
📣 TOTh 2026 successfully concluded in Chambéry!
🔗 See the full press release here: talos-ai4ssh.uoc.gr/toth2026…
#HorizonEU #ResearchImpactEU #EUInnovation #TALOSAI4SSH #AI4SSH #Terminology #Ontology #ArtificialIntelligence #KnowledgeRepresentation #Conferences #Trainings


30

May 26
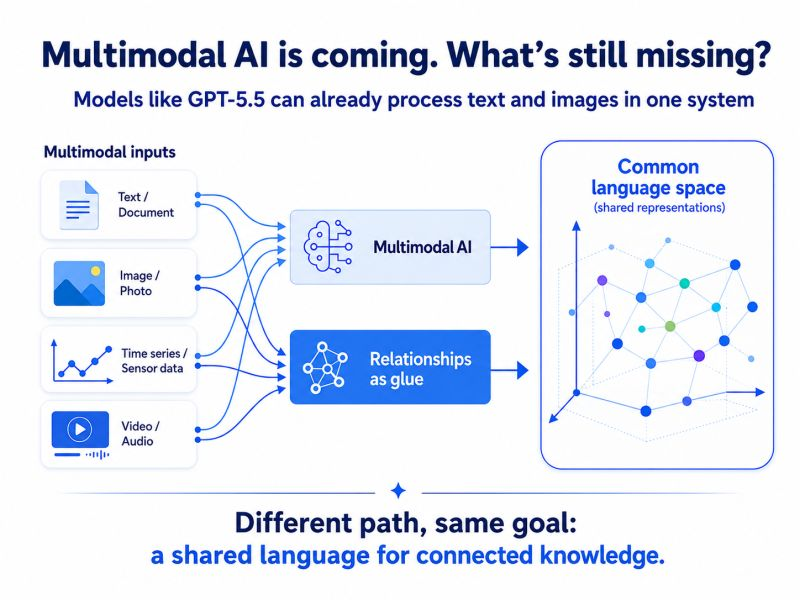
Giving AI a Shared Language: Unified Knowledge Graphs for Multimodal Data
Multimodal AI is moving fast: systems like GPT-5.5 can already process text and images in one system.
If multimodal AI is moving this fast, do we still need Unified Knowledge Graphs?
Multimodal AI and Unified Knowledge Graphs are two different paths toward the same goal.
A multimodal AI system can learn a common language implicitly.
In a Unified Knowledge Graph, the common language is built through explicit relationships.
That makes the structure more visible, reusable, and easier to verify.
Unified Knowledge Graphs are a relationship-aware layer around AI systems.
GPT-5.5 can process the pieces.
Relationships explain how they belong together.
By Elena Romanova
linkedin.com/feed/update/urn…
#MultimodalAI #UnifiedKnowledgeGraph #KnowledgeRepresentation #ExplainableAI #GraphTechnology #LLM #AIArchitecture #DataIntegration #GPT5
--
Join the Conversation
Subscribe to the Year of the Graph newsletter for quarterly insights on #KnowledgeGraphs, #GraphDB, Graph #Analytics, #AI, #DataScience and #SemTech .
📧 Subscribe: yearofthegraph.xyz/newslette…
💼 Sponsorship inquiries: yearofthegraph.xyz/contact/
4
11
447

May 14
Can we trust ontologies generated by LLMs?
Large Language Models are becoming powerful assistants for Knowledge Graph and Ontology Engineering. But when they generate ontologies, they can also introduce subtle — and sometimes critical — modeling mistakes.
"Pitfalls in AI-Generated Ontologies: Strategies for Detection and Mitigation" discusses how to move from enthusiasm to reliability when using LLMs for ontology engineering, with two concrete contributions:
Ontology Pitfalls Detector, a new open-source tool that detects mistakes in LLM-generated ontologies.
Ontology Toolkit by Lettria, a platform for automatically building ontologies from documents — while avoiding common ontology design mistakes.
Pitfall Detection evaluation library:
* tailored to LLM-generated ontologies
* structural, logical, naming, and semantic issues
* complementary to existing ones
Input
* OWL/RDF ontology
Detection techniques
* SPARQL queries
* Hierarchy analysis
* Semantic similarity
SBERT
Distance over WordNet
* LLM-as-a-judge
Ontology Toolkit(generation pipeline)
Goal: Automatically generate high-quality ontologies from unstructured text
Approach
* Deterministic, multi-stage pipeline
* Each stage:
Produces structured intermediate outputs
Applies strict validation correction loops
Core Principles
* Use-case driven extraction (focus on relevant concepts)
* Explicit semantics (no implicit or ambiguous modeling)
* Controlled hierarchy construction (avoid flat or noisy structures)
* Logical enrichment with OWL axioms
By Raphael Troncy Pasquale Lisena, Julien PLU, Oscar Moreno Escobar and Edouard Trouillez EURECOM Lettria
Ontology Pitfalls Detector: github.com/D2KLab/Ontology-P…
Ontology Toolkit: perseus.lettria.com
Presentation: docs.google.com/presentation…
#LLMs #OntologyEngineering #SemanticWeb #GenerativeAI #ResponsibleAI #KnowledgeRepresentation #EmergingTech
--
Connected Data London 2026 | 11–12 November | Leonardo Royal Hotel London Tower Bridge
🎤 Share your work with the world's most passionate data community. The Call for Submissions is open. connected-data.london/2026-c…
🎟 Tickets on sale now. Early bird discounts up to 30%. 2026.connected-data.london
📺 Sponsorship opportunities available. Contact info@connected-data.london for details.
#KnowledgeGraph #GraphRAG #Ontology #Graph #AI #DataScience #GraphDB #SemTech

2
14
711

Mar 13
We welcome rigorous critique, questions, independent replications, and discussion.
Priority replications include: extension to other neural architectures, direct microtubule-level tests, projection of non-biological hierarchies onto the frozen manifold.
Feedback requested. Let’s debate. n/n
#Physics #Neuroscience #ArtificialIntelligence #KnowledgeRepresentation
2
4
9
977
Feb 13
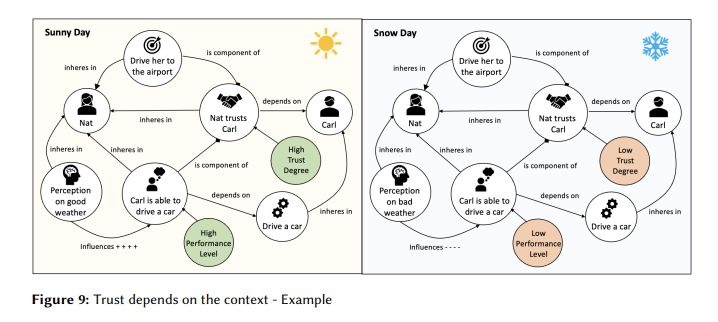
ONTrust: A Reference Ontology of Trust
Trust has stood out more than ever in the light of recent innovations. Some examples are advances in artificial intelligence that make machines more and more humanlike, and the introduction of decentralized technologies (e.g. blockchains), which creates new forms of (decentralized) trust.
These new developments have the potential to improve the provision of products and services, as well as to contribute to individual and collective well-being.
However, their adoption depends largely on trust. In order to build trustworthy systems, along with defining laws, regulations and proper governance models for new forms of trust, it is necessary to properly conceptualize trust, so that it can be understood both by humans and machines.
This paper is the culmination of a long-term research program of providing a solid ontological foundation on trust, by creating reference conceptual models to support information modeling, automated reasoning, information integration and semantic interoperability tasks.
To address this, a Reference Ontology of Trust (ONTrust) was developed, grounded on the Unified Foundational Ontology and specified in OntoUML, which has been applied in several initiatives. For example, to demonstrate how it can be used for:
* Conceptual modeling and enterprise architecture design
* Language evaluation and (re)design
* Trust management
* Requirements engineering, and for
* Trustworthy AI in the context of affective Human-AI teaming
ONTrust formally characterizes the concept of trust and its different types, describes the different factors that can influence trust, as well as explains how risk emerges from trust relations.
To illustrate the working of ONTrust, the ontology is applied to model two case studies extracted from the literature.
By Glenda Amaral, Tiago Prince Sales, Riccardo Baratella, Daniele Porello, Renata Guizzardi, Giancarlo Guizzardi.
arxiv.org/abs/2602.07662
#Research #Trust #TrustworthyAI #AIGovernance #HumanAITeaming #BlockchainTrust #DecentralizedTrust #EnterpriseArchitecture #TrustOntology #OntologyEngineering #SemanticWeb #ConceptualModeling #OntoUML #SemanticInteroperability #KnowledgeRepresentation #SoftwareEngineering #InformationSystems #AIEthics #ComputerScience
--
Connected Data London 2025 brought together leaders and innovators. Were you there?
🎥 Watch the sessions: 2025.connected-data.london/
📩 Join the community: connected-data.london
Join community legends and new voices in #CDL25 for all things #KnowledgeGraph #Graph #analytics #datascience #AI #graphDB #SemTech #Ontology
2
212

14
Before AI can learn patterns,
it must understand structure.
Logic is the skeleton of intelligence.
Follow for no-hype insights on AI, thinking, and future skills.
#ArtificialIntelligence #AI #KnowledgeRepresentation
#Logic #ComputerScience #AIExplained #FutureSkills
2
10

Jan 18
My latest article
Orchestrating Global Trade through Executable Knowledge and Semantic Sovereignty
linkedin.com/posts/emekaokoy…
#AI #Ontology #KnowledgeGraph #KnowledgeRepresentation #SemanticWeb #NeuroSymbolicAI
5
6
1,120
Jan 14
2026 is definitely the year of Ontology.
The real revolution is not "AI" but Meaning.
bigthink.com/business/why-th… cc @kidehen @asemota @Syntaxia_ @bayoadekanmbi
#AI #Ontology #KnowledgeGraph #KnowledgeRepresentation #SemanticWeb #NeuroSymbolicAI
1
4
230

18 Jul 2025
Our Research Scientist, Daniel Rogozin, has published a new paper: "Term Assignment and Categorical Models for Intuitionistic Linear Logic with Subexponentials".
This work represents a significant step toward developing next-generation knowledge representation languages that could transform how intelligent systems process information.
Read it on ArXiv: arxiv.org/abs/2507.12360
#TypeTheory #CategoryTheory #KnowledgeRepresentation #TheoreticalComputerScience #ProofTheory #LinearTypes

4
272

14 Jul 2025
#Article
📜 Hierarchical Understanding in Robotic Manipulation: A Knowledge-Based Framework
by Runqing Miao, et al.
mdpi.com/2076-0825/13/1/28
@Tsinghua_Uni
@ShenzhenUni
@MDPIEngineering
#roboticmanipulation #knowledgerepresentation #knowledgeupdate #knowledgereasoning

2
6
1,052

21 May 2025
Continuing in the Special Session at #ESCIM2025: Manuel Ojeda-Aciego presents "Composition as a Fuzzy Conjunction Between Indexes of Inclusion." A deep dive into fuzzy logic and relational structures! #FuzzyLogic #KnowledgeRepresentation #Mathematics @InfoUMA

2
2
30
21 May 2025
In the special session "Recent Trends in Knowledge Representation and Modelling" at #ESCIM2025: Domingo López-Rodríguez from @InfoUMA presents “(Ab) New Simplification Rules for Databases with Positive and Negative Attributes”. #Databases #KnowledgeRepresentation #Logic

2
3
37
21 May 2025
Kicking off the special session "Recent Trends in Knowledge Representation and Modelling" at #ESCIM2025: Samuel Molina from @univcadiz presents "Vertical Sum of Concept Lattices via Bonds." Great insights into #FormalConceptAnalysis #KnowledgeRepresentation #Mathematics

1
2
24

14 May 2025
PhD Opportunity: Knowledge Representation and Learning for Smart Agriculture
Location: University of Guelph
Application Deadline: August 1st, 2025
Start Date: Fall 2025 or Winter 2026
Funding: Fully funded PhD position (4 years)
Contact: syang19@uoguelph.ca
We are seeking an exceptional PhD candidate to join our research team working at the intersection of Artificial Intelligence, Knowledge Representation, and Smart Agriculture. The position focuses on developing innovative approaches to model, integrate, and apply agricultural knowledge for intelligent decision-making in digital farming systems.
How to Apply
- Send the following documents to syang19@uoguelph.ca
- CV (max 2 pages)
- Statement of interest (max 1 page)
- Academic transcripts (undergrad and grad)
- Contact information for two referees
#AI4Agrifood #knowledgeRepresentation #MachineLearning #PhDhiring

1
9
612

14 May 2025
Automating AI Discovery for Biomedicine Through Knowledge Graphs And LLM Agents
1.This paper introduces a novel framework that combines semantic knowledge graph traversal with a multi-agent LLM system to automatically generate computational research proposals in biomedicine.
2.At the core of the framework is a three-stage pipeline: semantic embedding using PubMedBERT, guided graph search to find biologically meaningful paths between entity pairs, and iterative research design by specialized LLM agents.
3.The system begins by embedding biomedical entities and their relationships from Hetionet using PubMedBERT, ensuring domain-specific semantic representations.
4.A bidirectional beam search algorithm, enhanced with semantic waypoints, is used to discover non-obvious but biologically plausible paths between entities in the knowledge graph, bypassing the pitfalls of hub-dominated traversal in large biomedical graphs.
5.Once a path is found, a three-agent LLM system—comprising Analyst, Scientist, and Reviewer roles—collaborates iteratively to propose, critique, and refine a full research plan grounded in the discovered graph.
6.The Analyst Agent defines and contextualizes each graph node and relationship; the Scientist Agent formulates an AI-based research design; and the Reviewer Agent critiques it on scientific rigor, feasibility, clarity, and novelty.
7.Each proposal goes through multiple refinement rounds, mimicking academic peer review, and is scored on four dimensions: Relevance, Feasibility, Significance, and Verifiability, using a stringent, evidence-based scoring protocol.
8.Across ten biomedical entity pairs—e.g., "Leptin signaling pathway → Rheumatoid arthritis" or "Mitochondrial protein complex → Parkinson’s disease"—the system generated novel AI tasks with scores as high as 8.75/10, reflecting biological plausibility and scientific rigor.
9.For example, in the leptin–arthritis case, the system proposed a hybrid GraphSAGE and RNN-LSTM model to assess risk via AKT1 and Cyclosporine—backed by detailed data, architecture, and validation plans.
10.All AI designs are stored with full iteration history, feedback, evaluation scores, and implementation details, allowing post-hoc analysis and reproducibility.
11.A web-based tool, Intelliscope, provides public access to this system, offering end-to-end automated biomedical research design via a user-friendly dashboard.
12.This framework addresses the problem of literature overload in biomedicine, using structured knowledge and LLMs to generate grounded, innovative research hypotheses that might otherwise be missed.
📜Paper: biorxiv.org/content/10.1101/…
#AI4Science #BiomedicalKnowledgeGraphs #LLMAgents #AutomatedResearch #ComputationalBiology #Bioinformatics #GraphSearch #ScientificDiscovery #AutoML #KnowledgeRepresentation

7
25
1,893
14 May 2025
Automating AI Discovery for Biomedicine Through Knowledge Graphs And LLM Agents
1.This paper introduces a novel framework that combines semantic knowledge graph traversal with a multi-agent LLM system to automatically generate computational research proposals in biomedicine.
2.At the core of the framework is a three-stage pipeline: semantic embedding using PubMedBERT, guided graph search to find biologically meaningful paths between entity pairs, and iterative research design by specialized LLM agents.
3.The system begins by embedding biomedical entities and their relationships from Hetionet using PubMedBERT, ensuring domain-specific semantic representations.
4.A bidirectional beam search algorithm, enhanced with semantic waypoints, is used to discover non-obvious but biologically plausible paths between entities in the knowledge graph, bypassing the pitfalls of hub-dominated traversal in large biomedical graphs.
5.Once a path is found, a three-agent LLM system—comprising Analyst, Scientist, and Reviewer roles—collaborates iteratively to propose, critique, and refine a full research plan grounded in the discovered graph.
6.The Analyst Agent defines and contextualizes each graph node and relationship; the Scientist Agent formulates an AI-based research design; and the Reviewer Agent critiques it on scientific rigor, feasibility, clarity, and novelty.
7.Each proposal goes through multiple refinement rounds, mimicking academic peer review, and is scored on four dimensions: Relevance, Feasibility, Significance, and Verifiability, using a stringent, evidence-based scoring protocol.
8.Across ten biomedical entity pairs—e.g., "Leptin signaling pathway → Rheumatoid arthritis" or "Mitochondrial protein complex → Parkinson’s disease"—the system generated novel AI tasks with scores as high as 8.75/10, reflecting biological plausibility and scientific rigor.
9.For example, in the leptin–arthritis case, the system proposed a hybrid GraphSAGE and RNN-LSTM model to assess risk via AKT1 and Cyclosporine—backed by detailed data, architecture, and validation plans.
10.All AI designs are stored with full iteration history, feedback, evaluation scores, and implementation details, allowing post-hoc analysis and reproducibility.
11.A web-based tool, Intelliscope, provides public access to this system, offering end-to-end automated biomedical research design via a user-friendly dashboard.
12.This framework addresses the problem of literature overload in biomedicine, using structured knowledge and LLMs to generate grounded, innovative research hypotheses that might otherwise be missed.
📜Paper: biorxiv.org/content/10.1101/…
#AI4Science #BiomedicalKnowledgeGraphs #LLMAgents #AutomatedResearch #ComputationalBiology #Bioinformatics #GraphSearch #ScientificDiscovery #AutoML #KnowledgeRepresentation

648

Standardized knowledge representation is key to collaborative AI.
Ontologies offer:
🧠 Shared vocab
🔗 Clear relationships
🗣️ Semantic context
🤝 Interoperability
Without shared meaning, connected AIs stay isolated.
#Ontology #KnowledgeRepresentation

11
8
16
508
27 Feb 2025
Flawless Semantic Modeling in OWL and SKOS - The Practice
Hands-on experience of developing a semantic model in OWL and SKOS, with progressive exercises designed to illustrate pitfalls we need to avoid and dilemmas we need to break during the modeling process.
Based on the O'Reilly book "Semantic Modeling for Data"
Key Topics
* When to use SKOS versus when to use OWL
* When to model an entity as a class versus when to model it as an individual
* How to properly model subclasses, parts and other semantic relations
* How to choose meaningful names for the model’s elements
* How to document assumptions and design decisions
* How to deal with vagueness
Target Audience
* Knowledge engineers
* Ontologists
* Taxonomists
* Data practitioners who develop semantic data models
* Technical leaders who want hands-on semantic modeling experience
Goals
* Get hands-on experience using schemas, knowledge graphs and NLP to develop a long-tail SEO strategy
Session outline
* Hands-on experience with OWL, SKOS, and Protege
Format
* This class will be highly collaborative and interactive.
For the modeling exercises we will work on Protege (standalone and/or web version)
All the exercises and solutions will be made available to the attendees after the conclusion of the masterclass.
Level
* Beginner - Intermediate
Prerequisite Knowledge
* Basic knowledge of OWL and SKOS
* Attendance of Flawless Semantic Modeling in OWL and SKOS - The Theory is recommended but not obligatory
--
Panos Alexopoulos: Head of Ontology, Textkernel
Working since 2006 at the intersection of data, semantics, and software, contributing to building intelligent systems that deliver value to business and society. Currently Head of Ontology at Textkernel BV, leading a team of data professionals in developing and delivering a large cross-lingual Knowledge Graph in the HR and Recruitment domain. Author of the book "Semantic Modeling for Data - Avoiding Pitfalls and Breaking Dilemmas" (O'Reilly, 2020)
--
Welcome to Connected Data London's #ThrowbackThursday
Every Thursday at 3pm GMT, we are releasing gems from our vault on #YouTube
Tune in and learn from leaders and innovators; subscribe to our channel and watch premieres as they are released!
#KnowledgeGraph #Ontology #DataModeling #AI #KnowledgeRepresentation #EmergingTech #SemanticWeb #SemTech
youtu.be/kQSVu_V5JRY
3
172
13 Feb 2025
25 Oct 2017

1
1
3
222
7 Feb 2025
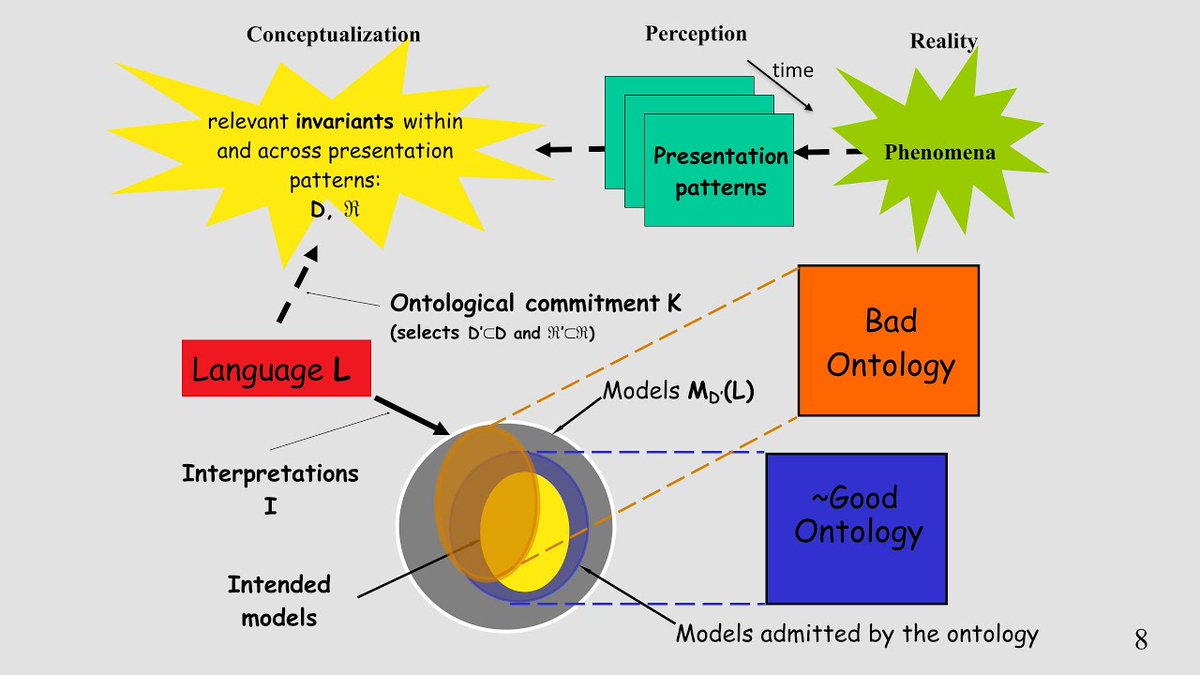
Ontologies as specifications of conceptualizations: correctness, precision, and accuracy
Ontology Summit 2025 Keynote by Nicola Guarino
Ontologies are seeing renewed interest by a wider audience as a way to ground shared meaning for human and AI interactions. This talk by one of the founders of the field of ontology in computer science covers many different aspects of ontological theory and practice.
Philosophical ontologies focus on the nature and structure of reality. Computational ontologies are specific artifacts that express the intended meaning of a vocabulary, preferably in a machine-readable form.
Successful computational ontologies blend philosophical, cognitive, and linguistic aspects, emphasizing their role in communication and understanding people's assumptions about reality.
Ontological Analysis involves studying the content and assumptions independently of their representation, aiming to clarify the relationship between ontologies and conceptualizations.
- Explicit Formal Specifications of Conceptualizations: Referencing Tom Gruber's 1993 definition which proposes that ontologies are formal specifications of conceptualizations.
- Intentional vs. Extensional Relations: Distinction between relations that are intentional (related to possible worlds) and extensional (related to the actual world).
Evaluation of Ontologies
- Correctness: An ontology is correct if all intended models are covered.
- Precision: The degree to which admitted models coincide with intended ones.
Examples in Ontology Precision
- Service Commitment Example: Demonstrated how differing interpretations can lead to false agreements if ontologies are not precise.
- Core Vocabularies: Highlighted issues with under-specification, as seen with schema.org, stressing that precision is crucial for interoperability.
Models vs. Situations
Emphasized the need for ontologies to account for real-world situations, not just logical models.
Role of Ontologies in Semantic Integration
- Shared domain and terminology result in no misunderstandings.
- Different conceptualizations require robust ontologies for integration.
A well-founded ontology uses primitives and general categories from philosophical theories to ensure mutual understanding.
youtube.com/watch?v=7myIaXWH…
For more Presentations, Keynotes, Masterclasses, and Workshops on cutting-edge topics from industry leaders and innovators:
connected-data.london
#KnowledgeGraphs #DataScience #AI #GraphDB #Analytics #SemTech #EmergingTech #Ontology #Semantics #AI #KnowledgeRepresentation #TechTalk
1
9
579