Our latest preprint list is now up on FocalPlane. This week, bioimage analysis takes centre stage!
focalplane.biologists.com/20…
#microscopy #bioimageanalysis #preprints
1
5
633

Apr 26
Read my latest #research on #bioimageanalysis, a Correspondence article published with @SpringerNature in @naturemethods: rdcu.be/feOiw
@GloBIAS_ @IMCF_Vinicna @VSCHT @science_charles @CharlesUniPRG
doi.org/10.1038/s41592-026-0…
1
3
42

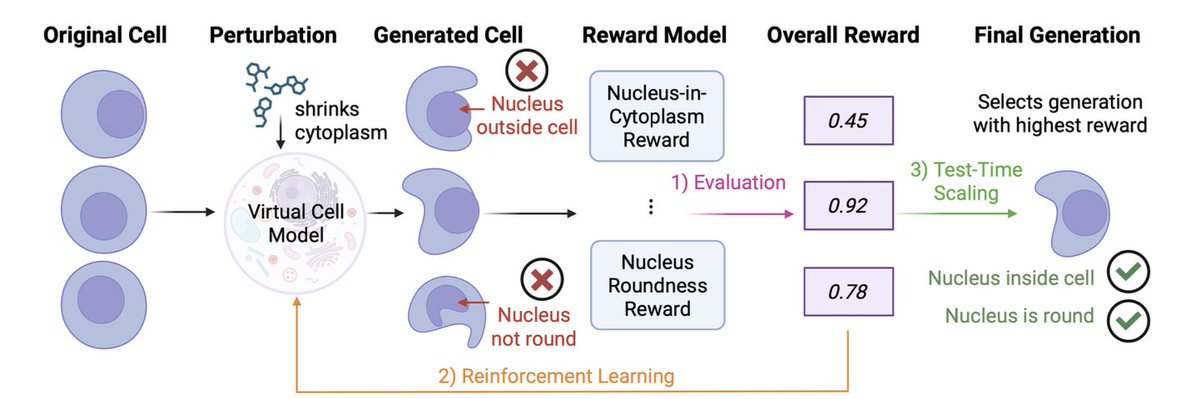
CellFluxRL: Biologically-Constrained Virtual Cell Modeling via Reinforcement Learning
1. CellFluxRL addresses a practical failure mode in image-based “virtual cell” generators: samples can look realistic yet violate basic biology (e.g., nuclei appearing outside cytoplasm), limiting downstream use in drug discovery workflows.
2. The core idea is RL post-training of a pretrained perturbation model (CellFlux, a flow-matching approach) using biologically meaningful, mostly non-differentiable evaluators as reward functions—explicitly aligning generation with physical/biological constraints rather than only pixel-level objectives.
3. The paper designs 7 rewards in 3 categories: biological function (mode-of-action consistency), structural validity (nucleus-in-cytoplasm containment; nuclear roundness), and morphology statistics (nucleus/cytoplasm size and counts), combined as a weighted sum with a KL constraint to stay close to the pretrained model and reduce reward hacking.
4. Biological function reward uses a pretrained MoA classifier: reward is the predicted probability of the ground-truth MoA for the applied perturbation, turning “does this look like the right drug class?” into a trainable alignment signal.
5. Structural rewards explicitly enforce cross-channel spatial consistency via segmentation (Cellpose): nucleus-in-cytoplasm penalizes spatial incoherence across nucleus/cytoplasm channels, while a roundness reward matches MoA-conditioned nuclear shape distributions (mean/variance per MoA).
6. Morphology-statistic rewards match MoA-conditioned population statistics: maximum nucleus size, maximum cytoplasm size, nucleus count, and cytoplasm count are scored by normalized deviation from real-image distributions, encouraging correct scale and density rather than only local texture.
7. Optimization uses an online RL method in the DiffusionNFT style adapted to source-to-target flow matching: generate groups of rollouts per (control image x0, perturbation c), normalize rewards within the group into an “optimality probability,” then apply contrastive updates that increase likelihood of high-reward samples and decrease likelihood of low-reward ones.
8. Results on BBBC021 (98K three-channel 96×96 images; 26 perturbations; 12 MoAs) show consistent improvements over CellFlux and prior baselines (PhenDiff, IMPA) across all reward metrics; MoA reward increases (0.26 to 0.34), nucleus containment improves (0.88 to 0.96), and the combined overall reward flips from negative to positive after RL plus selection.
9. The same reward suite enables test-time scaling: best-of-N sampling selects the highest-reward candidate, yielding monotonic gains as N increases; with N=4, MoA reward rises further (0.34 to 0.56) and overall reward improves substantially, illustrating a compute-quality tradeoff at inference.
10. Ablations show single-reward RL improves the targeted metric but transfers poorly; the combined multi-reward objective yields balanced improvements across biological, structural, and morphological criteria. Sensitivity analysis on the KL weight indicates a tradeoff between allowing larger model shifts (better structure/morphology) vs staying closer to the base model (slightly better biological-function reward).
📜Paper: arxiv.org/abs/2603.21743
#ComputationalBiology #BioimageAnalysis #GenerativeModels #ReinforcementLearning #FlowMatching #VirtualCells #DrugDiscovery #Microscopy #MLforScience
3
8
1,021

Mar 25
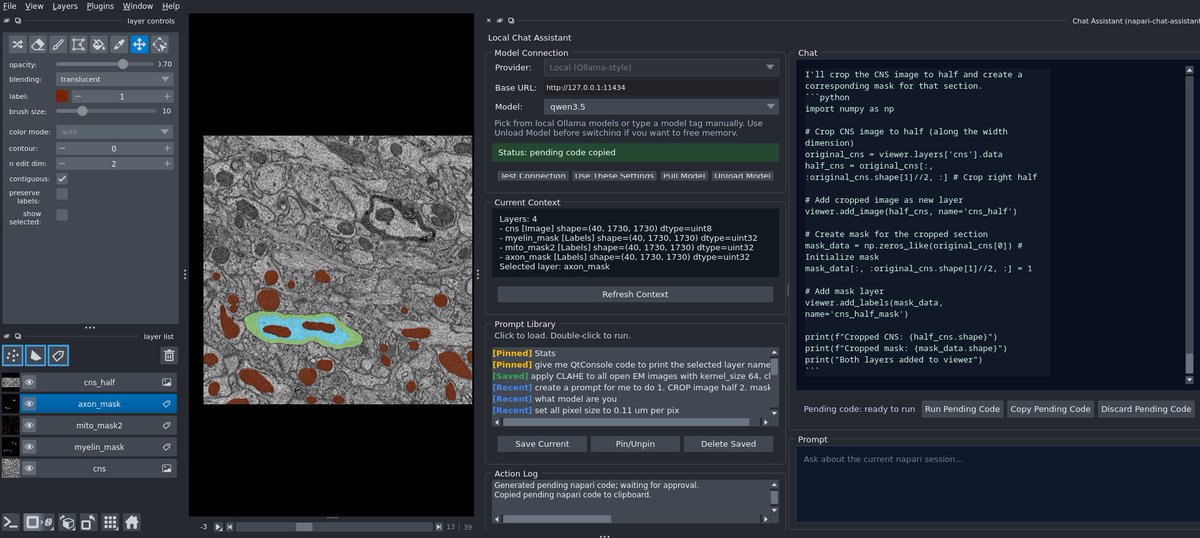
Built a local napari assistant using qwen3.5 Ollama.
Session-aware
Runs image tools
Generates napari code
No API keys
Repo:
github.com/wulinteousa2-hash…
#BioimageAnalysis #LocalAI
4
146

1/ 🚀 Excited to release: napari-mcp - agentic control of napari from any MCP-capable AI assistant!
Use it for interactive image processing, analysis, and visualisation! Really cool project from @ilan_theodoro in my team!
#napari #bioimageanalysis #MCP @biohub
2
18
68
6,741

I’m excited to speak at the Advanced Tissue Imaging & Image Analysis Workshop at Kyoto University (Apr 13–15, 2026) on AI-powered image analysis for spatial biology. Fantastic lineup of speakers and hands-on training across multiplex imaging, 3D tissue imaging, and bioimage analysis. If you know students or postdocs working on spatial omics, imaging, or AI, please share.
Details & registration:
ccii.med.kyoto-u.ac.jp/en/ev…
#SpatialBiology #BioimageAnalysis #MultiplexImaging #Microscopy

5
28
2,763
10/ 🔬🧪 Try it today! pip install napari-chatgpt — GitHub: github.com/royerlab/napari-c… — Paper: doi.org/10.1038/s41592-024-0… #Omega #napari #AI #BioImageAnalysis
1
2
223

3 Nov 2025
📢 Applications are open!
Join us June 4–18, 2026 @HHMIJanelia for lectures, exercises, and project work applying #DeepLearning to #Microscopy image analysis. #BioimageAnalysis
🛏️ No registration fee; meals & lodging covered
➡️ Learn more and apply by Jan 15 @ janelia.news/DLBC26
@HHMINews @ISCB

8
17
3,097

29 Oct 2025
Happy to contribute to the #bioimageanalysis of α5β1 integrin endocytosis using @3i_inc LLSM, now in @NatureComms
nature.com/articles/s41467-0…
@LeconteLudovic, M. Shafaq-Zadah, C. Wunder, J. Salamero, Johannes team @institut_curie @Inria_Rennes @Fr_BioImaging @Inserm @CNRS @psl_univ
2
4
836

22 Aug 2025
Check out the latest research in bioimage analysis in our new preprint list!
Let us know if you’ve been reading a preprint that we’ve missed.
focalplane.biologists.com/20…
#BioimageAnalysis
5
16
851

🔥 NEW SESSION ALERT!
Hot Topics in Bioimage Analysis & AI is coming to #SPAOM 2025! 🤖🔬
Cutting-edge tools, deep learning, explainable AI & more — all in one session. 💥
Don’t miss this! 🚀
#AI #BioimageAnalysis #Microscopy #DeepLearning #ImagingScience #HotTopics

6
12
801

14 Aug 2025
Would your #cellbio research benefit from you attending a #Microscopy or #BioimageAnalysis training course? For grants of up to £1,000, check out our Microscopy Training Grants with @focalplane_jcs.
Next deadline: 5 September 2025
biologists.com/grants/jcs-fo…

ALT Microscopy Training Grants Supporting microscopy training for early-career researchers in cell biology Apply for a grant of up to £1,000 Cartoon of a person looking down a microscope, which is next to a computer Journal of Cell Science logo and FocalPlane logo
4
4
867
19 Jul 2025
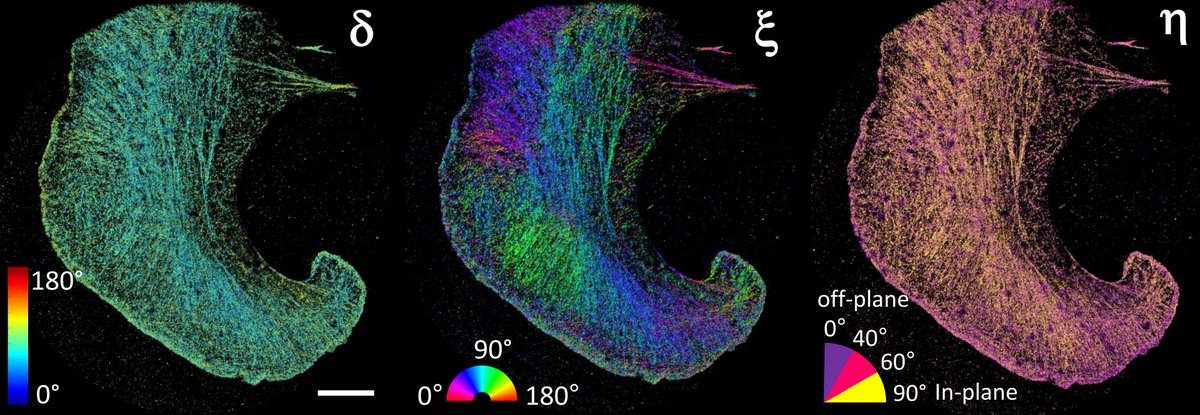
Happy to share our work on polarized super-res imaging: 4polar3D in bioRxiv!
A great collaboration with S. Brasselet, @charithsenthil, M. Sison, @agvesga, J. Rey-Barroso, V. Curcio, @lalemanc1, M. Alonso, @RenaudPoincloux & M. Mavrakis
biorxiv.org/content/10.1101/…
#bioimageanalysis
18 Jul 2025

4polar3D : Single molecule 3D orientation imaging of dense actin networks using ratiometric polarization splitting biorxiv.org/content/10.1101/… #biorxiv_bioeng
2
4
258

14 Jul 2025
First day of #bobiac2025. Six days of intensive Python based #BioImageAnalysis. Intro by @FedeGasparoli - "This will be a long week, but it will change your life".
iac.hms.harvard.edu/bobiac/2…

4
26
1,273
9 Jun 2025
New ‘How to’ post on FocalPlane 🔬💻
Lea Kabjesz shares a step-by-step guide to get you started annotating 2D and 3D images in Cellpose, including video tutorials.
focalplane.biologists.com/20…
#bioimageanalysis #cellpose #imaging #HowTo
18
58
3,653

6 Jun 2025
It never ceases to amaze me how much information we can get just by looking at the gradients in super-resolution #BioImageAnalysis #AI #GenAI Kudos Ivo F. Sbalzarini and the group! @MOSAICgroup1 @mpicbg @HZDR_Dresden @CASUSscience @helmholtz_ai onlinelibrary.wiley.com/doi/…
1
3
168

1 Jun 2025
One week to apply for Microscopy Training Grant from @J_Cell_Sci @focalplane_jcs if you would like to attend a #microscopy or #bioimageanalysis training course in the next 6 months but don’t have funding.
Next deadline: 6 June 2025
biologists.com/grants/jcs-fo…

ALT Microscopy Training Grants Application dates: 6 June 2025 5 September 2025 7 November 2025
9
26
2,361

💻 3 days, 4 nodes, 1 powerful open-source tool!
We wrapped up the National QuPath Course with live sessions from GIMM Lisbon hands-on help at CNC, RISE-Health UBI & i3S. Big thanks to all teams & participants! 🎉 #QuPath
#BioimageAnalysis
#OpenSource
#PPBI
#Teamwork


3
9
442

21 May 2025
Are you looking to advance your bioimage analysis skills? Then don't miss the deadline for #EMBOBioImage 🔬✨
📩 Apply by 4 June
➡️ s.embl.org/bia25-01-x
🗓️ 14 – 19 September
📍 EMBL Heidelberg and Virtual
In this advanced course you'll learn cutting-edge concepts and tools for quantitative image analysis. You'll get a strong understanding of theoretical algorithm advancements and the practical skills needed to apply them effectively.
#EMBLEvents #bioimageanalysis #spatialstatistics #artificialintelligence #computervision

16
39
3,586
11 May 2025
If you would like to attend a #microscopy or #bioimageanalysis training course in the next 6 months but don’t have funding, check out our Microscopy Training Grant from @J_Cell_Sci @focalplane_jcs. Next deadline: 6 June 2025
biologists.com/grants/jcs-fo…

ALT Microscopy Training Grants Application dates: 6 June 2025 5 September 2025 7 November 2025
20
27
3,092