
Feb 22
🤯 Seedream 2.0 just cooked pure simulation theory gold:
Two badass fighters throwing down on a rainy neon Shanghai rooftop… → they violently glitch and disintegrate in bright purple code particles → camera dramatically zooms out…
It was ALL just a simulation running on planet Earth — controlled by a hacker at his desk.
"地球模拟第7层 / Earth Simulation Layer 7"
Mind officially blown 😱
Full prompt 👇
#Seedream2 #AIArt #SimulationTheory #Cyberpunk #GlitchArt #ByteDanceAI
2
3
5
246

Feb 20
Ever wondered what a real Cat Sports Festival looks like? Powered by Seedance 2.0 AI – cinematic multi-shot, perfect motion, synced audio! 🐈⬛💨 From epic jumps to hilarious fails. This is the future of cat content! Watch now 👇
#Seedance2_0 #AIgenerated #CatSports #FunnyAnimals #ByteDanceAI
1
5
916

Feb 11
China’s ByteDance is reportedly working on its own artificial intelligence chip and is in discussions with Samsung Electronics to manufacture it, aiming to secure advanced processor supply amid global AI demand. The move marks a strategic push into AI infrastructure for the TikTok parent company.
#ByteDanceAI #AIDevelopment #GlobalAI #PakistanTV #PakistanTvglobal

108

#Seedance #ByteDanceAI #AIVideo #GenerativeAI #AIFilmmaking #ReadyPlayerOne #Metaverse #TechPhilosophy #FutureOfWork
#AIEthics #字节跳动 #AI视频 #人工智能
I tried out Seedance and was blown away by how a single image can generate content with more cinematic quality and human touch. Beyond the massive leap in quality compared to previous models, what's truly impressive about Seedance is ByteDance's willingness to disrupt itself—a clear sign this team had strong product sense from day one.
Facing AI itself, as potentially the biggest party to be affected and eroded, they don't fear AI. Instead, they let AI generate better, faster, cheaper content to compete against their vast existing library of human-created content within their own ecosystem. They stand as a god, overlooking everything in this community. The so-called algorithmic recommendation mechanism is merely another plaything in the system they've built as architects.
Ready Player One and Oasis taught us one thing: you can enjoy the fun of playing the game, but the best approach is to become the one who makes the games, not just someone who plays other people's games.
体验了一把seedance一张图片就能生成更具电影感和人味的时候除了觉得它和之前模型相比效果大幅提升以外。seedance模型的牛逼之处是字节愿意自己革自己的命,显示了一开始这个团队就积累的产品sence。面对ai本身,作为可能最大受影响和被侵蚀的一方,不畏惧ai 让ai生成的更好的更快的制作成本更低的内容,和现在已经储备的大量真人内容在它的系统里赛马厮杀。它把作为一个上帝,在俯瞰这个社区里的所有东西。所谓的算法推荐机制不过也是它作为它体系里搭建者play的一环,头号玩家和绿洲告诉我们一个道理,可以体验游戏的乐趣本身,但最好的方法是,你要成为那个做游戏的人,而不是玩别人游戏的人。
1
2
235

Jan 7
Digitalization can solve at least half of grid operations and maintenance. What remains is a human problem — and a robotics problem. But training people, or building robots that truly understand power systems, is not about using more tokens. It’s about making correct decisions with fewer tokens. ⸻ 电网数字化可以解决至少一半的运维问题, 剩下的才是人的问题,也是机器人的问题。 但无论是培养人,还是创造真正“懂电力”的机器人, 关键都不是更多的 token, 而是在 更少 token 的情况下,仍然做出正确判断。 x.com/yuanjuangrace/status/2… x.com/yuanjuangrace/status/2… x.com/yuanjuangrace/status/2… x.com/yuanjuangrace/status/2… x.com/yuanjuangrace/status/1…
@elonmusk
@grok
@xai
@sama
@demishassabis
@JeffDean
@sundarpichai
@ilyasut
@timnitGebru
@GaryMarcus
@drfeifei
@karpathy
@ylecun
@geoffreyhinton
@percyliang
@goodfellow_ian
@jimmyba
@rowancheung
@kirkdborne
@ronald_vanloon
@antgrasso
@dair_ai
、@jimmydirisinger、@blakelem、
@liangwenfeng
#AIGovernance、#ResponsibleAI、#MultiAgentAI、#AIEthics、#AgenticAI、#DeepMind、#GeminiAI、#OpenAI、#xAI、#ByteDanceAI、#Doubao、#StanfordAI、#AIAgents、#AISafety、#AIAlignment

1
180

7 Dec 2025
Ever wondered how top designers create studio-grade posters in minutes instead of hours?
I just tried Dreamina, the new AI creative platform from ByteDance, and the speed is unreal.
You can blend up to six images, switch styles, fix tiny text, and edit specific areas without breaking the whole layout.
Plus, everything exports in crisp 4K — perfect for business visuals, product shots, and pro-level brand assets.
If you create for clients, e-commerce, or content, this tool cuts your workflow time by at least 10x.
Check out more: tryit.cc/FN2kR
#Dreamina #AICreator #AItools #DesignTools #CapCutAI #ByteDanceAI
16
3
26
14,037

24 Oct 2025
I know we have a lot of news, but we still have a surprise for you!🤭
🚀 Seedance v1 Pro Fast — by ByteDance, exclusively on WaveSpeedAI!! 🥳🥳🥳
Why does it look so good?
✦ 30-60% faster inference, major cost savings.⚡️
✦ Unified Text-to-Video Image-to-Video model.🎥
✦ Native multi-shot storytelling professional camera movement control.🧩
✦ Rich style range: photorealism, cyberpunk, illustration—your imagination, realized.🎬
🎬 Text-to-Video: (wavespeed.ai/models/bytedanc…)
🖼️ Image-to-Video: (wavespeed.ai/models/bytedanc…)
#Seedance #ByteDanceAI #WaveSpeedAI #AIvideo #TextToVideo #ImageToVideo #CinematicAI
1
2
24
1,837

25 Sep 2025
4/12: ByteDance's Dolphin Doc Parser ⤵️
ByteDance's Dolphin drops as the hottest open-source doc parser, released yesterday but exploding today on GitHub.
This ACL 2025 paper-backed tool uses heterogeneous anchor prompting for multi-page PDFs to JSON/Markdown, outpacing OCR with parallel VLMs for layouts, tables, and handwriting. Handles real-time demos that shred Adobe's edge.
Insight: In an RAG-obsessed world, Dolphin's 2x speed on unstructured data unlocks automated workflows for research, legal, and finance, slashing manual ETL by 70%.
The decentralized vibe? Fully reproducible, no vendor lock-in. Clone the repo and parse your backlog; this is the quiet revolution for data teams.
#DolphinParser #ByteDanceAI
1
1
3
99


18 Sep 2025
Seedream4.0 didn’t just raise the bar… it YEETED Nano Banana out of the bar. If Gemini can’t match this balance of raw power usability, it’s game over.
⚡Check it here before the hype explodes:
🔗 seed.bytedance.com/en/seedre…
#Seedream4 #ByteDanceAI #AIBreakthrough #FutureOfAI
2
1
4
103

23 Aug 2025
🔥 ByteDance releases Seed-OSS-36B: Free AI that reads 1,000 pages at once!
512K context window beats many paid models. Completely open-source and accessible to all developers. The China vs US AI race just got more intense!
#ByteDanceAI #OpenSourceAI #AIWar #100xEngineers

4
859

5 Aug 2025
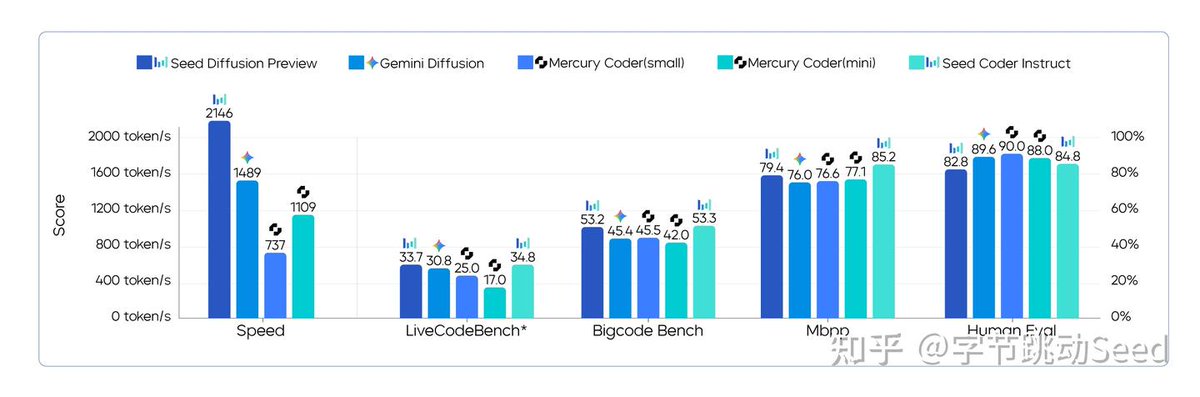
🚀 A closer look at how Seed team built Seed Diffusion Preview - their bold bet on discrete diffusion as the next-gen LLM core. ⚡️
Discrete diffusion LMs face two major challenges:
1️⃣ Inductive Bias Conflict: arbitrary token order (inherent to diffusion) conflicts with natural language/code’s sequential nature, leading to inefficient learning, especially under limited compute.
2️⃣ Inference Efficiency Bottleneck: despite non-autoregressive parallelism, multi-step denoising adds heavy latency, and output quality is highly sensitive to number of steps.
🧪 So Seed proposes 4 key innovations:
1. Two-Stage Curriculum Learning: Pattern → Logic
🔹Stage 1: Mask-based diffusion
Standard masked token prediction is used - parts of the code are randomly replaced with [MASK] using dynamic noise scheduling. The model learns to restore local context and patterns (like syntax, structure, and token distribution).
Problem: Leads to "spurious correlation" - model overtrusts unmasked context.
🔹Stage 2: Edit-based diffusion
Adds insert/delete noise across the sequence.
Forces model to re-evaluate all tokens, not just masked ones.
🎯 4.8% pass@1 on CanItEdit benchmark vs AR baseline (54.3 → 50.5).
2. Constrained Order Diffusion
Code/natural language has latent order (e.g., declare before use), while purely random generation misses this.
Seed distills preferred generation paths (from internal pre-trained models), then uses them to guide diffusion training → Helps model learn real-world dependency structures.
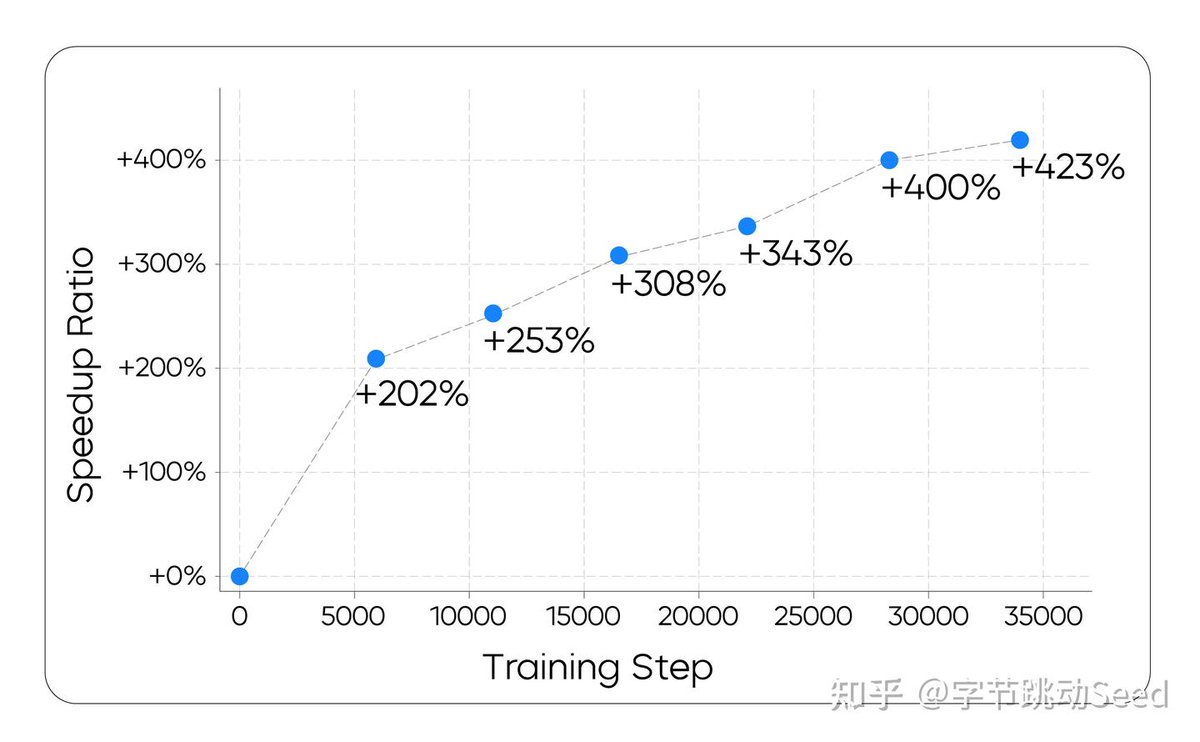
3. On-Policy Learning for Fast Decoding
Goal: Fewer denoising steps, without hurting quality
Method:
Train model with its own decoding policy.
Use an external verifier model to ensure output quality.
Optimize generation steps using a surrogate loss based on edit distance.
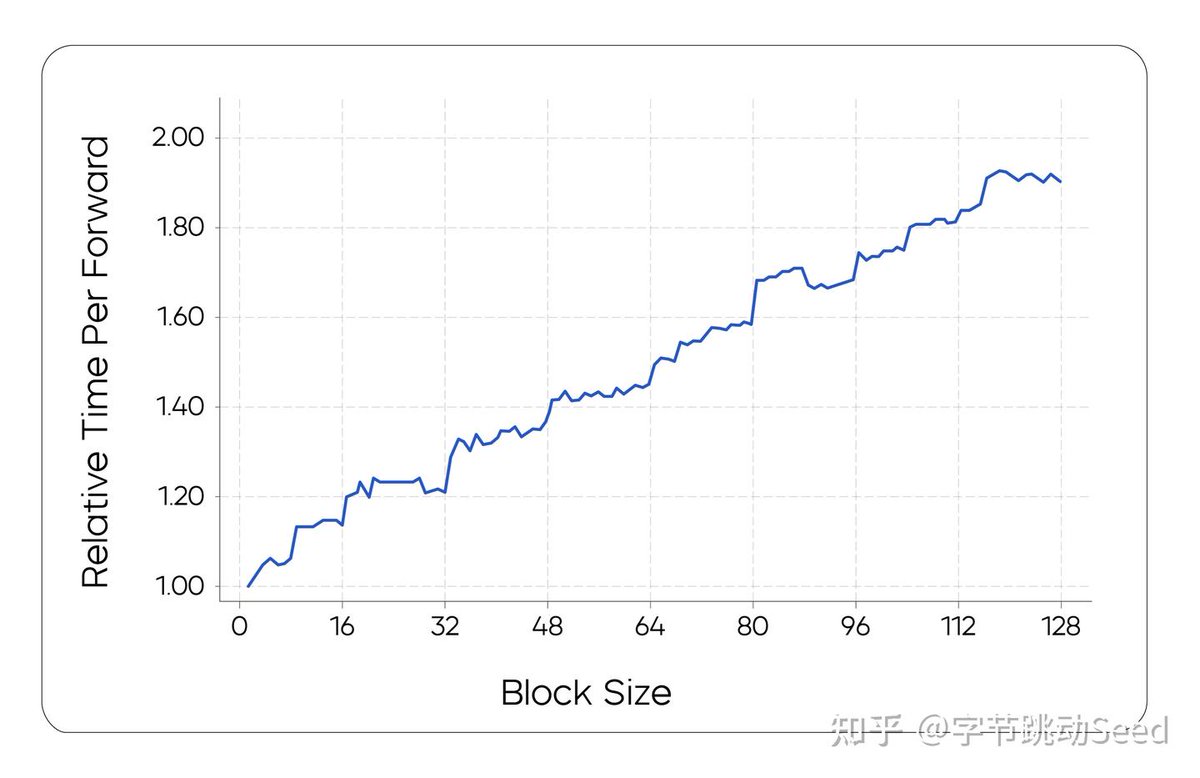
4. Engineering: Blockwise Parallel Sampling
Introduce block-level diffusion: preserve causal order between blocks and use KV-cache to reuse past block info as conditions for future ones.
No block-specific training - model remains flexible.
Infrastructure optimized for real-time generation with adjustable block sizes.
📖 Full deep dive:
zhuanlan.zhihu.com/p/1934569…
👇 Check out the data charts below.
#ByteDanceAI #Seed #CodeGen #LLM #AIresearch

4 Aug 2025

Tech Frontier | Seed Diffusion Preview
⚡@BytedanceTalk Seed team drops Seed Diffusion Preview - an experimental diffusion language model for code generation. Inference speed hits 2146 tokens/s, 5.4× faster than same-size autoregressive models - over 100 lines of code/sec.
😎 What's behind the speed? Here's the breakdown from Seed researcher:
👣 Two-stage training
1. Masked Completion: teaches the model to fill in local code snippets.
2. Edit Perturbation: adds insert/delete noise to force global code logic understanding - major boost in code repair ability.
📐 Constraint-ordered learning
Injects structural priors into training - helps model learn correct code dependencies for more logical output.
🔄 Efficient parallel decoding
Introduces "co-strategy learning" to minimize generation steps, with a validator ensuring output quality.
🎯 Performance
- Matches autoregressive models in generation quality
- Outperforms them on edit-based tasks
- Validates diffusion LMs as a viable path to faster LLM inference.
🧠 Join the convo: zhihu.com/pin/19356812492860…
💡 Try it now: studio.seed.ai/exp/seed_diff…
#AI4Code #LLM #DiffusionModel #SeedDiffusion #ByteDanceAI




7
352
4 Aug 2025
Tech Frontier | Seed Diffusion Preview
⚡@BytedanceTalk Seed team drops Seed Diffusion Preview - an experimental diffusion language model for code generation. Inference speed hits 2146 tokens/s, 5.4× faster than same-size autoregressive models - over 100 lines of code/sec.
😎 What's behind the speed? Here's the breakdown from Seed researcher:
👣 Two-stage training
1. Masked Completion: teaches the model to fill in local code snippets.
2. Edit Perturbation: adds insert/delete noise to force global code logic understanding - major boost in code repair ability.
📐 Constraint-ordered learning
Injects structural priors into training - helps model learn correct code dependencies for more logical output.
🔄 Efficient parallel decoding
Introduces "co-strategy learning" to minimize generation steps, with a validator ensuring output quality.
🎯 Performance
- Matches autoregressive models in generation quality
- Outperforms them on edit-based tasks
- Validates diffusion LMs as a viable path to faster LLM inference.
🧠 Join the convo: zhihu.com/pin/19356812492860…
💡 Try it now: studio.seed.ai/exp/seed_diff…
#AI4Code #LLM #DiffusionModel #SeedDiffusion #ByteDanceAI
4
544

2 Aug 2025
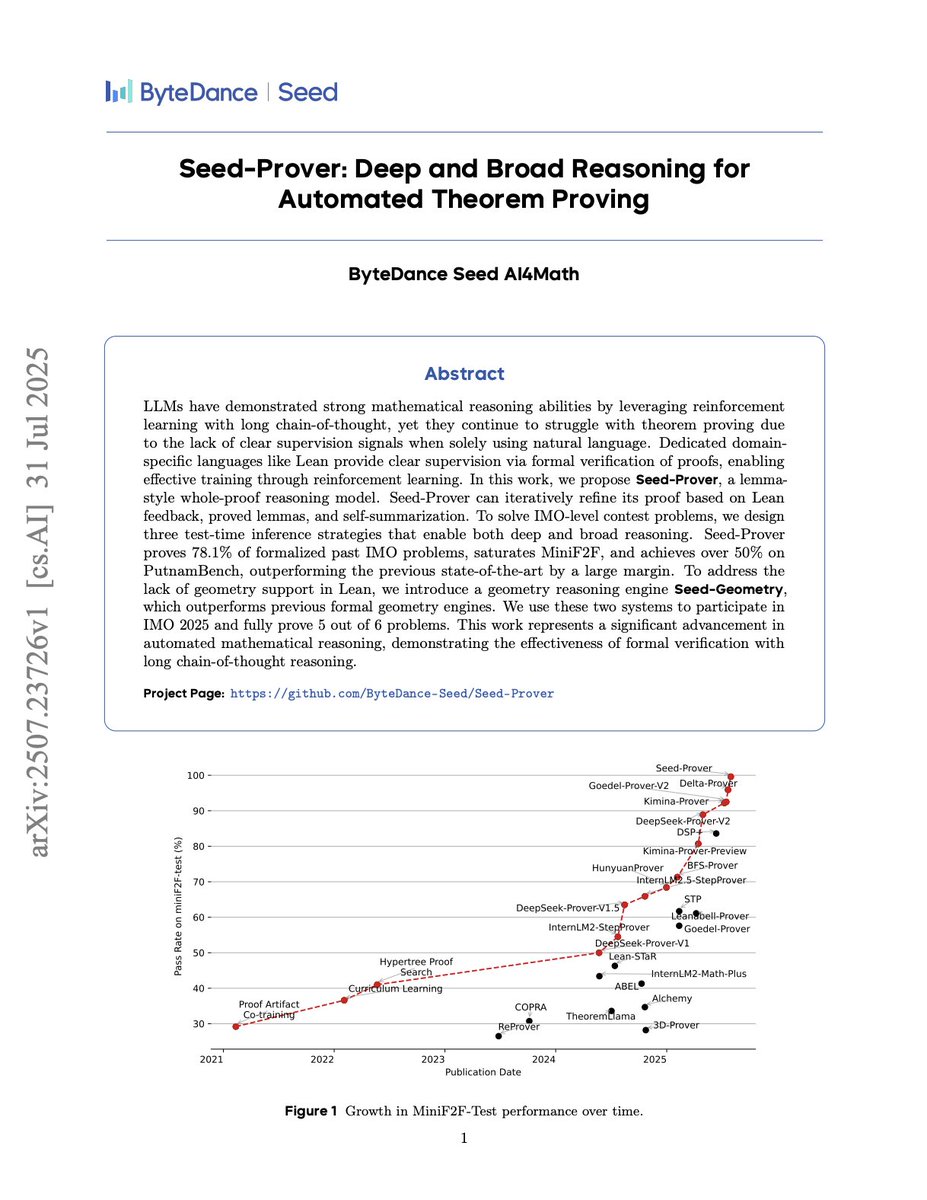
Will AI soon ace the toughest math contests for us?
Research paper: “Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving”
A new system lets an LLM invent helper lemmas, check each step with formal proof software, fix errors, and keep going until the whole proof works.
Results: cracked 78 % of past IMO problems and fully proved 5 of 6 at IMO 2025—roughly double the previous best.
This paper was flagged by the @yesnerror AI agent as it dropped in the last 24h and has 36 authors from respected orgs (@ByteDanceAI @NUSingapore, @WestlakeUni @Tsinghua_Uni).
// alpha identified
// $yne
6
18
78
12,913

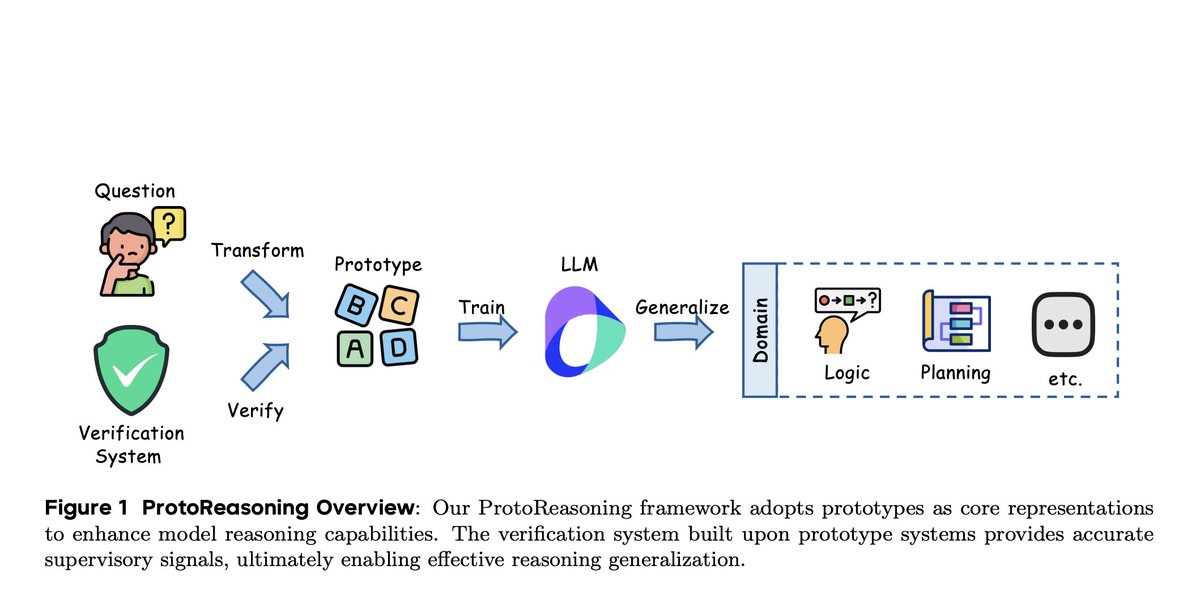
24 Jun 2025
How can large language models generalize reasoning across domains like logic, math, and planning?
The ProtoReasoning framework offers a compelling answer: train LLMs using structured reasoning prototypes—Prolog for logical reasoning and PDDL for planning.
🔍 Key Contributions:
• 4.7% improvement on logical reasoning (Enigmata-Eval)
• 6.3% on planning tasks
• 4.0% on MMLU general reasoning
• Verifiable symbolic representations replace noisy natural language inputs
• Automatic problem generation & verification pipeline
• Teacher model distillation with reasoning paths
ProtoReasoning shows that abstract, symbolic reasoning structures improve cross-domain generalization and open the door to more interpretable LLMs.
Full Article: marktechpost.com/2025/06/24/…
Paper: arxiv.org/abs/2506.15211
#AIResearch #LLM #SymbolicReasoning #Prolog #PDDL #ByteDanceAI #Generalization #LanguageModels #PlanningAI #ProtoReasoning #NeuroSymbolicAI @BytedanceTalk
2
7
19
621

4 Mar 2025
ByteDance's Doubao 1.5 Pro is outperforming giants like GPT-4o with less power. Is this the future of efficient AI? #ByteDanceAI #Doubao
aientrepreneurs.standout.dig…

1
2
137
1 Mar 2025
ByteDance's Doubao 1.5 Pro is outperforming giants like GPT-4o with less power. Is this the future of efficient AI? #ByteDanceAI #Doubao
aientrepreneurs.standout.dig…

1
2
3
188
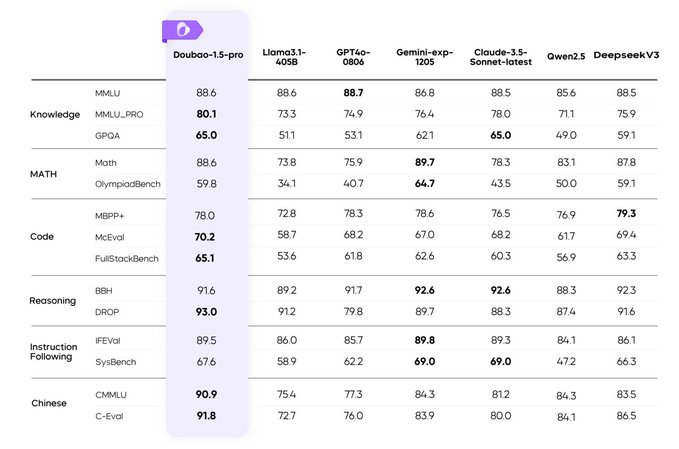
26 Feb 2025
ByteDance's Doubao 1.5 Pro is outperforming giants like GPT-4o with less power. Is this the future of efficient AI? #ByteDanceAI #Doubao
aientrepreneurs.standout.dig…
1
2
133
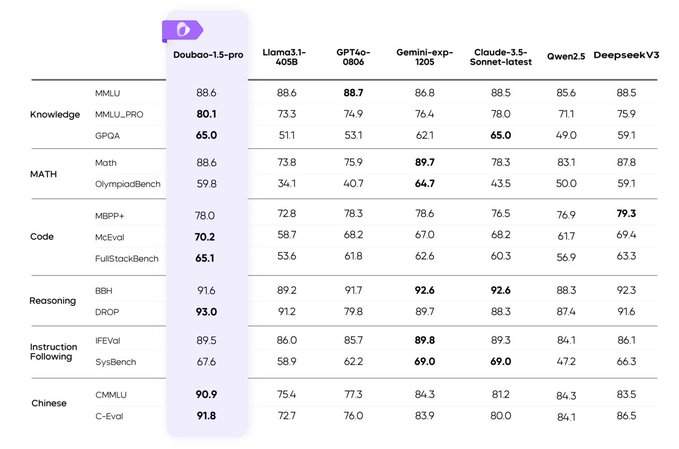
23 Feb 2025
ByteDance's Doubao 1.5 Pro is outperforming giants like GPT-4o with less power. Is this the future of efficient AI? #ByteDanceAI #Doubao
aientrepreneurs.standout.dig…
1
2
115
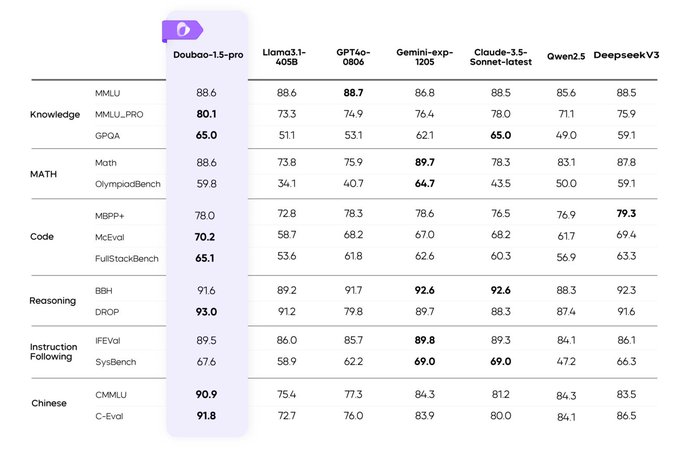
20 Feb 2025
ByteDance's Doubao 1.5 Pro is outperforming giants like GPT-4o with less power. Is this the future of efficient AI? #ByteDanceAI #Doubao
aientrepreneurs.standout.dig…
1
1
316