunched for time but want to learn #ensemblemethods?
This blog demonstrates some methods to improve the performance of #decisiontrees & focuses on ensemble methods like #Bagging and #Boosting to build decision trees.
Check it out here: blog.quantinsti.com/ensemble…
4