
Jun 12
For the last few weeks I've been understanding NKI, AWS's kernel language for writing custom ops on Trainium and Inferentia. just submitted my first kernel to the nki-samples repo: a decode-step attention kernel with GQA. A few things that clicked along the way: >Firstly, Decode attention is memory-bound, not compute-bound. Generating one token is tiny math (a single query), but it re-reads the entire growing kV cache every step. So the whole design is about touching K/V memory as few times as possible, not about FLOP.
> Grouped-query attention is a direct win here. When several query heads share one KV head, you load that K/V tile once and let the whole group ride on it. On a memory-bound kernel that saves exactly the thing that costs you.
>Online softmax is what lets you stream the KV cache in tiles instead of holding every logit at once. You carry a running max, denominator, and accumulator across tiles and rebase as each new tile arrives. Same answer, bounded memory.
> The hardware model is genuinely different coming from CUDA: matmul results can only exit through PSUM (a tiny accumulator), so you immediately evacuate to SBUF to free it for the next matmul and to let the softmax engines read it. It is validated on CPU against a NumPy reference, not yet on real Neuron hardware (just not yet).
> Next up: the split-KV flash-decoding variant for long context.
If you work on Neuron, NKI, or inference kernels, I'd love feedback on the approach.
#AWSNeuron #Trainium #Inferentia #MLSystems #NKI #KernelProgramming #Kernels #DecodeAttentionWithGQA
1
32

Jun 10
Model drift is inevitable, but executive failure shouldn't be. TOPOSMIND wraps around existing #MLSystems, shielding critical operations from erratic model shifts through an independent, logical meta-cognition layer.
11

May 26
Back from MLSys 2026 in Bellevue — a packed week at the intersection of AI and systems.
Highlights: @marksaroufim on AI writing systems code, Lidong Zhou on “system intelligence,” deep sessions on LLM serving/training, agentic AI, kernels, compilers, edge ML, benchmarking, and Industry Day.
Also great to see strong interest at the PyTorch Foundation booth all week. Thank you to everyone who stopped by — and especially to the volunteers who represented the community so well.
#MLSys2026 #PyTorch #MLSystems #AIInfrastructure

2
15
6,689

May 13
Everybody wants to be an astronaut. We need rocket scientists. 🚀 Same in AI: Lots of people want to build models; far fewer learn the systems engineering that makes AI efficient, reliable, safe, and scalable. That gap is what I’ve been trying to close for ~three years.
MLSysBook started as class notes and turned into an open textbook. Today, it sits inside a broader "AI engineering" curriculum—one open ecosystem:
• Two-volume textbook with MIT Press · Vol I (Foundations) 2026 · Vol II (At Scale) 2027 — mlsysbook.ai
• TinyTorch, build your own framework from tensors through transformers — tinytorch.ai
• MLSys·im, first principles infrastructure modeling with 22 codified systems walls — lnkd.in/eYjjEY9F
• Hardware kits spanning TinyML microcontrollers through edge systems — mlsysbook.ai/kits
• StaffML, physics-grounded interview prep for ML systems engineers — staffml.ai
• Labs, lecture slides, and an Instructor Hub for hands-on teaching — lnkd.in/ey2beYSZ
One open repository. Free. 🌍
243K readers · 24K GitHub stars · 180 countries
Thank you to everyone who reads, teaches, contributes, and sponsors this. We need more engineers who understand systems, not just models.
Enjoy 🤗
#MLSys #MLSystems #AIEngineering #TinyML



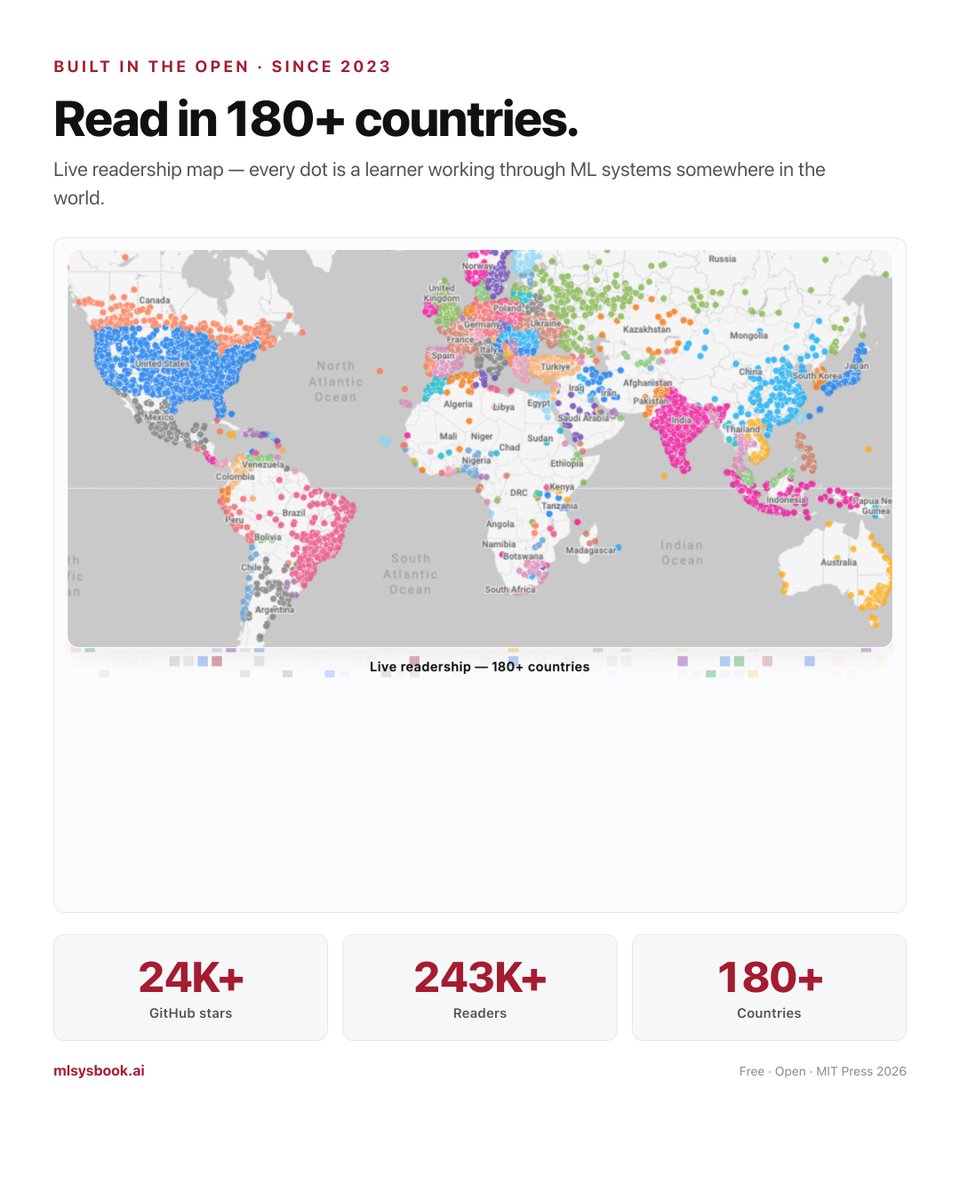
1
1
12
305

Apr 20
🚀 Excited to share our research work on Federated LLM Fine-Tuning, which is accepted to ICLR 2026 @iclr_conf
🤝 In collaboration with researchers from Stevens Institute of Technology @FollowStevens, Princeton University @Princeton, Duke University @DukeU , Google @Google , and Lambda @LambdaAPI .
📄 Mitigating Non-IID Drift in Zeroth-Order Federated LLM Fine-Tuning with Transferable Sparsity
🔗 Paper: arxiv.org/pdf/2506.03337
🌐 Efficient LLM adaptation in decentralized GPU cloud environments is challenging when client data are heterogeneous and communication is costly.
👉We introduce MEERKAT, a sparse zeroth-order optimization method for efficient federated LLM fine-tuning.
💡Rather than updating dense model parameters, MEERKAT focuses optimization on a transferable, extremely sparse (<0.1%) subset of parameters, dramatically reducing communication overhead while mitigating Non-IID data drift across clients.
🛡️The method also automatically identifies clients with extreme data heterogeneity and applies early stopping, improving aggregation stability and overall model quality.
📊 Key Results:
•🚀 Enables efficient LLM fine-tuning in decentralized GPU cloud settings
•⚡ Updates fewer than 0.1% of parameters for major communication savings
•🔁 Mitigates Non-IID drift across heterogeneous clients
•🛠️ Detects unstable clients and improves robustness with early stopping
•🏆 Achieves stronger aggregated model quality
✨ Takeaway:
For federated LLMs, efficient adaptation may depend less on updating everything and more on optimizing the right sparse, transferable parameters.
🙌 Huge shoutout to our collaborators: @ran_yide42201 , @WentaoGuo7 , Jingwei Sun, Yanzhou Pan, Xiaodong Yu, Hao Wang, @jianwen_xie, Yiran Chen, @denghui_zhang , and @ZhaozhuoX
#ICLR2026 #LLM #FederatedLearning #MLSystems #DistributedSystems #EfficientAI #neurips #icml
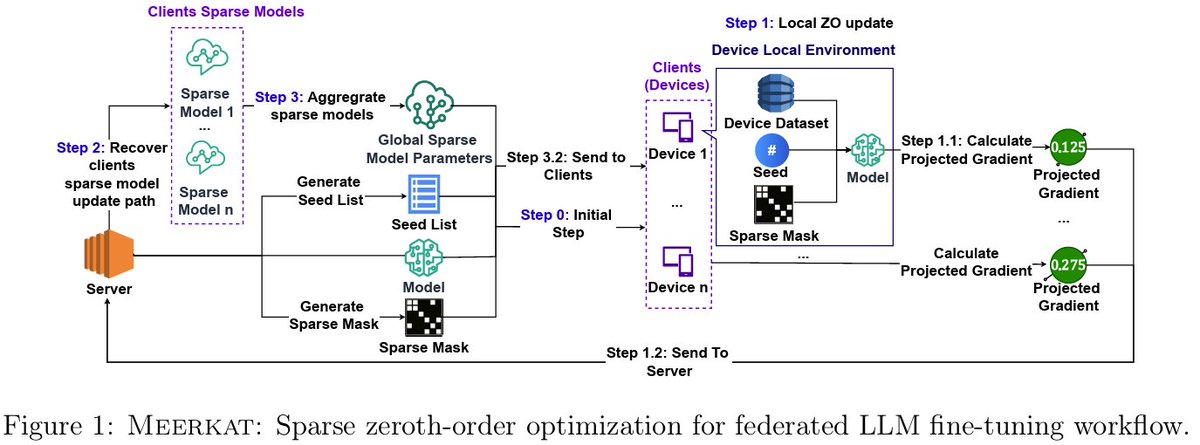
3
3
16
1,508

Apr 12
🔬 Hiring 2 undergrad research interns (6 months) at Microsoft Research India.
The transformer has been the default encoder for dense retrieval. But under the low-latency constraints of real production systems, it becomes a serious bottleneck on retrieval performance, deep encoders are accurate but too slow, shallow ones are fast but lossy.
So we're asking fundamental questions:
→ What assumptions are we baking in when we reach for a transformer to solve a task?
→ What alternative scalable encoder architectures can exploit the natural biases of retrieval better than the transformer does?
What interns will actually work on over 6 months:
→ Critically analyzing where transformer-based dense encoders fall short under production retrieval pressure
→ Exploring alternative architectures that preserve deep-encoder accuracy at a fraction of the inference cost
→ Data compute efficient training algorithms for large dense encoders
Strong Python PyTorch. Bonus if you've trained an encoder or built a retrieval pipeline end-to-end.
For undergrads who treat "why is the architecture shaped this way?" as a real question.
Apply: forms.office.com/r/G1TyJZCFG…
DMs open.
#InformationRetrieval #MLSystems #NLProc
@MSFTResearch
18
18
226
19,441

SimpleFold-Turbo: Adaptive Inference Caching Yields 14-fold Acceleration of Flow-matching Protein Structure Prediction
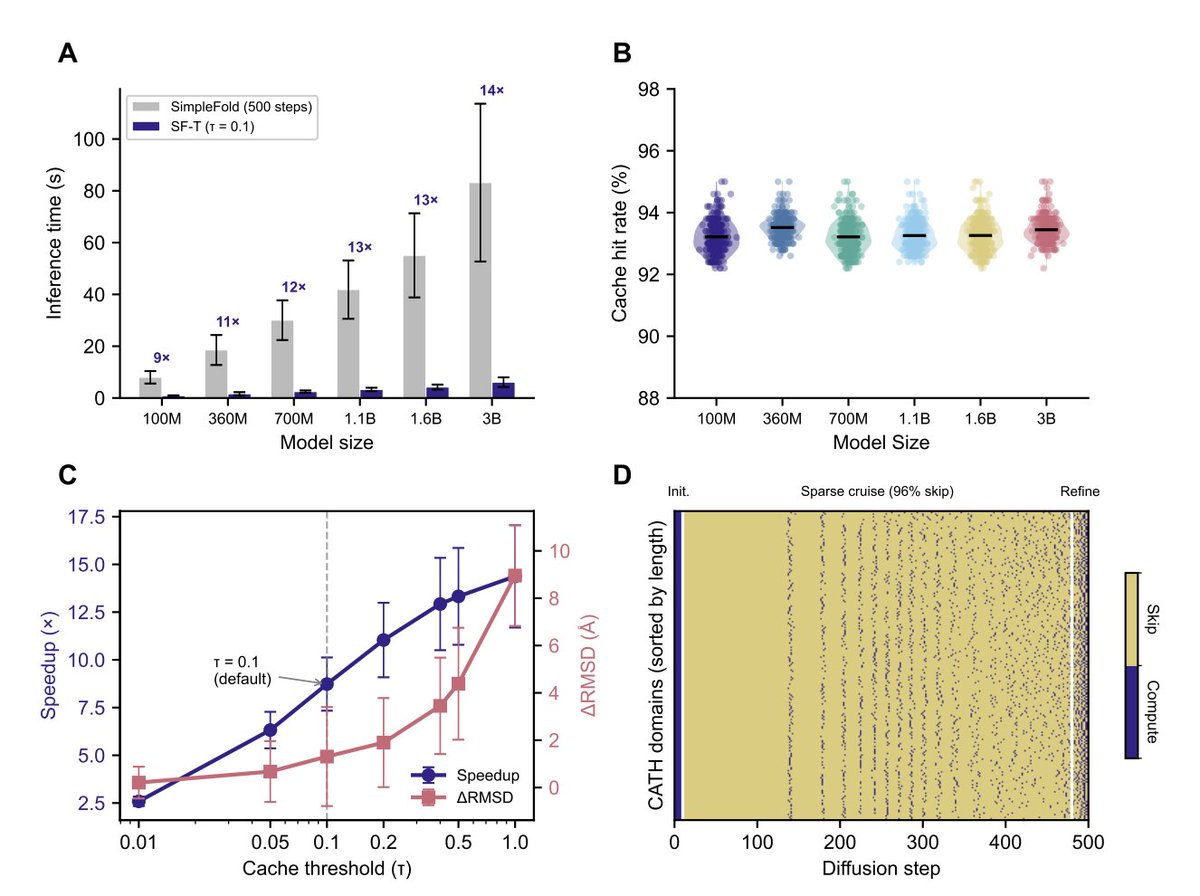
1 SimpleFold-Turbo (SF-T) adapts TeaCache-style adaptive inference caching to SimpleFold’s flow-matching protein structure predictor, delivering ~9–14x end-to-end inference acceleration while maintaining essentially unchanged structure quality.
2 The core observation is that flow-matching trajectories for protein coordinates are near-linear, making consecutive neural network evaluations highly redundant; SF-T exploits this by skipping forward passes when a cheap per-step signal changes less than a threshold and reusing the previous velocity/output.
3 With default threshold τ = 0.1, SF-T skips ~93% of forward passes (about 36 computed steps out of 500; IQR 34–37) across 300 diverse CATH domains and all six SimpleFold model sizes (100M to 3B params).
4 Speedup increases with model size (~9x at 100M up to ~14x at 3B) because caching overhead is roughly constant while the cost of each forward pass grows with parameter count.
5 Coordinate-level fidelity to uncached SimpleFold remains tight: mean ΔRMSD (cached vs uncached prediction) is ~0.36 Å at τ = 0.1, well below typical experimental structure resolution, suggesting the cache introduces negligible perturbations relative to model accuracy.
6 Against experimental ground truth, SF-T preserves accuracy: TM-scores vs CATH structures match baseline SimpleFold across all model sizes (ΔTM around zero with confidence intervals spanning zero), indicating the acceleration does not meaningfully degrade biological usefulness.
7 SF-T strongly outperforms static step reduction at matched compute: log-uniform step-skipping with ~36 steps (similar compute to SF-T’s ~36 executed steps) collapses TM-score quality (often near-useless structures), while adaptive caching retains near-baseline TM-scores—implying compute must be concentrated where the trajectory actually bends.
8 A universal three-phase skip pattern emerges across proteins: (i) initialization steps 1–10 compute-only (0% skip), (ii) “sparse cruise” steps 11–480 with ~96% skip, and (iii) refinement steps 481–500 with lower skip (~64%), consistent with higher curvature near convergence.
9 Cacheability correlates with chain length (r ~0.71–0.78) but not with fold/secondary-structure composition (|r| < 0.3) or other sequence properties, supporting a geometric/trajectory-smoothness explanation rather than biophysical class dependence.
10 Practically, SF-T requires no retraining, no weight modifications, and no MSA or server dependencies; the implementation targets commodity hardware (MLX on Apple Silicon with PyTorch fallback) and aims to make high-throughput, offline structure prediction more accessible and energy-efficient.
💻Code: github.com/usnistgov/simplef…
📜Paper: biorxiv.org/content/10.64898…
#ProteinStructure #DiffusionModels #FlowMatching #ComputationalBiology #Bioinformatics #MLSystems #InferenceOptimization #OpenSource #DemocratizingAI
1
9
58
28,043

Agentic AI needs memory to be useful.
This upcoming webinar examines how memory systems—short- and long-term—enable agents to reason, adapt, and act over time in real-world workflows.
🔗 edge-ai-vision.com/2026/03/u…
#EdgeAI #AgenticAI #AIArchitecture #MLSystems
1
2
2
59

Mar 26
9/N. What speculative decoding results have you seen in your own deployments? We would love to hear what works (and what doesn't).
Paper: arxiv.org/abs/2601.11580
Blog: specdecode-bench.github.io
Code: github.com/orgs/SpecDecode-B…
#LLM #MLSystems #SpeculativeDecoding
1
6
452

Mar 6
GPUs still optimize compute and communication separately. That leaves performance on the table.
CUCo is our agentic, training-free framework that rewrites CUDA NCCL programs to jointly co-design compute communication on device, unlocking overlap, fusion, and pipelining.
Up to 1.57× end-to-end latency reduction on MoE, KV-cache transfers, FlashAttention context parallelism, and GEMM AllGather.
📄 arxiv.org/abs/2603.02376
🌐 ut-infraai.github.io/cuco/
💻 github.com/UT-InfraAI/cuco
#CUDA #MLSystems #GPU #HPCL
@BodunHu @utnslab
2
15
157
11,371

>Grinding always works chaps
>all container are healthy.....
>if any startups work on this MLsystems, redis, ML or MLOps, i love to contribute....
ping me DMs
1
3
50

Can operator kernels really be generated from natural language?
KernelGen turns prompts into operator definitions, runs accuracy & performance tests automatically, and outputs validated kernels.
🎥 Watch demo & try it ↓ kernelgen.flagos.io/login
#KernelGen #AIInfra #MLSystems
2
1,048

Jan 29
New open-source tool from the CONVOLVE project
We’re pleased to introduce OML-vect, an open-source tool developed at Universidad Murcia @UMU within the CONVOLVE project.
Built on ONNX-MLIR, OML-vect transforms machine-learning models into efficient, hardware-aware vectorised code, supporting high-performance and scalable ML execution.
🔓 Open source | ⚙️ ML optimisation | 🚀 Performance-oriented toolchains
Designed for compiler, ML systems, and HPC communities, OML-vect contributes to CONVOLVE’s growing ecosystem of open, reusable AI tooling.
👉 Available on GitHub (github.com/CAPS-UMU/onnx-mli…) and Docker (hub.docker.com/r/shreyasubha…)
#CONVOLVE #HorizonEurope #OpenSource #AIEngineering #MLSystems #Compilers #ONNX #MLIR #HighPerformanceComputing #HPC #EdgeAI #EuropeanAI #TrustworthyAI

2
4
174

Jan 26
While building Proovia:Chasing marginal gains (75% → 85% accuracy) in detection models can be more expensive than useful early on.Would you prioritize ensemble APIs product learning first, then replace with in-house models later?#Proovia #MLSystems #AIStartups
1
41

Jan 23
📣 Call for Papers, ICLR 2026 Workshop
Catch, Adapt, and Operate (CAO): Monitoring ML Models Under Drift
As ML systems move from benchmarks to real-world deployment, distributional drift becomes unavoidable. This workshop brings together researchers and practitioners working on how to monitor, adapt, and reliably operate machine learning models in dynamic environments.
📄 Submission Tracks
To encourage a broad range of contributions, CAO offers multiple tracks:
🔹 Main Track
Full technical papers with solid methodology and experimental validation.
🔹 Tiny Papers Track
Shorter papers for early ideas, focused insights, or promising preliminary results.
🔹 Special Track, Lessons from Failures
A dedicated space for negative results, failed experiments, and practical lessons that don’t always fit traditional venues , but are critical for progress in real-world ML.
Paper submissions now open !
📍 Rio de Janeiro, Brazil
🔗 sites.google.com/view/iclr-2……
#ICLR2026 #MachineLearning #MLSystems #ModelMonitoring
@iclr_conf #ICLRworkshop #iclr2026


1
8
26
30,658

Jan 16
AI progress is now limited by compute, not ideas.
What matters most is efficiency, placement, and how models run in production.
#AICompute #MLSystems #Inference
4
155

23 Dec 2025
✨ Starting 2026 with a builder’s mindset ✨
If one of your goals this year is to build your own language model from scratch, you’re already on the right path.
As part of my 21 Days of Building a Small Language Model journey (we’ve just reached Day 15 🚀), and thanks to our sponsor, I’m giving away 5 free copies of my book to the community.
How to participate:
📌Follow the 21 Days of Building a Small Language Model series
📌If you’ve learned anything from it so far
📌Create a post sharing your takeaway and tag me
That’s it.
I’ll pick 5 lucky builders and share the book with them as a small way of saying thank you for showing up and learning in public.
Let’s keep building. Let’s push our limits. And let’s make 2026 the year we stop consuming and start creating.
🎉 Happy New Year in advance!
🔗 Series repository:
github.com/ideaweaver-ai/21-…
📚 Book link
✅ Gumroad: plakhera.gumroad.com/l/Build…
✅ Amazon: amazon.com/dp/B0G64SQ4F8/
✅ Leanpub: leanpub.com/buildingasmallla…
#BuildingInPublic #SmallLanguageModels #LLMFromScratch #GenerativeAI #AIEngineering #MLSystems #DeepLearning #OpenSource #LearnInPublic #DevOpsAI #Founders #AICommunity #2026Goals @nvidia @OpenAI @AnthropicAI

1
23
17 Dec 2025
📌 At IndoML this week (Dec 19-21)?
Come find me or other researchers from MSRI. Open Positions: Researcher, Research SDE, PostDoc & 6-month internships.
We're rethinking retrieval from first principles - asking why current retrieval models fail to scale efficiently to 100B docs.
The impact:
→ Ship to billions of users
→ Publish to move the field forward
→ Shape how foundation models access knowledge
For people who see retrieval as an unsolved systems ML problem, not an API call.
DM me or catch us at the symposium.
@MSFTResearch @indoml_sym @bitshyd #IndoML2025 #InformationRetrieval #MLSystems #NLProc

10 Dec 2025

Hiring @ Microsoft Research India 2025
🔬 We're pushing retrieval models past their breaking point at MSR India, working on problems that don't have solutions yet at extreme scale.
Deep work on retrieval architectures, embedding systems, and large-scale IR. Also need sharp minds on ML systems, foundation models, and efficient architectures if you think about scale differently.
Real autonomy: publish at top venues ship to billions of users.
Apply: apply.careers.microsoft.com/… | DM me for specifics
#InformationRetrieval #MLSystems #NLP #AI
@MSFTResearch @IndiaMSR
3
3
95
9,251
10 Dec 2025
Hiring @ Microsoft Research India 2025
🔬 We're pushing retrieval models past their breaking point at MSR India, working on problems that don't have solutions yet at extreme scale.
Deep work on retrieval architectures, embedding systems, and large-scale IR. Also need sharp minds on ML systems, foundation models, and efficient architectures if you think about scale differently.
Real autonomy: publish at top venues ship to billions of users.
Apply: apply.careers.microsoft.com/… | DM me for specifics
#InformationRetrieval #MLSystems #NLP #AI
@MSFTResearch @IndiaMSR
1
4
30
10,702