
Jun 10
🧪 Finding cleaning chemicals that leave no residue on silicon substrates means navigating a vast molecular space — and experimentally evaluating every candidate is slow and costly. In a new Matlantis case study, SCREEN Holdings shows how Bayesian optimization paired with universal MLIPs accelerates this screening by 39× versus random sampling.
Residue-free wafer cleaning is critical to modern semiconductor manufacturing. After hydrofluoric acid treatment, the H-terminated Si(100) surface must remain free of adsorbed contaminants — but the chemical space of candidate molecules is enormous.
🔬 The team's approach combines:
- PFP in Matlantis for adsorption energy calculations on H-terminated Si(100)
- Molecular descriptors from RDKit and Force-Field Kernel Mean methods
- Bayesian optimization (via Optuna) to iteratively select promising candidates and refine the ML surrogate model
Each round of calculation feeds back into the next selection, narrowing toward low-adsorption-energy molecules without exhaustive enumeration.
🌱 The 39× screening efficiency gain demonstrates a practical workflow for discovering new wafer-cleaning materials — one that goes beyond what experimental approaches alone can deliver.
Read the full case study: matlantis.com/en/calculation…
#Matlantis #Semiconductors #BayesianOptimization
3
192

May 29
Inverse design in battery materials is in an awkward place.
The forward direction is well-studied: pick a composition, predict energy density. Materials Project, OQMD, and AFLOWLIB give you decent training data for that.
The inverse direction — "find me a composition that hits 300 Wh/kg with >1500 cycles at 4 C-rate" — is much harder, because you need joint distributions over composition, processing, and performance under realistic operating conditions. The public datasets don't have that.
MAT-001 was built with inverse design in mind:
→ Composition features: cathode, anode, electrolyte, separator, crystal structure, 12 dopant species, 6 binder systems → Process features: manufacturing variation per batch, yield, anomaly rate → Performance features: energy density, power density, cycle life, thermal runaway temp, Coulombic efficiency, impedance growth, fast-charge capacity loss → All jointly distributed across 25,000 materials at full scale (2,500 in the free sample)
Sample on Hugging Face: huggingface.co/datasets/xper…
If you're working on Bayesian optimization, generative models, or active learning loops for battery materials, this gives you the joint distribution you've been missing.
#materialsinformatics #inversedesign #bayesianoptimization #activelearning
12

May 27
📢 Tired of benchmarking your optimizer on Hartmann and Branin? Try BoLT ⚡, our new black-box optimization (BBO) benchmark grounded in 20K real LLM experiments instead!
LLMs involve expensive, derivative-free decisions that BBO is built to handle. Yet, most BBO research still validates on synthetic functions that miss the challenges of real LLM tasks. BoLT ⚡ closes this gap so that you can evaluate BBO methods against realistic objectives without needing large-scale compute.
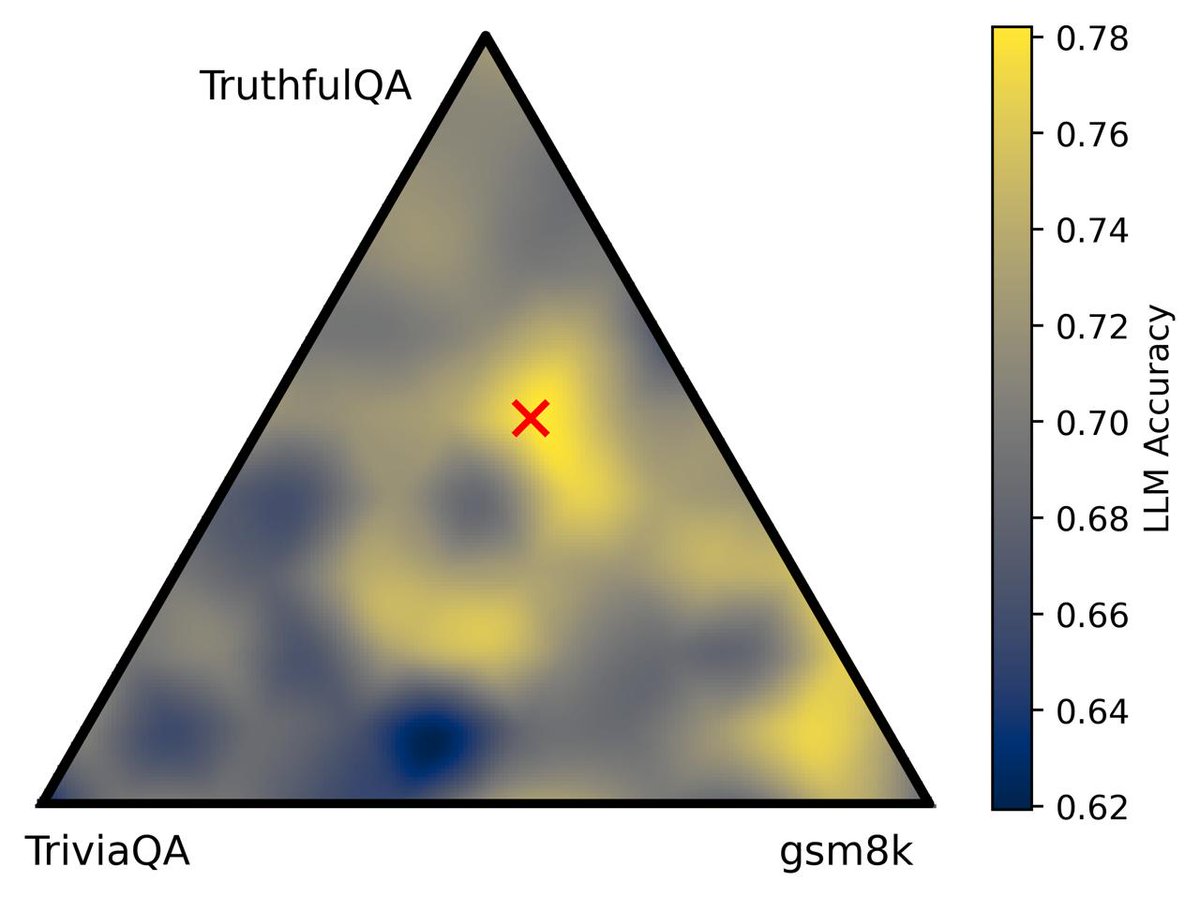
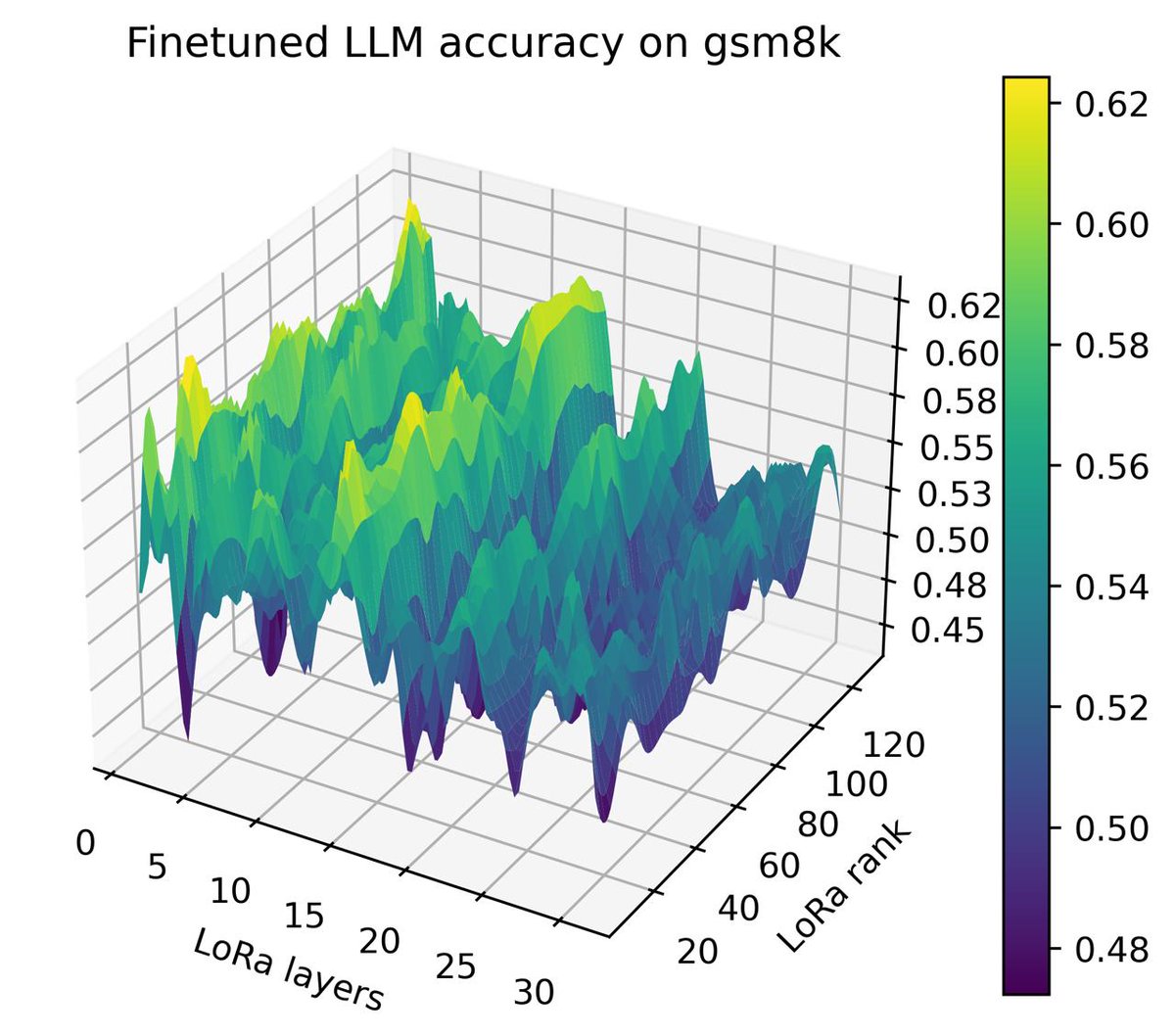
📦 3 task families, 10 problems spanning:
• Hyperparameter optimization (LoRA fine-tuning, mixed variables, multi-fidelity);
• Data mixture optimization (simplex constraints, multi-objective, heteroscedastic noise);
• Prompt optimization (high-dimensional discrete search up to 768 dims).
🚀 Fast, validated emulators replace real LLM calls, returning results in milliseconds. Weights load automatically from HuggingFace on first use.
🔌 Every problem subclasses BoTorch's BaseTestProblem, so your existing optimizer code plugs straight in.
Key findings from benchmarking 15 methods: GP-based BO consistently beats standard HPO baselines; NEHVI matches NSGA-II on multi-objective data mixture optimization with 50× fewer evaluations; trust-region methods are essential for high-dimensional discrete prompt search.
Joint work with Ruth Chew @ruthchewing, Zhiliang Chen @ZhiliangChen94, and Apivich Hemachandra @apivich_h.
Check us out @icmlconf #ICML2026 DEMO Workshop (decision-making-offline2onli…)!
📄 Preprint: arxiv.org/abs/2605.17000
🌐 Project page: chewwt.github.io/bolt
⭐ GitHub: github.com/chewwt/bolt (star to keep up with future updates)
💻 Docs: bolt-bench.readthedocs.io
#BayesianOptimization #BlackboxOptimization #LLMs
1
1
15
779

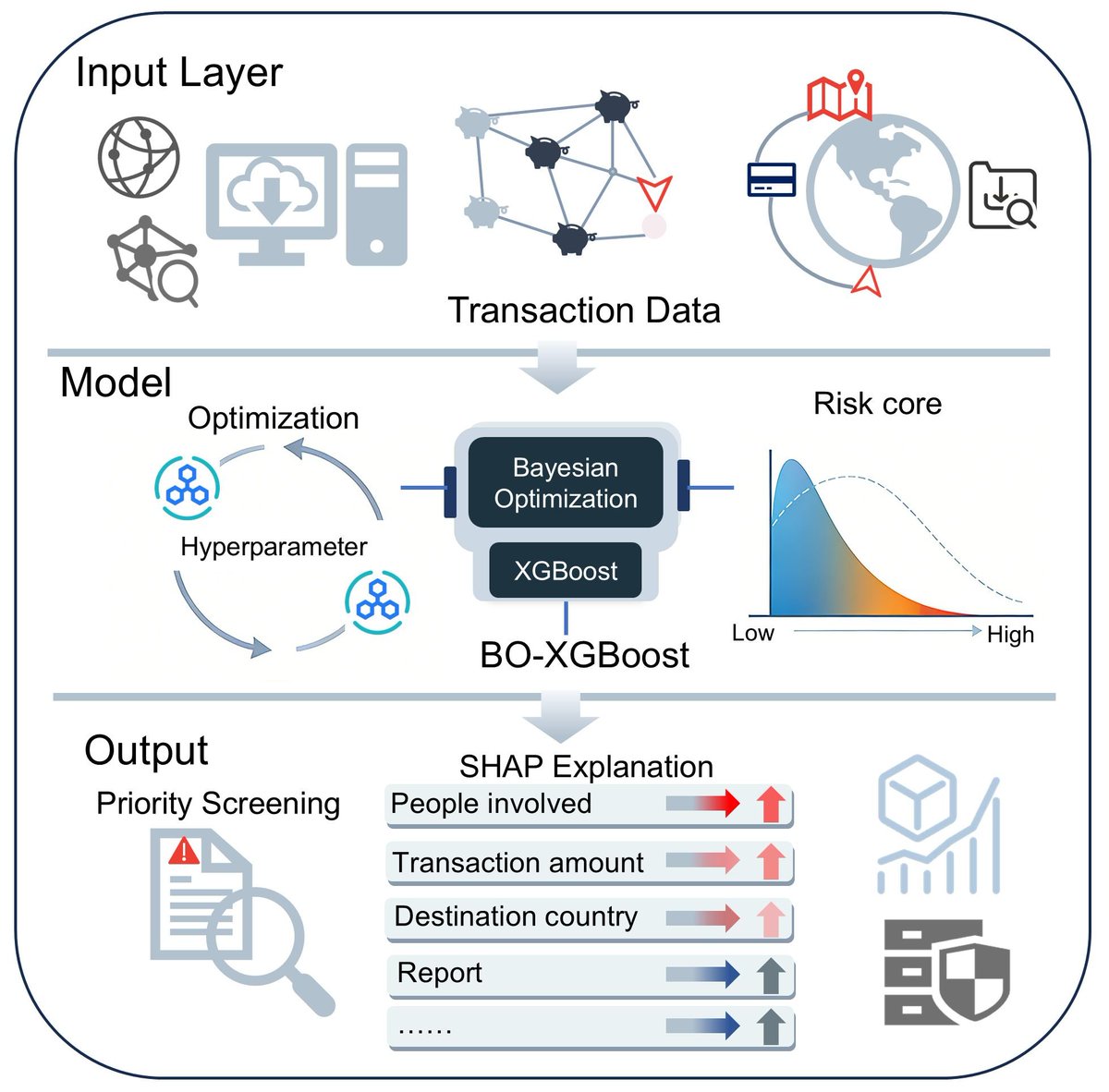
💰 Read #NewPaper "A Bayesian-Optimized XGBoost Approach for Money Laundering Risk Prediction in Financial Transactions" by Zihao Zuo, et al.
See more details at:
doi.org/10.3390/info17040324
#AntiMoneyLaundering #XGBoost #ML #FinTech #BayesianOptimization
@ComSciMath_Mdpi @zh_Zzuo
35

May 2
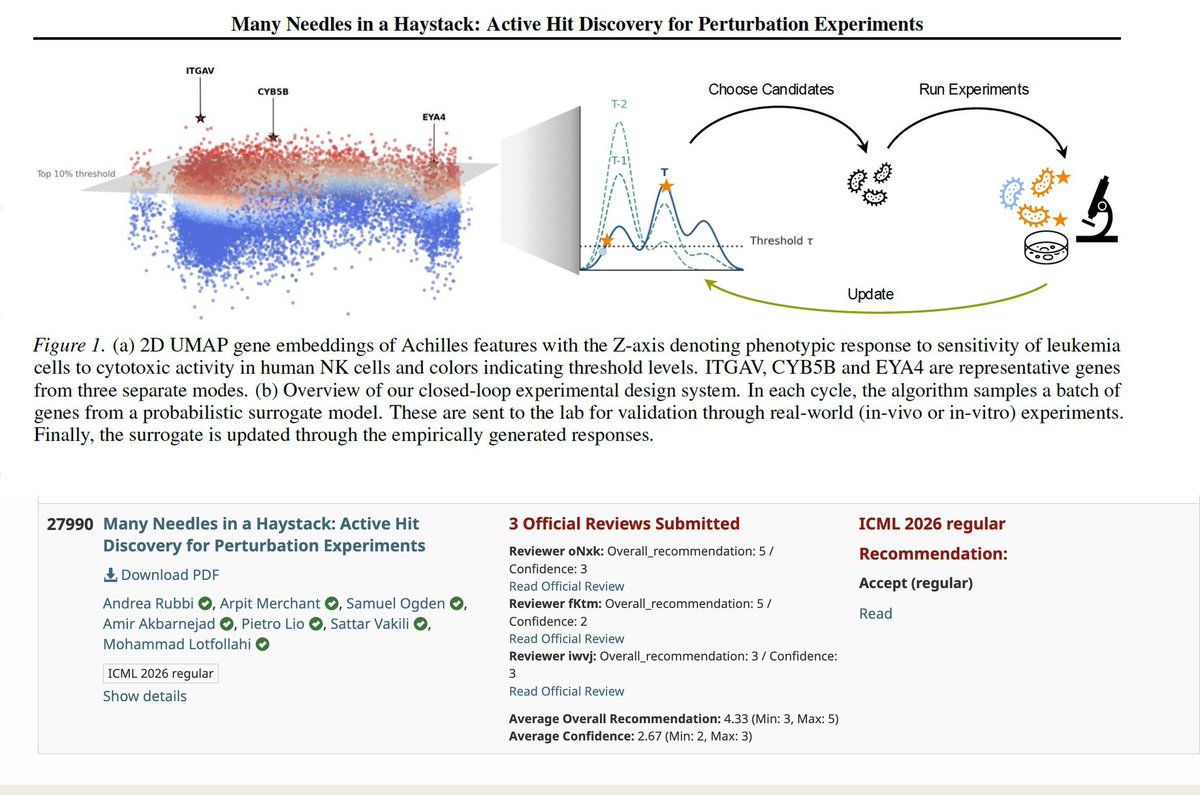
Our paper "Many Needles in a Haystack" has been accepted at ICML 2026 — see you in Seoul! 🇰🇷🧬
CRISPR screens can test thousands of genes, but budgets are tight and hits are rare. Which perturbations should you run next?
We frame this as a lab-in-the-loop design problem: AI proposes a batch → lab runs it → readouts update the model → repeat. Each cycle gets smarter about where hits are hiding.
Our method, Probability-of-Hit, recovers more hits across 5 real immunology screens. More hits per plate, fewer wasted wells.
Great work by Andrea Rubbi, Arpit Merchant, Samuel Ogden, Amir Akbarnejad, with Pietro Lio & Sattar Vakili 🎉
#ICML2026 #ActiveLearning #PerturbSeq #FunctionalGenomics #CRISPRscreen #LabInTheLoop #AI4Science #BayesianOptimization
5
30
222
22,491

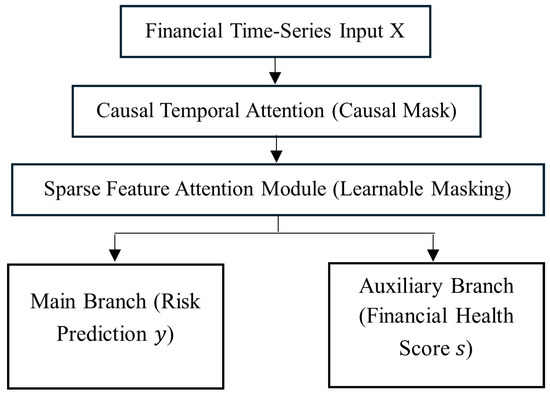
📢 Must-Read in #Forecasting
📖 Research on Dynamic Hyperparameter Optimization Algorithm for University Financial Risk Early Warning Based on Multi-Objective Bayesian Optimization
🔗 brnw.ch/21x26FY
#BayesianOptimization #FinancialRisk #HigherEducation
11
Apr 20
[1/3] 🤔An interesting and practical question:
How can we find the optimal #LLM training data mixture that maximizes a free-form downstream task metric?
For instance, what fine-tuning data mixture should we use to maximize same-demographic user ratings ⭐ across our chatbots?
Our #ICLR2026 work (with @ZhiliangChen94 @greglau Chuan-Sheng Foo) called DUET interleaves #BayesianOptimization and #DataSelection to automatically discover the best data mixture that maximizes any free-form downstream feedback, without manually searching through countless combinations.
📄Paper: arxiv.org/abs/2502.00270
📅Catch us at @iclr_conf 🇧🇷Poster Session 3 Fri Apr 24 10:30AM Pavilion 3 P3-#305.
More below👇.
1
3
14
560
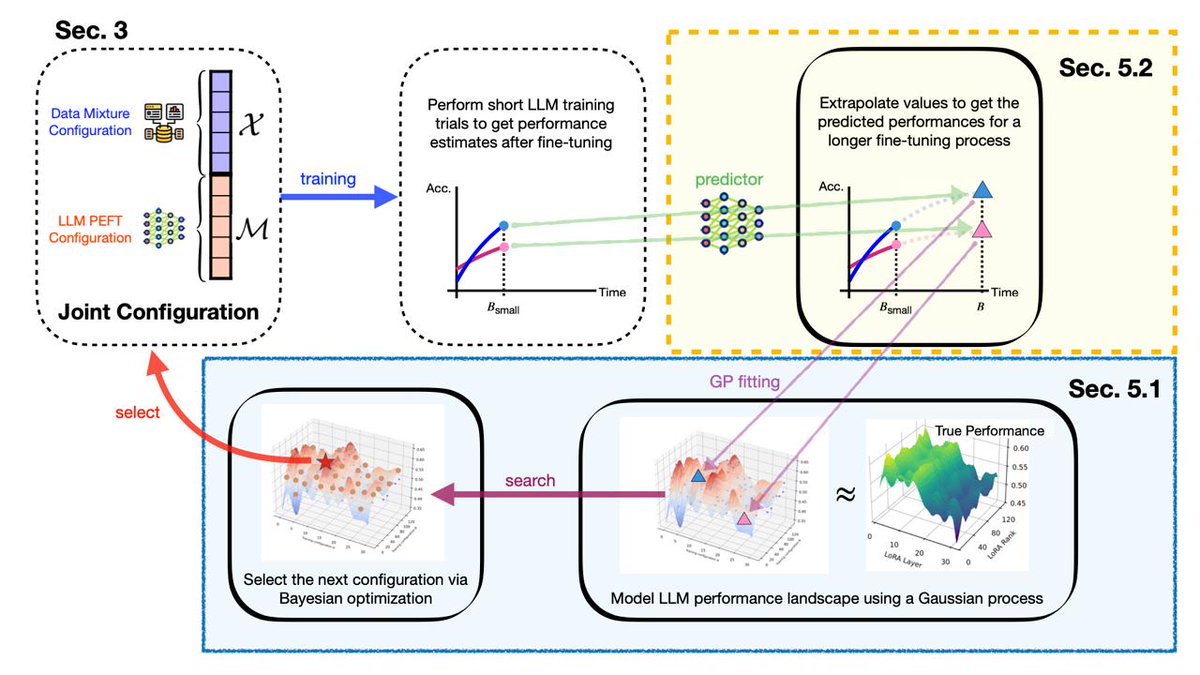
Apr 20
[3/4] Enter JoBS: Joint #BayesianOptimization (BO) with a Scaling-law-inspired predictor.
The trick: Burn a small slice of compute on N full runs → train a neural net predictor that extrapolates final performance at 10,000 steps from just 100!
Now every BO iteration is ~10x cheaper. 🔥
1
1
2
135
Apr 20
[2/4] Most practitioners pick one of the following and hope for the best:
Optimize data with a fixed LoRA config → leaves performance on the table.
Optimize LoRA with a fixed mixture → same story.
Joint optimization is the answer, but each full finetuning run costs $$$, making naive #BayesianOptimization (BO) infeasible.
2
1
2
67

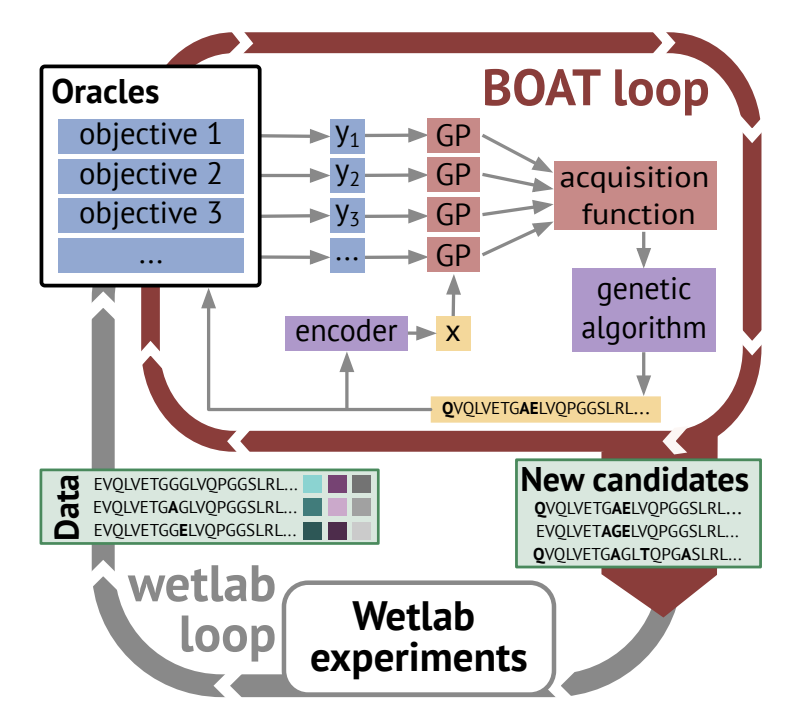
BOAT: Navigating the Sea of In Silico Predictors for Antibody Design via Multi-Objective Bayesian Optimization
1. BOAT is a plug-and-play multi-objective Bayesian optimization (BO) framework that jointly optimizes multiple antibody properties predicted by arbitrary in silico “oracles,” aiming to replace inefficient sequential filtering pipelines with Pareto-aware design.
2. The key engineering idea: uncertainty-aware surrogate modeling (Gaussian processes) proposes which sequences to score next, while a genetic algorithm (GA) is used to optimize acquisition functions directly in discrete sequence space (avoiding invalid continuous edits and awkward projections).
3. BOAT targets realistic lead-optimization settings where objectives can conflict (e.g., affinity vs. developability vs. immunogenicity risk proxies). It supports full-sequence or region-restricted optimization (e.g., specific CDRs), plus practical constraints such as restricting mutable positions, allowed amino-acid dictionaries, and liability filtering (e.g., glycosylation motifs).
4. Method details: sequences are embedded (one-hot, BLOSUM-derived, bag-of-5-grams, or AbLang-2 embeddings), then modeled with a GP using a Tanimoto kernel to better handle high-dimensional sparse-like representations. Multi-objective acquisition uses EHVI (and NEHVI for noisy settings), implemented via BoTorch.
5. Cross-reactive VHH case study: BOAT optimizes CDR1/2/3 (up to 5 mutations per CDR) to improve binding to two related antigens, optionally adding humanness (OASis) and PLM likelihood (ESM-2) as additional objectives. Mutation choices are constrained to a curated per-position amino-acid dictionary grounded in available experimental single-point data.
6. Benchmarking against GA baselines (sum-of-objectives GA and NSGA-II): across 2–4 objectives and multiple CDRs, BOAT variants reach higher hypervolume earlier and end with better hypervolume under the same oracle-call budget (1000). NSGA-II degrades notably as objective count increases, consistent with many-objective optimization issues.
7. When exhaustive enumeration is feasible (smaller constrained spaces), BOAT recovers Pareto fronts close to the “ground-truth” oracle-induced Pareto frontier, including in very large enumerated CDR3 spaces (tens of millions of sequences), highlighting sample-efficient Pareto exploration rather than brute-force scoring.
8. Diversity matters for wet-lab follow-up: batch BO acquisition (qEHVI/qNEHVI) tends to produce higher Shannon-entropy sequence sets while maintaining strong hypervolume, whereas sequential EHVI can be more exploitative (competitive hypervolume but lower diversity). Larger batch sizes increase diversity, with some early hypervolume trade-offs.
9. Practical limits and regimes: (i) NEHVI can become dramatically slower as objectives increase (e.g., 3 objectives taking minutes per BO step vs seconds for 2), (ii) complex structure-based oracles (Boltz-2 ipTM) can break surrogate fidelity with simple encodings—here, semi-random GA search can be competitive, motivating richer structure-aware surrogates/kernels.
10. Comparison to generative multi-objective methods (LaMBO-2) on the 4-4-20 scFv affinity/expression dataset: using the same discriminative head as BOAT’s oracle, BOAT generally achieves higher hypervolume over generated sequences. However, BOAT can exploit predictor artifacts and go out-of-distribution; adding an ESM-2 likelihood objective acts as a “naturalness” regularizer, underscoring that oracle quality and priors critically shape in silico Pareto fronts.
💻Code: github.com/AstraZeneca/boat
📜Paper: arxiv.org/abs/2604.13980
#BayesianOptimization #MultiObjectiveOptimization #AntibodyDesign #ProteinEngineering #MachineLearning #ComputationalBiology #DrugDiscovery #ActiveLearning #GaussianProcesses #ParetoOptimization
2
15
1,132

Apr 14
🤖📍 New #ModellingSeminars session
📖 Precision-Weighted Joint Entropy Search for Bayesian Optimization
🎤 Eduardo César Garrido Merchán
📆 April 16 | 12:30
📍 5th Floor, Rey Francisco 4
#BayesianOptimization #ResearchSeminar
23

TrendToKnow AI: Transfer Learning in Bayesian Optimization for Aircraft Design
👥 Ali Tfaily, Youssef Diouane, Nathalie Bartoli & Michael Kokkolaras
#TransferLearning #BayesianOptimization #AerospaceEngineering #AIResearch
Provided by TrendToKnow AI
🔗 trendtoknow.ai/

13

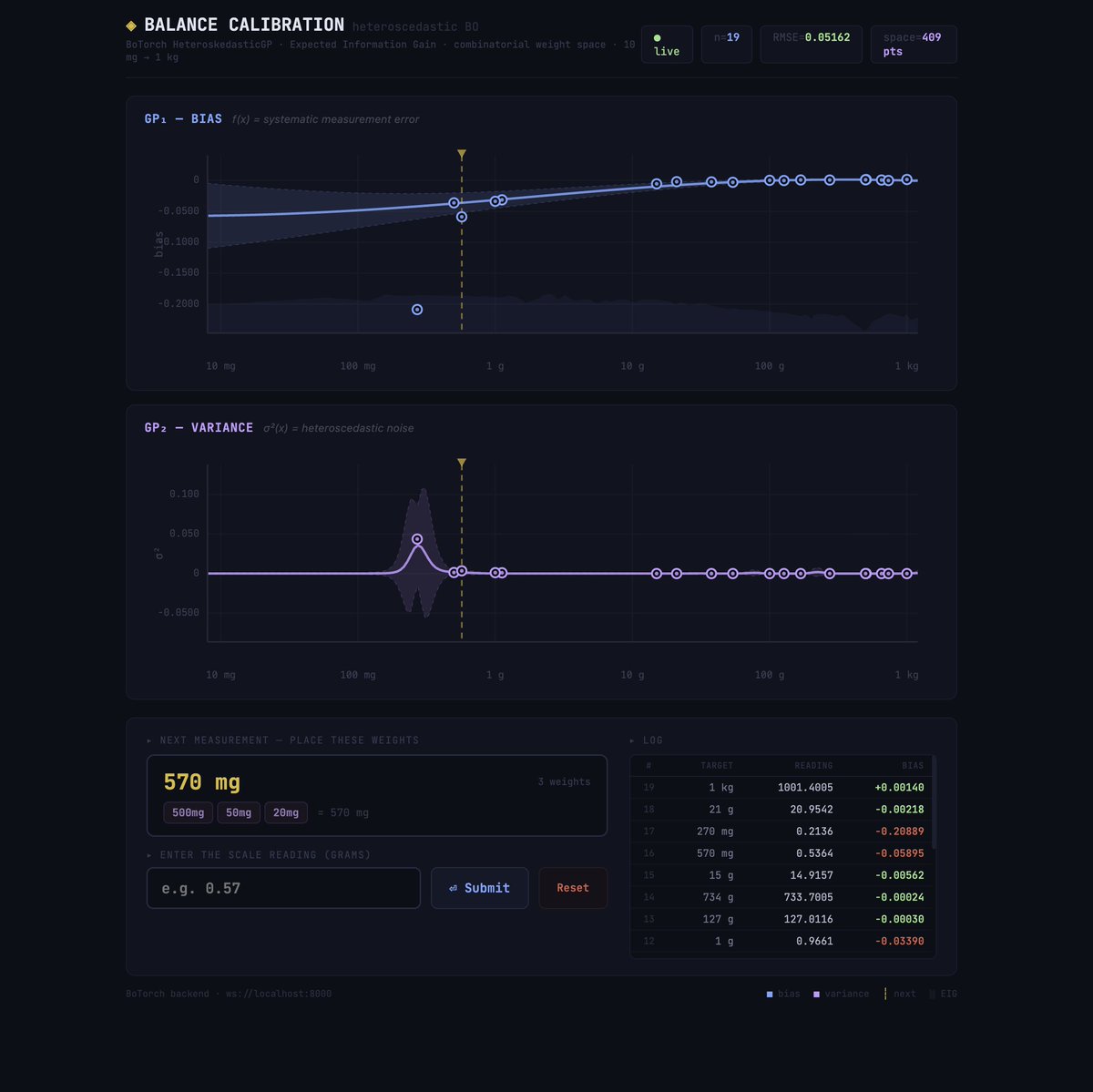
My kitchen scale now has a lower RMSE (0.05162g) than my life decisions.
We used a datacenter to calibrate a $30 scale.
I’m not saying I have a problem… but my flour is now statistically perfect.
github.com/arthurmaffre/scal…
#OverEngineering #BayesianOptimization #BoTorch

28

Mar 26
📢 #highlycited paper
📚 Improving #HardenabilityModeling: A Bayesian Optimization Approach to Tuning Hyperparameters for #NeuralNetworkRegression
🔗 mdpi.com/2076-3417/14/6/2554
👨🔬 by Wendimu Fanta Gemechu et al.
🏫 Silesian University of Technology
#Bayesianoptimization #hyperparametertuning
1
2
25
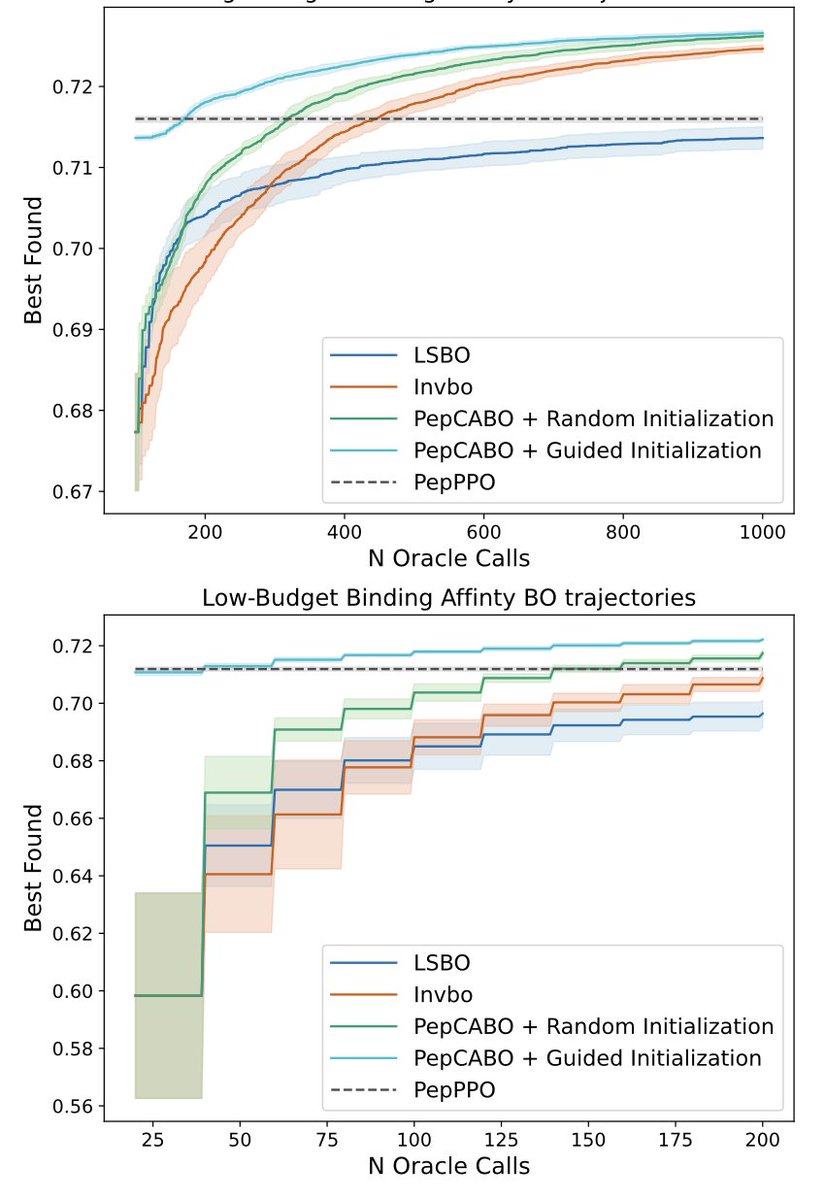
PepCABO: Latent‑space Bayesian Optimization for Peptide‑MHC Binding Using Contrastive Alignment
2. PepCABO introduces a dual‑VAE that jointly learns peptide and allele embeddings, aligning high‑binding peptides to their corresponding MHC groove residues via a multimodal rank‑N contrastive loss.
3. By training a sparse Gaussian process over the joint latent space before any BO runs, the method creates an informative prior that captures cross‑allele structure and guides early exploration.
4. Guided initialization samples a trust region around the allele embedding, yielding batches that already sit in the top 90th percentile of predicted binding, drastically reducing the number of required oracle calls.
5. In silico emulation on 12 held‑out HLA alleles shows PepCABO consistently surpassing vanilla LSBO, InvBO, and a reinforcement‑learning baseline in both low‑ (200 calls) and high‑budget (1,000 calls) regimes.
6. The approach achieves higher area‑under‑best‑so‑far curves and stronger best‑found affinities, demonstrating superior sample efficiency when experimental throughput is limited.
7. Ablation studies confirm each component—contrastive alignment, surrogate pre‑training, and guided init—contributes to performance, suggesting the framework is modular and transferable to other binding tasks.
8. Because the method relies only on pre‑existing data from 143 alleles, it can be deployed in real‑world vaccine design pipelines without requiring expensive initial experiments.
9. The authors also show that the same guided initialization strategy works with actual IC50 measurements, indicating compatibility with wet‑lab workflows.
10. PepCABO exemplifies how biologically informed latent geometry and transfer learning can accelerate peptide design, pointing toward broader applications in protein engineering.
💻Code: github.com/mohsen-g/PepCABO
📜Paper: biorxiv.org/content/10.64898…
#PeptideDesign #MHC #BayesianOptimization #ProteinEngineering #MachineLearning #Immunotherapy #VaccineDesign
3
15
1,146

AI Agent Autonomously Predicts CFPB Enforcement Actions Using BoTorch (Source: GitHub)
An AI agent autonomously built a Bayesian Optimization pipeline using BoTorch to predict CFPB enforcement actions based on consumer complaint data.
#AIAgents #BayesianOptimization #CFPB #Enforcement #BoTorch
🤔 How can AI agents be used to improve regulatory compliance and enforcement?
dailyaiwire.news/article/ai-…
1
1
37

A two-stage "generate-then-optimize" framework for multi-objective molecular design. It decouples generation from batch selection to avoid the architectural entanglement in continuous latent-space optimization.
arxiv.org/abs/2512.17659
#DeNovoDesign #BayesianOptimization
1
2
38
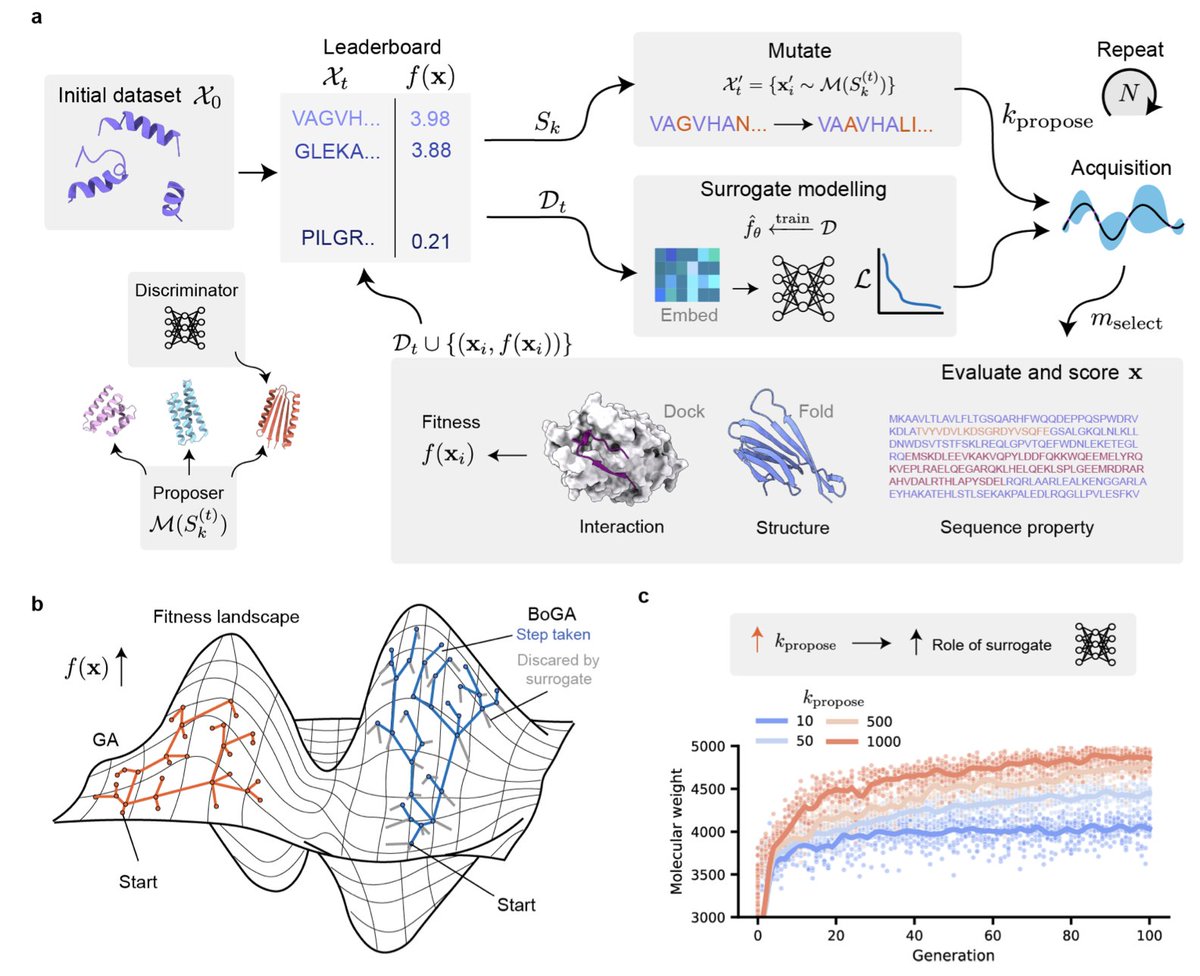
Deep Learning-Guided Evolutionary Optimization for Protein Design
1 BoGA introduces a hybrid approach combining genetic algorithms with Bayesian optimization, where a surrogate model acts as a discriminator to filter candidate sequences before expensive evaluation, dramatically improving optimization efficiency.
2 The key innovation lies in decoupling sequence generation from evaluation: the genetic algorithm proposes diverse candidates through mutation, while a deep learning surrogate model prioritizes which candidates merit costly structure prediction or docking calculations.
3 The framework demonstrates superior performance across multiple tasks including beta-sheet fraction optimization, normalized hydrophobic moment maximization, and AlphaFold-guided secondary structure design, with larger proposal pools consistently yielding better results.
4 In a real-world application, BoGA successfully designed peptide binders targeting pneumolysin, a critical virulence factor of Streptococcus pneumoniae, accelerating discovery of high-confidence binders compared to standard genetic algorithms.
5 The method offers significant advantages over existing approaches like hallucination or diffusion-based methods: no requirement for large-scale pre-training, flexible objective functions without retraining, and seamless integration of advancing structure prediction tools.
6 BoGA is implemented within the modular BoPep suite, supporting interchangeable embeddings, surrogate architectures, acquisition functions, and mutation operators, making it a generalizable strategy for diverse protein design objectives.
📜Paper: arxiv.org/abs/2603.02753
#ProteinDesign #BayesianOptimization #GeneticAlgorithm #DeepLearning #ComputationalBiology #PeptideBinders #Pneumolysin #Bioinformatics #AIforScience
19
120
5,978
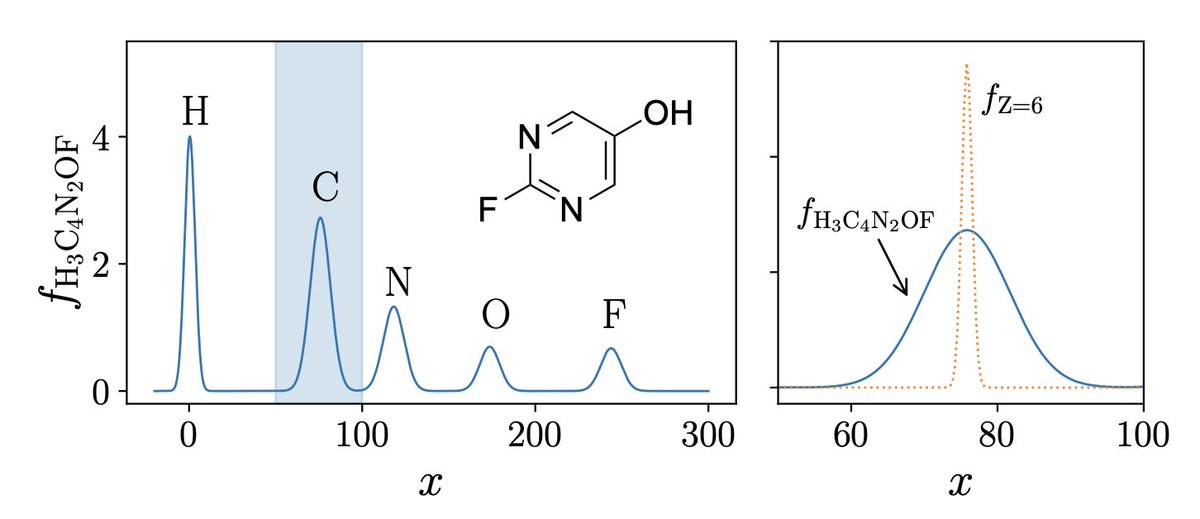
Bayesian Optimization in Chemical Compound Sub-spaces Using Low-dimensional Molecular Descriptors
1) This work presents a data-efficient Bayesian optimization framework that can identify optimal molecular structures with fewer than 2,000 training points in a chemical sub-space containing over 133,000 molecules.
2) The key innovation is a reliable inverse mapping scheme that translates optimized points in descriptor space back into chemically valid molecular structures, bridging the gap between continuous optimization and discrete molecular design.
3) The framework employs low-dimensional, physics-informed molecular descriptors that enable accurate Gaussian Process Regression even with limited training data, addressing the curse of dimensionality that plagues traditional molecular optimization.
4) For entropy optimization, the approach achieves a 100% success rate while requiring fewer than 1,000 molecular evaluations in more than 80% of test cases on the QM9 benchmark dataset.
5) For zero-point vibrational energy (ZPVE), the success rate exceeds 80% for molecules containing more than two heavy atoms, demonstrating robust performance across different molecular properties.
6) The inverse mapping algorithm predicts chemical formulas from descriptor vectors by matching predicted stoichiometry and shape characteristics against molecular databases, with a fallback penalty for chemically implausible suggestions.
7) The method outperforms conventional generative approaches that typically require large datasets, making it particularly suitable for data-scarce settings in molecular discovery.
8) The descriptors combine Coulomb matrix eigenvalues with inner products of atomic reference probability densities, capturing both global molecular shape and local atomic environment information.
📜Paper: arxiv.org/abs/2603.02605
#BayesianOptimization #MolecularDesign #InverseDesign #GaussianProcess #QM9 #ChemicalSpace #LowDimensionalDescriptors #MolecularOptimization #ComputationalChemistry #MachineLearning
2
12
1,309

開発サイクルのボトルネックだった待ち時間が解消され、より高速なカーネル開発が可能になります。
Authors: Ethan Che, Oguz Ulgen, Maximilian Balandat, Jongsok Choi, Jason Ansel (Meta)
#PyTorch #Helion #MachineLearning #BayesianOptimization #OpenSourceAI #Performance
16