
On the (In)Security of Loading Machine Learning Models
We identified six zero-day vulnerabilities, including the first CVEs ever assigned to Keras safe_mode. Our results show that loading a machine learning model can be equivalent to executing untrusted code, despite the security claims often present in framework and hub documentation.
We also show that Hugging Face’s integrated scanners do not always provide an effective additional line of defense against framework-level exploits. Finally, through a survey of machine learning practitioners, we show that security claims in framework and hub documentation can create misplaced trust. For example, over 90% of non-security ML practitioners perceived no risk of arbitrary code execution when safe_mode=True.
Source: arxiv.org/pdf/2509.06703
#MLSecurity #AISecurity #ModelSecurity #MachineLearning #SecureAI #ModelSupplyChain #ModelLoading #ArbitraryCodeExecution #SoftwareSecurity #CyberSecurity #AIVulnerabilities #ModelHubSecurity #SecureML #AIAttackSurface #IEEEsp #SecurityResearch

1
2
17
909

63% of AI agents deployed in production have critical security flaws.
Most security teams focus on traditional vectors: network perimeter, endpoint protection, access control.
But agents introduce entirely new vulnerabilities:
🎯 𝗣𝗿𝗼𝗺𝗽𝘁 𝗜𝗻𝗷𝗲𝗰𝘁𝗶𝗼𝗻 Malicious inputs that manipulate agent behavior, bypassing intended constraints.
🎯 𝗗𝗮𝘁𝗮 𝗣𝗼𝗶𝘀𝗼𝗻𝗶𝗻𝗴 Corrupted training data that influences decision-making at scale.
🎯 𝗠𝗼𝗱𝗲𝗹 𝗘𝘅𝘁𝗿𝗮𝗰𝘁𝗶𝗼𝗻 Adversaries reverse-engineering your proprietary AI logic through repeated queries.
🎯 𝗔𝘂𝘁𝗵𝗼𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝗕𝘆𝗽𝗮𝘀𝘀 Agents performing actions beyond their intended scope due to unclear boundaries.
🎯 𝗖𝗵𝗮𝗶𝗻-𝗼𝗳-𝗧𝗵𝗼𝘂𝗴𝗵𝘁 𝗟𝗲𝗮𝗸𝗮𝗴𝗲 Sensitive reasoning processes exposed in logs or outputs.
Traditional security frameworks weren't built for these threats.
Nexus was.
Our infrastructure provides agent-specific protections: → Input validation at the semantic level → Behavioral anomaly detection → Fine-grained permission boundaries → Encrypted reasoning paths → Continuous compliance monitoring
Because securing AI agents isn't about adding tools. It's about rethinking infrastructure.
#AIAgents #CybersecurityEducation #AgentSecurity #AIThreats #MachineLearning #MLSecurity #AIInfrastructure #ThreatIntelligence #EnterpriseAI #SecureML




4
3
78

3 Oct 2025
最近在看一个挺有意思的方向——SecureML-FHE,这是一个基于@zama_fhe 的全同态机器学习平台。它解决的是一个很现实的矛盾,很多企业的数据不能出厂,但 AI 的训练和推理又离不开数据。以前大家试过多方安全计算(MPC)、差分隐私(DP),要么速度拖垮体验,要么模型精度不够。
SecureML-FHE 的切入点是全同态加密(FHE):数据加密一次,可以无限次运算。对开发者来说,它更像是“加密即计算”的一整套工具链。
比如,它能支持从数据加密、特征处理到模型训练、推理的全流程;还提供 Python / Rust 两个 SDK,开发者几乎零门槛就能上手。
性能方面,团队给的目标也算务实:在 MNIST、CIFAR-10 这种标准数据集上能跑到 90% 的准确率,推理延迟控制在 500ms 以内。虽然比不上明文推理,但在数据不出域的前提下,这个结果已经很有竞争力。
我觉得更值得注意的是它的社区化路线,开源代码、文档和 demo,全力吸引开发者进来一起打磨。他们的 roadmap 也挺清晰:24年底完成同态算子库,25年初就能跑 MNIST,Q2 出 Python SDK,Q3 优化性能并全面开源。团队背景也靠谱,既有前 Google Cloud 安全组的人,也有 Zama 贡献者和资深 Rust 工程师。
我的理解是 SecureML-FHE 代表了隐私计算的一个新阶段。过去大家更多是学术探索,现在逐渐在 AI 金融、AI 医疗、AIaaS 这些场景里看到落地可能。如果他们的目标能兑现,SecureML-FHE 可能会成为“数据不离场,模型不失真”的第一个真正可用的解决方案。
对于关注隐私计算和 AI 的用户来说,我觉得这是一个值得提前卡位的赛道,甚至可能孕育出新的基础设施级别项目。
@KaitoAI #Yapping #MadewithMoss @MossAI_Official

108
92
14,325
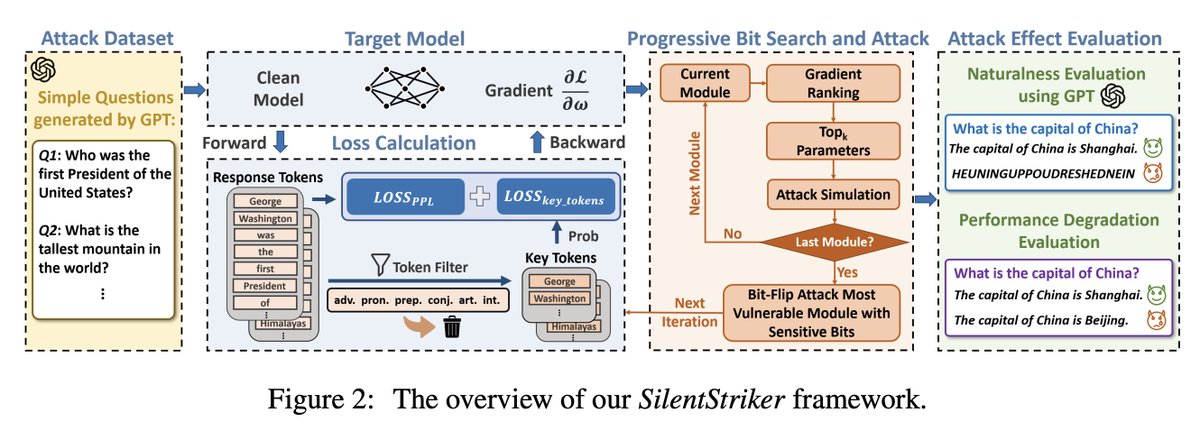
Toward Stealthy Bit-Flip Attacks on Large Language Models - arxiv.org/pdf/2509.17371
While input manipulation attacks (e.g., prompt injection) have been well-studied, Bit-Flip Attacks (BFAs) which exploit hardware vulnerabilities to corrupt model parameters and cause severe performance degradation-have received far less attention.
Existing BFA methods suffer from key limitations: they fail to balance performance degradation and output naturalness, making them prone to discovery. In this paper, we introduce SilentStriker, the first stealthy bit-flip attack against LLMs that effectively degrades task performance while maintaining output naturalness. Our core contribution lies in addressing the challenge of designing effective loss functions for LLMs with variable output length and the vast output space.
Unlike prior approaches that rely on output perplexity for attack loss formulation, which in-evidently degrade the output naturalness, we reformulate the attack objective by leveraging key output tokens as targets for suppression, enabling effective joint optimization of attack effectiveness and stealthiness.
#AISecurity #LLMSecurity #GenAI #ModelSafety #AdversarialML #PromptInjection #DataPoisoning #ModelGovernance #AIRedTeam #SecureML @ZJU_China @Huawei #BitFlip #SilentStriker #BFA
4
7
608
A Practical Guide for Building Robust AI/ML Pipeline Security -linkedin.com/feed/update/urn…
1️⃣ An overview of DevSecOps practices that are applicable to MLSecOps. Lessons learned from DevSecOps can proactively address security challenges in the emerging AI/ML lifecycle.
2️⃣ An overview of MLSecOps practices. Articulate the importance of integrating security within MLOps, resulting in MLSecOps.
3️⃣ Open source centric. Highlight open source tools and frameworks applicable to secure AI/ML applications and workloads, and mitigate associated risks by establishing secure AI/ML processes.
4️⃣ Unique security risks. Identification of unique security challenges in the AI/ML lifecycle and recommendations on addressing these challenges.
Source: openssf.org/ by OpenSSF
#MLSecOps #MLOpsSecurity #AIThreatModeling #SecureML #OpenSSF #AIInfrastructure #MLSecurity #AIModelSecurity #SecurePipelines #DevSecOps #AICompliance #MLGovernance #ModelProvenance #DataSecurity #AISupplyChain #AITrust #LLMSecurity #AIObservability #AIResilience #MLOpsGovernance #MLSecOps #AIsecurity #OpenSourceSecurity #DevSecOps #SupplyChainSecurity #MLOps #OpenSSF

2
7
185

7 May 2023
4/9
🌐 Machine learning is increasingly integrated into all aspects of our lives, from healthcare to transportation. Aleo's zkML Initiative aims to ensure the security and privacy of these applications, laying the foundation for a more trusted future.
#SecureML
1
2
37

29 Jul 2022
Dr. Bo Li is winner of the 2022 #IJCAI #ComputersAndThoughtAward. She is giving an award lecture at @IJCAIconf on her work on #SafetyCriticalAI. @uiuc_aisecure #SafetyCriticalSystems #SafetyCritical #SecureML #MachineLearning #SafeAI #IJCAI2022 #IJCAIawards

ALT Stolz 2-3, location of IJCAI 2022 Award lectures

ALT Large audience at Bo Li’s IJCAI Computers and Thought Award lecture

ALT Computer vision application: STOA Certified Robustness on CIFAR
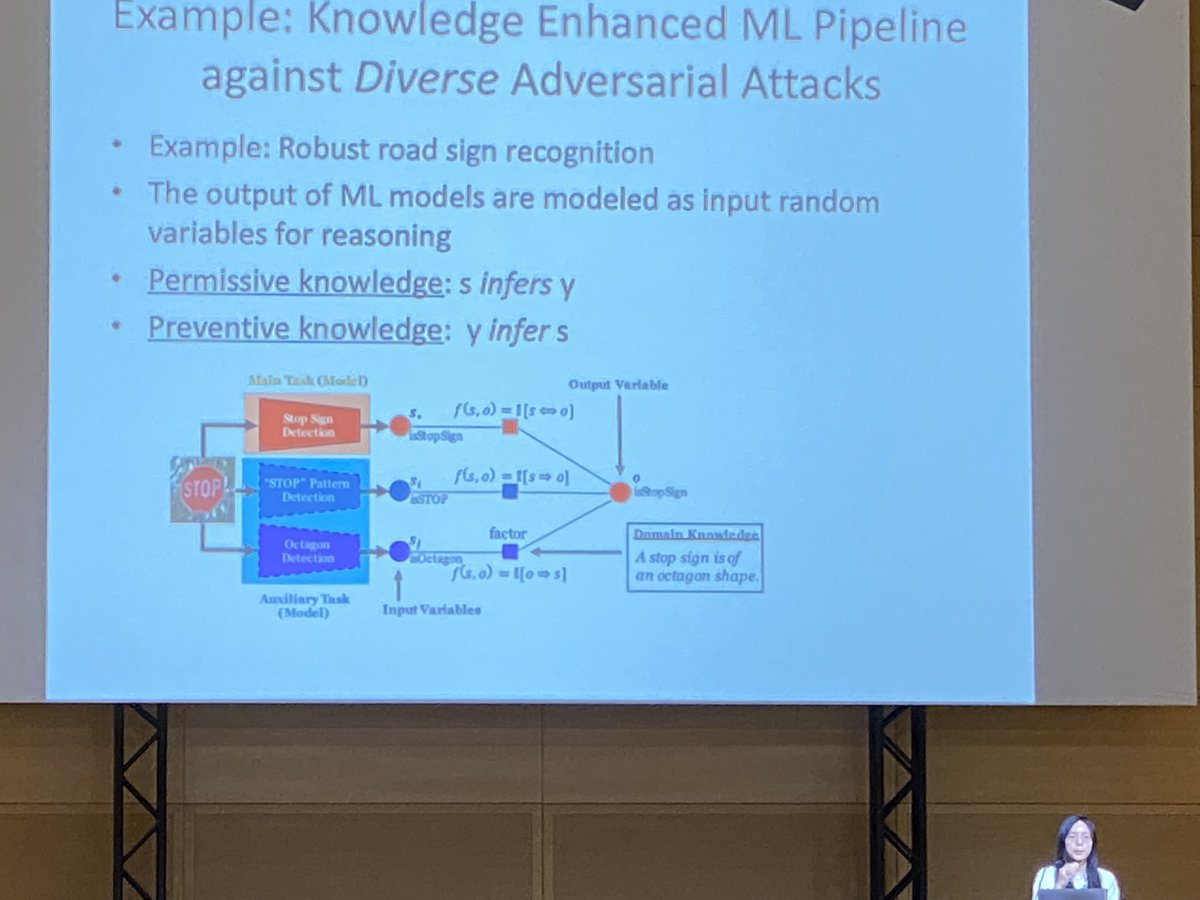
ALT Example: Knowledge Enhanced ML Pipeline against Diverse Adversarial Attacks
29 Jul 2022

Here for the #IJCAI2022 #ComputersAndThought Award Lecture of Bo Li, PI of @uiuc_aisecure, the #SecureLearningLab at @IllinoisCS! Congratulations to Bo on the #IJCAI_CT award! #SecureML #TrustworthyML #SecureAI #SafeAI #IJCAICompThought #IJCAIawards

ALT Photo: IJCAI Computers and Thought Award lecture by Bo Li. Slide title reads “Certified Robustness for a Sensing-Reasoning ML Pipeline”
4
8

29 Jul 2022
Here for the #IJCAI2022 #ComputersAndThought Award Lecture of Bo Li, PI of @uiuc_aisecure, the #SecureLearningLab at @IllinoisCS! Congratulations to Bo on the #IJCAI_CT award! #SecureML #TrustworthyML #SecureAI #SafeAI #IJCAICompThought #IJCAIawards
ALT Photo: IJCAI Computers and Thought Award lecture by Bo Li. Slide title reads “Certified Robustness for a Sensing-Reasoning ML Pipeline”
1
11

19 Feb 2021
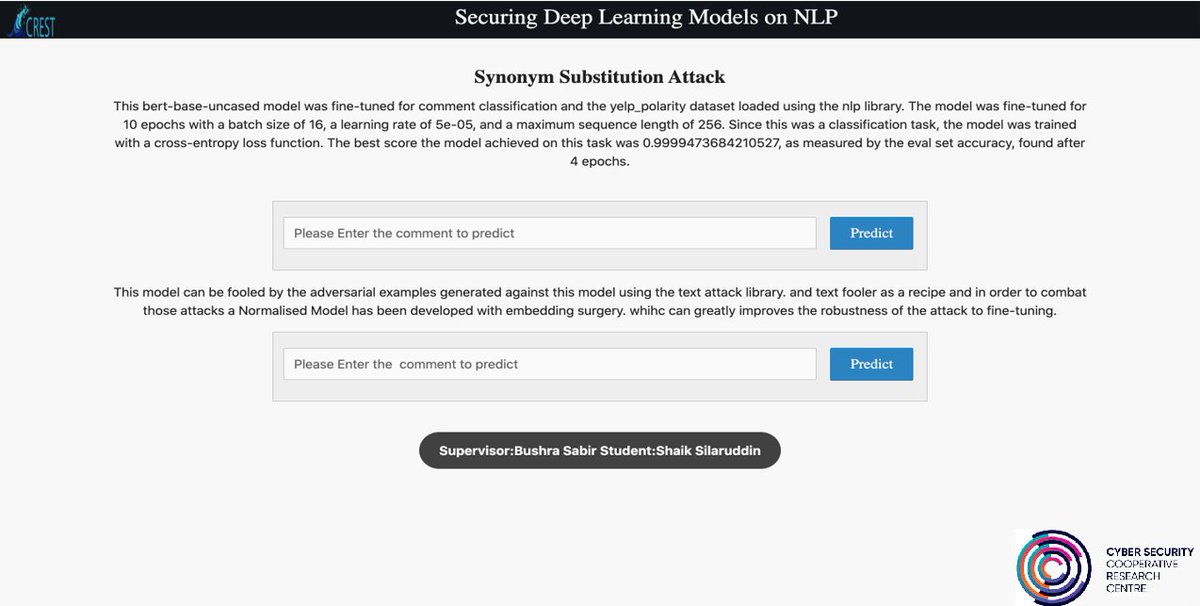
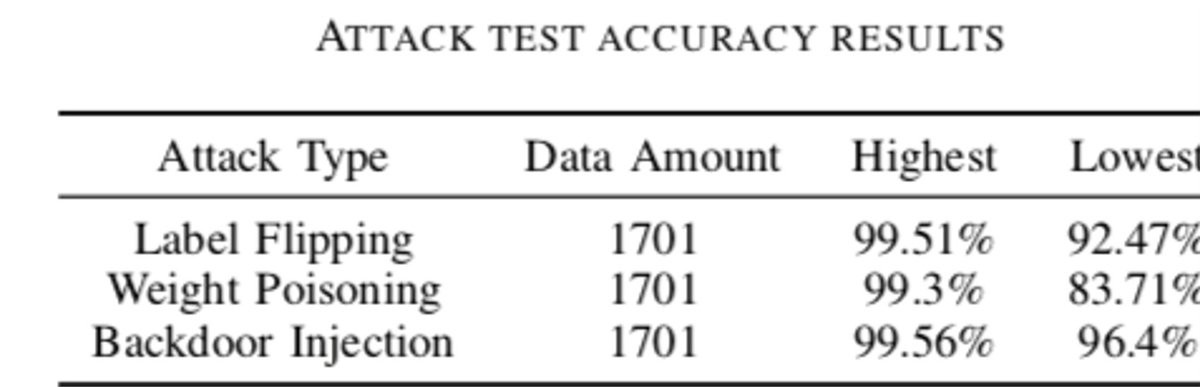
#CRESTSummerProjects2020 it been a journey of 11 weeks, interns have learned the ethics of research, teamwork and hard work and produced a great outcome. #SecureML @SilaruddinS @NiniCui @Kaili group supervised by @alibabar.
2
11
22 Jan 2021
Today summer interns working on #secureML #adversarialattacks project presented their 8th Weeks progress. #CRESTSummerProjects2020 lead by
@alibabar at @crest_uofa supported by @CSCRCoz




3
11

5 Apr 2020
Watching intro to Distributed Databases by @andy_pavlo as I continue to write for the Secure Machine Learning series coming to datasecspace.space blog #data #databases #machinelearning #secureml
1
4
2

9 Dec 2019
@dawnsongtweets’s invited talk mentions the importance of understanding and combatting security and privacy issues in (deployable) ML. This is a topic I have been thinking a lot about recently. Happy to see researchers talking about this. #secureML #WiML2019 #NeurIPS2019

3

20 Jul 2018
The @ProjectPapaya aims at enabling #PrivacyPreservingDataAnalytics, i.e. incorporating #Privacy in #DataAnalytics, #MachineLearning tasks.
This article ⏬looks at existing techniques that can be employed: #anonymization #DifferentialPrivacy #SecureML
analyticsindiamag.com/how-re…
1
1

19 Jun 2018
I had a great time presenting new MPC techniques for Privacy Preserving Machine Learning at the TPMPC workshop (multipartycomputation.com/tp…). Here is video of my talk vc.au.dk/videos/video/6825/ which covers SecureML (ia.cr/2017/396) & ABY3 (ia.cr/2018/403) frameworks.
6
22

7 Jun 2017
[Revised] SecureML: A System for Scalable Privacy-Preserving Machine Learning (Payman Mohassel and Yupeng Zhang) ia.cr/2017/396
1
3
9 May 2017
[New] SecureML: A System for Scalable Privacy-Preserving Machine Learning (Payman Mohassel and Yupeng Zhang) ia.cr/2017/396
3
5

9 May 2017
#ePrint SecureML: A System for Scalable Privacy-Preserving Machine Learning: P Mohassel, Y Zhang ia.cr/2017/396
1
3

14 Nov 2014
My Public PGP key (updated):
BF7E 9C7B 7EA7 FF6B 0DC2
6C43 D6E7 561D 47F9 A4D1
SendTo: SecureML[at]MartinLong[dot]org

1
6