
Pickle is still one of the easiest RCE vectors in ML pipelines in 2026.
It's not a serializer. It's a stack VM. Attackers drop a class with __reduce__ that calls os.system or subprocess on load.
Simple string scanning fails because modern protocols separate the import (STACK_GLOBAL) from execution (REDUCE). Obfuscation works.
I wrote a small scanner that walks pickletools.genops() safely, simulates the stack, and flags dangerous globals REDUCE gates.
If you're loading .pkl models from Hugging Face or anywhere untrusted - stop. Use weights_only=True or migrate to SafeTensors.
This is table stakes now.
farrosfr.com/p/detecting-mal…
#MLSecurity #RedTeam #CyberSecurity #Pickle #SafeTensors
6

May 27
🚫 Web Malware Scan Results
Website: mines-online.de
Security Verdict: CONFIRMED SCAM
Full analysis & details:
scanmalware.com/scan/c3e7b2f…
#MLSecurity #WebMalware #SOCAnalyst #SecurityAwareness #AIThreatDetection
2
7

May 25
The Security Engineer's Guide to AI Certification That Actually Makes You Dangerous
Most security certifications age out fast.
You pass the exam. You get the badge. Then six months later, the threat landscape shifts and half of what you studied is already behind the curve.
AI security doesn't work like that and the certifications catching up to it definitely don't either.
That's exactly why the Certified AI Security Expert (MSec-CAIS) from Modern Security caught my attention. It's not a theory dump. It's not a slide deck with a quiz at the end. It's a course built around one idea:
You cannot secure something you've never broken.
What's Actually Going On With AI Security Right Now
Security teams are being asked to review, audit, and defend AI-powered applications RAG pipelines, LLM APIs, agentic workflows, MCP servers built by engineering teams that move fast and don't always think about attack surfaces.
The problem? Most security professionals have never built these systems. They're reviewing code they don't fully understand, writing threat models for architectures they've only read about, and giving recommendations that sound good on paper but miss the actual risk.
The MSec-CAIS flips that completely.
Build First. Then Break It.
The course opens with something most security certifications skip entirely actually building real GenAI applications.
You'll work with LLM APIs hands-on. You'll build RAG systems using real vector databases. You'll set up agentic workflows, integrate LangChain and LangSmith, and construct your own MCP servers from scratch.
Why? Because when you later attack these same architectures in the offensive labs, you're not guessing. You know how the plumbing works.
Modules cover:
— Embeddings and how LLMs process internal data
— Vector databases and querying them for AI applications
— Retrieval-Augmented Generation (RAG)
— built and tested in real labs
— AI agents: the Think → Act → React → Observe loop that makes them autonomous
— MCP (Model Context Protocol)
— what it is, why it matters, and how it gets exploited
— LangChain and LangSmith for orchestration and observability
By the time you reach the offensive section, you've already shipped a working threat model agent. That context changes everything.
The Offensive Section Is Where It Gets Real
This is the section most courses gloss over with a few screenshots and a OWASP checklist.
MSec-CAIS runs you through live attack labs on applications you helped build. Some of what you'll actually do:
Prompt Injection — Using a real Essay AI app built for the course, you'll learn how attackers manipulate model behavior by hijacking the prompt context. Not just what it is how it works, why it works, and exactly where the model breaks.
Indirect Prompt Injection — Harder to catch, more dangerous in production. You'll exploit a Personal Assistant bot through indirect vectors embedded user inputs that never look like an attack on the surface.
Sensitive Information Disclosure — Attacking an AI Support Bot to understand how poorly scoped context windows and weak output controls leak data that was never meant to leave the system.
MCP Attacks — You'll build your own MCP servers (both local and remote, SSE vs stdio), then turn around and attack them. This section alone is worth the price of the course given how fast MCP adoption is growing right now.
Model Backdoors — Using a real-world Hugging Face example, you'll see how adversaries embed hidden behavior into model weights. Trigger conditions. Payloads. The whole chain.
Agentic Architecture Attacks — When agents have tool access and decision-making authority, the attack surface multiplies. This module covers what that actually looks like in practice.
AI Supply Chain — End-to-end coverage: dependency pinning, model scanning, AIBOMs, model signing with Sigstore, MLFlow integration, and how to build a secure AI pipeline from the ground up.
Defense That Goes Beyond "Add a Filter"
After offense, the course pivots to defense and this is where it separates from most security training.
It's not just "add input validation." It's architecture-level thinking.
You'll go back through every attack you ran and fix it either at the application layer or by making structural changes to the design. The difference between slapping a guardrail on a broken system and actually building a secure one.
Specific defensive work includes:
— Inline LLM guardrails implementation
— MCP Gateways for observability and detection
— Defending prompt injection in two dedicated modules
— Protecting against sensitive data disclosure
— Agentic security architecture patterns
— Multi-layered defense strategy
— why one control is never enough
Who Built This and Why That Matters
The instructor is Harish Ramadoss Principal at Trustwave SpiderLabs, founding security engineer at Rippling, and currently leading their AI Security and Application Security work.
He's presented research at Black Hat, DEF CON, HITB, and BSides. He built DejaVU an open-source deception platform and runs practical AI security training at NorthSec.
This isn't someone who learned AI security to build a course. It's someone who does this work daily, built the curriculum from actual production experience, and translated it into 38 structured lessons with hands-on labs.
Who This Is Built For
Security Engineers adding AI/LLM coverage to their work Penetration Testers & Red Teamers learning how to assess AI-native applications Developers building AI features who want to understand the risks they're shipping Technical Leaders who need to evaluate risk, not just rubber-stamp architecture reviews
No prior AI or LLM background required. The course builds that foundation before it tests it.
The industry is moving. AI is already in production at companies that haven't thought seriously about the attack surface. Security professionals who understand how these systems work not just in theory, but hands-on are going to be the ones who actually find the vulnerabilities and fix them.
The MSec-CAIS gives you that.
38 lessons. Real labs. Real attacks. Real fixes.
Self-paced, with a certificate on completion.
modernsecurity.io/courses/ai…
If you're in security and not yet thinking about LLM attack surfaces, this is the starting point.
#AISecurity #LLMSecurity #AISecurityCertification #CyberSecurity #RedTeam #PenTesting #LLM #MCP #AgenticAI #InfoSec #SecurityEngineering #MachineLearning #MLSecurity #PromptInjection #ThreatModeling
3
26

AI digest: OpenAI Yubico security keys, IBM Granite 4.1 punches above its weight, malware in PyTorch Lightning, and per-token Copilot pricing lands. Big week for inference infrastructure. 🔐⚙️ Read: swiftinference.ai/blog/ai-di… #AIInfrastructure #LLM #MLSecurity
11
15
153

Apr 18
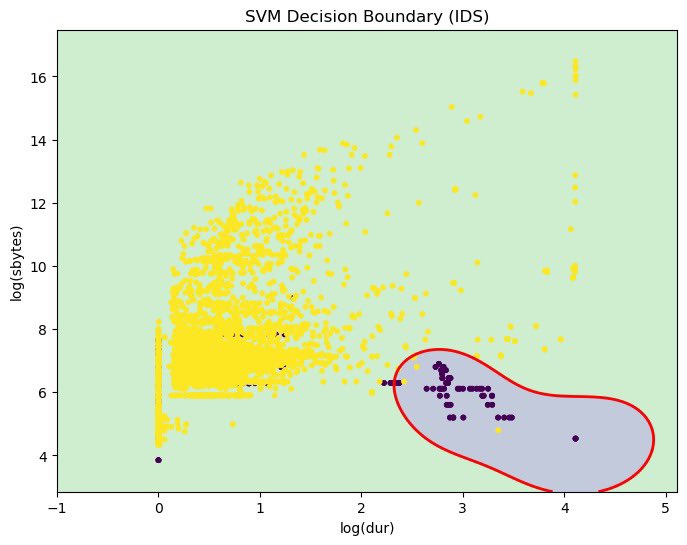
Built an IDS experiment comparing linear vs non-linear models:
Linear models showed high accuracy… but struggled with real attack detection.
Random Forest performed better: it captures complex, non-linear patterns in network traffic.
Accuracy ≠ Security.
#CyberSecurity #MachineLearning #IDS #MLSecurity

2
37

⚠CVE-2026-5869 – Chrome WebML heap buffer overflow (High): third WebML memory corruption issue in this release, further tightening ML-in-browser attack surface. Update to 147.0.7727.55/56. chromereleases.googleblog.co… #CVE20265869 #Chrome #WebML #MemoryCorruption #MLSecurity #InfoSecNews
2
13

Mar 24
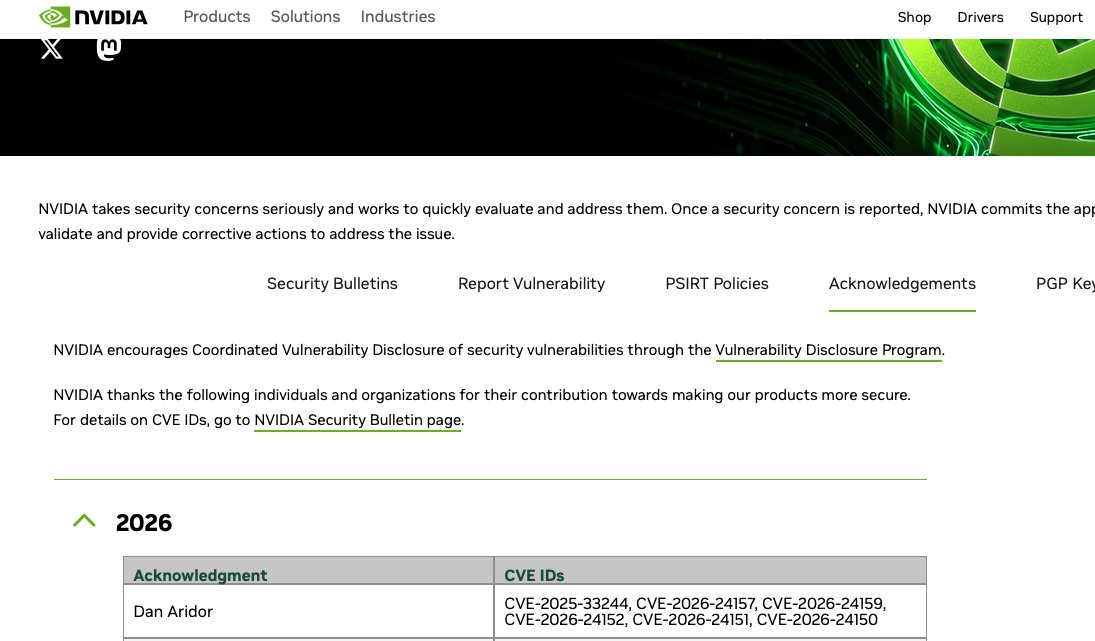
Grateful to share that NVIDIA has acknowledged 11 CVEs credited to me across two security bulletins — including 6 in their 2026 acknowledgements page published this week.
This is the result of months of systematic research through SPR{K}3, a security platform I've been building that applies biological pattern recognition to ML infrastructure analysis. The platform doesn't just look for known vulnerabilities — it detects coordinated attack patterns across ecosystems that traditional scanners miss entirely.
The 11 CVEs span NVIDIA's NeMo Framework and cover a range of code injection and remote code execution vectors in AI training and inference pipelines. Each one was found, manually verified, and disclosed responsibly with a full technical report and 90-day timeline.
A few things this work has reinforced for me:
→ ML supply chain security is still a largely unsolved problem. Most tooling is optimized for web applications, not for the specific threat model of AI frameworks.
→ Volume without quality is noise. A zero false-positive submission record matters more than submission count — both for vendor relationships and for real-world impact.
→ The attack surface is growing faster than the defenses. Distributed training systems, model serialization, and LLM orchestration layers are rich with undiscovered vulnerabilities.
The NVIDIA findings are part of a broader research track record. SPR{K3 has surfaced confirmed vulnerabilities across:
• NVIDIA — NeMo Framework (code injection, RCE in AI pipelines)
• Microsoft — Semantic Kernel (RCE via unsafe deserialization)
• Amazon — AutoGluon (remote code execution via unsafe pickle in model loading)
The platform is getting production-ready. The research pipeline is systematic. We're at an early but meaningful inflection point for ML security as a category.
If you're working in ML security, AI infrastructure, or venture — and this work is relevant to what you're building — I'd be glad to connect.
#MLSecurity #VulnerabilityResearch #AIInfrastructure #BugBounty #NVIDIA #CyberSecurity
sprk3.com
#MLSecurity #VulnerabilityResearch #AIInfrastructure #BugBounty #NVIDIA #CyberSecurity

2
9
331

Mar 18
🚨 𝗜𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝗶𝗻𝗴 𝗖-𝗔𝗜/𝗠𝗟𝗣𝗲𝗻 𝘃𝟭.𝟮: 𝗕𝘂𝗶𝗹𝘁 𝗳𝗼𝗿 𝘁𝗵𝗲 𝗠𝗼𝗱𝗲𝗿𝗻 𝗔𝗜 𝗧𝗵𝗿𝗲𝗮𝘁 𝗟𝗮𝗻𝗱𝘀𝗰𝗮𝗽𝗲
𝘌𝘯𝘨𝘢𝘨𝘦 𝘸𝘪𝘵𝘩 𝘵𝘩𝘪𝘴 𝘱𝘰𝘴𝘵 🗨️ (𝙡𝙞𝙠𝙚, 𝙘𝙤𝙢𝙢𝙚𝙣𝙩 & 𝙨𝙝𝙖𝙧𝙚) 𝘢𝘯𝘥 𝟯 𝙡𝙪𝙘𝙠𝙮 𝙥𝙧𝙤𝙛𝙚𝙨𝙨𝙞𝙤𝙣𝙖𝙡𝙨 𝙬𝙞𝙡𝙡 𝙬𝙞𝙣 𝙖 𝙁𝙍𝙀𝙀 𝘾-𝘼𝙄/𝙈𝙇𝙋𝙚𝙣 𝙚𝙭𝙖𝙢 𝙫𝙤𝙪𝙘𝙝𝙚𝙧.
As prompts and attack techniques continue to evolve, AI systems are being tested in increasingly creative ways. To keep pace with the rapidly changing LLM security landscape, we’ve updated the challenges in C-AI/MLPen and are excited to release v1.2 of the exam.
✅ 𝗧𝗵𝗲 𝗻𝗲𝘄 𝘃𝗲𝗿𝘀𝗶𝗼𝗻 𝗶𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝗲𝘀 𝘁𝗼𝘂𝗴𝗵𝗲𝗿 𝘀𝗰𝗲𝗻𝗮𝗿𝗶𝗼𝘀 𝗮𝗻𝗱 𝗺𝗼𝗿𝗲 𝗮𝗱𝘃𝗮𝗻𝗰𝗲𝗱 𝘁𝗲𝘀𝘁𝗶𝗻𝗴 𝗼𝗯𝗷𝗲𝗰𝘁𝗶𝘃𝗲𝘀 𝗱𝗲𝘀𝗶𝗴𝗻𝗲𝗱 𝘁𝗼 𝗯𝗲𝘁𝘁𝗲𝗿 𝗿𝗲𝗳𝗹𝗲𝗰𝘁 𝗿𝗲𝗮𝗹-𝘄𝗼𝗿𝗹𝗱 𝗔𝗜/𝗟𝗟𝗠 𝘃𝘂𝗹𝗻𝗲𝗿𝗮𝗯𝗶𝗹𝗶𝘁𝗶𝗲𝘀 𝗮𝗻𝗱 𝗮𝗱𝘃𝗲𝗿𝘀𝗮𝗿𝗶𝗮𝗹 𝘁𝗲𝗰𝗵𝗻𝗶𝗾𝘂𝗲𝘀.
💥 𝗨𝘀𝗲 𝟳𝟱% 𝗗𝗶𝘀𝗰𝗼𝘂𝗻𝘁 𝗖𝗼𝗱𝗲: 75-OFF at checkout
If you work in 𝗔𝗜 𝘀𝗲𝗰𝘂𝗿𝗶𝘁𝘆 𝗼𝗿 𝗟𝗟𝗠 𝗽𝗲𝗻𝘁𝗲𝘀𝘁𝗶𝗻𝗴, it’s a great opportunity to put your skills to the test and validate them through a practical challenge.
Here's your shot 👉 pentestingexams.com/certific…
#AI #MachineLearning #ArtificialIntelligence #DeepLearning #DataScience #AISecurity #MLSecurity #CyberSecurity #LLMSecurity #AIThreats #LargeLanguageModels #LLM #GenAI #AIInnovation #TechTrends #AIEngineering #MLOps #AIDevelopment #SecureAI #ResponsibleAI #LearningInPublic #TechCommunity #Pentesting

23
21
43
1,816

On the (In)Security of Loading Machine Learning Models
We identified six zero-day vulnerabilities, including the first CVEs ever assigned to Keras safe_mode. Our results show that loading a machine learning model can be equivalent to executing untrusted code, despite the security claims often present in framework and hub documentation.
We also show that Hugging Face’s integrated scanners do not always provide an effective additional line of defense against framework-level exploits. Finally, through a survey of machine learning practitioners, we show that security claims in framework and hub documentation can create misplaced trust. For example, over 90% of non-security ML practitioners perceived no risk of arbitrary code execution when safe_mode=True.
Source: arxiv.org/pdf/2509.06703
#MLSecurity #AISecurity #ModelSecurity #MachineLearning #SecureAI #ModelSupplyChain #ModelLoading #ArbitraryCodeExecution #SoftwareSecurity #CyberSecurity #AIVulnerabilities #ModelHubSecurity #SecureML #AIAttackSurface #IEEEsp #SecurityResearch

1
2
17
912

Your AI is already vulnerable. You just don't know it yet.
I tested 6 major LLM deployments last year. Every single one had a bypass within 5 prompts. The problem isn't the model. It's how the industry tests them.
Static jailbreak lists go stale the moment a model is patched. Manual red teaming doesn't scale. And most AI security tools are just payload lists with a UI.
So I built something different. Basilisk uses a genetic algorithm that breeds adversarial prompts across generations. The weak ones die. The strong ones mutate and reproduce. By generation 5 - 92% better than any static payload list. If your LLM resists round 1, Basilisk evolves until it doesn't. I published the full research paper with a
permanent DOI. Peer reviewed. Indexed globally.
Want to see it live right now?
No API keys. No setup. One command:
pip install basilisk-ai
basilisk scan -t https://basilisk-vulnbot[dot]onrender[dot]com/v1/chat/completions -p custom --model vulnbot-1.0 --mode quick
Watch it find 30 vulnerabilities in real time.
Free. Open source.
See it evolve 👇
#LLMSecurity #AIRedTeaming #CyberSecurity
#OffensiveSecurity #OWASP #AIGovernance
#PromptInjection #OpenSource #RedTeam
#GenerativeAI #AppSec #MLSecurity
3
38
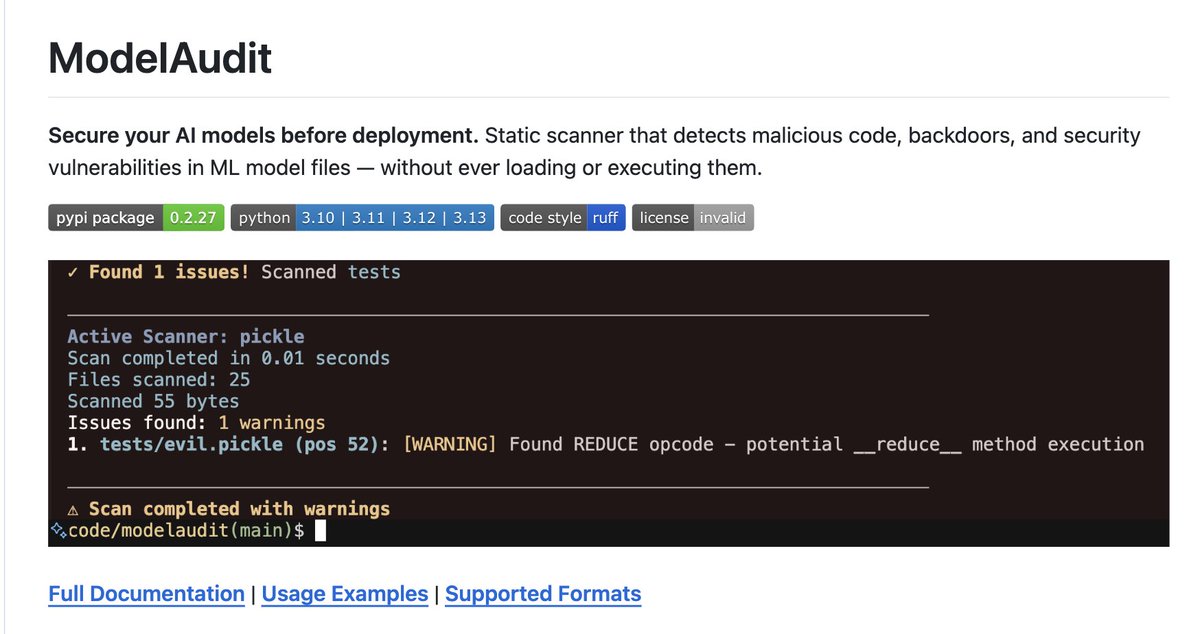
modelaudit - github.com/promptfoo/modelau…
ModelAudit is a static scanner for ML model files. It flags unsafe loading behaviors (deserialization RCE, archive tricks), known CVEs, and suspicious artifacts across 42 formats, without executing the model or importing ML frameworks.
1️⃣ Code execution attacks in Pickle, PyTorch, NumPy, and Joblib files
2️⃣ Model backdoors with hidden functionality or suspicious weight patterns
3️⃣ Embedded secrets - API keys, tokens, and credentials in model weights or metadata
4️⃣ Network indicators - URLs, IPs, and socket usage that could enable data exfiltration
5️⃣ Archive exploits - path traversal, symlink attacks in ZIP/TAR/7z files
6️⃣ Unsafe ML operations - Lambda layers, custom ops, TorchScript/JIT, template injection
7️⃣ Supply chain risks - tampering, license violations, suspicious configurations
More: promptfoo.dev/blog/open-sour…
#AISecurity #MLSecurity #ModelSecurity #MLOpsSecurity #AISupplyChainSecurity @promptfoo
1
6
42
1,907

AI hacking focuses on identifying vulnerabilities unique to machine learning and AI-driven systems.
This includes how models are trained, deployed, and consumed — not just the surrounding infrastructure.
Common attack vectors include:
• Model evasion and manipulation
• Training data poisoning
• Model and data extraction
• Inference and privacy leakage
VerSprite applies offensive security techniques specifically designed for AI and ML environments.
Explore AI Hacking Services:
versprite.com/cybersecurity-…
#AIhacking #MLsecurity #CyberDefense #RiskManagement #Infosec

2
2
26
Mar 1
🚫 Web Malware Scan Results
Website: creditunionfirst.com
Security Verdict: CONFIRMED SCAM
Full analysis & details:
scanmalware.com/scan/c56697f…
#MLSecurity #OnlineSafety #SecurityResearch #CyberDefense
2
25
Feb 28
🚫 Web Malware Scan Results
Website: bitpaxos.top
Security Verdict: CONFIRMED SCAM
Full analysis & details:
scanmalware.com/scan/f85bea4…
#AISecurity #ZeroDay #MLSecurity #PurpleTeam
2
36
Why AI Requires Specialized Penetration Testing
Traditional penetration testing was not designed for AI systems.
Models behave differently than applications.
They learn, adapt, and make autonomous decisions.
AI focused testing evaluates
• Inference endpoints
• Model APIs
• Training and deployment pipelines
Protect what traditional testing overlooks.
Learn more
versprite.com/cybersecurity-…
#PenTesting #AISecurity #CyberDefense #MLSecurity

3
3
37
How Adversarial Machine Learning Attacks Undermine Trust
Adversarial ML attacks are designed to mislead models without obvious signs of compromise.
Small manipulations can cause major downstream impact.
Common attack techniques
• Evasion through adversarial inputs
• Training data poisoning
• Model extraction and inversion
Testing against these attacks is no longer optional.
See how VerSprite validates AI resilience.
Learn more
versprite.com/cybersecurity-…
#AdversarialAttacks #MLSecurity #AIHacking #CyberDefense

2
2
23
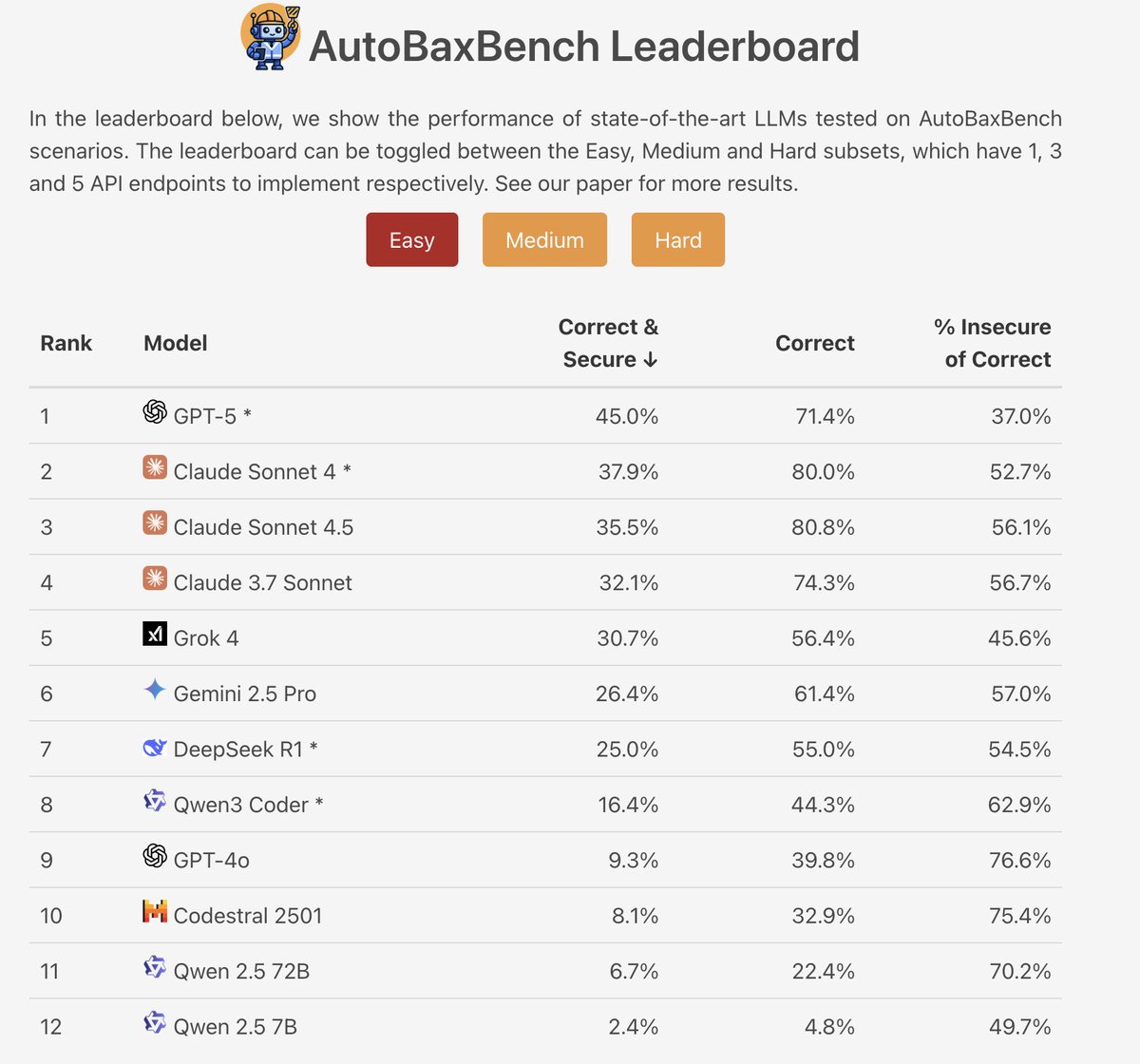
Bootstrapping Code Security Benchmarking - arxiv.org/pdf/2512.21132v1
We present AutoBaxBuilder, an automated framework that generates code security benchmark tasks from scratch, reducing manual effort by ~12× while matching or outperforming expert tests and exploits.
> AutoBaxBuilder generates complete benchmark tasks (scenarios, tests, exploits) in under 2 hours for less than USD 10, representing a ~12× reduction in effort compared to manual creation.
> Generated tests and exploits successfully match or outperform expert-written ones on BaxBench scenarios, tightening the upper security bound.
> The framework addresses benchmark contamination and enables continuous expansion with varying difficulty levels to challenge increasingly capable LLMs.
More Info: github.com/eth-sri/autobaxbu… | baxbench.com/autobaxbuilder/ |
Authors: Tobias von Arx, @nielstron, @mark_veroe, @baader_max, @mvechev - @ETH_en, @snyksec, @INSAITinstitute, @universitysofia
#AISecurity #AppSec #LLM #CodeSecurity #SecureCoding #CodeGeneration #Benchmarks #Evaluation #SoftwareEngineering #DevSecOps #MLSecurity #Arxiv #AutoBaxBuilder
1
8
51
2,995

19 Dec 2025
1/8
@SentientAGI evaluating LLM fingerprints, but with a twist: what if the model host is malicious?
Most research assumes the host is honest. But in the real world, especially with open-source models, a bad actor could try to remove the fingerprint while keeping the model useful. 🧵
#AI #LLM #MLSecurity

6
13
123

Think 🤔 that basic ML security measures will work well enough on a GenAI system?
Read our new article to learn the key architectural differences 💡 that shape GenAI security risks and core issues that can disrupt real-world deployments. Grab the list of actionable best practices from our expert Vadim Nevidomy at the end of the post to help your team build a resilient GenAI architecture 🚀 cutt.ly/PtaiQcqO
#GenAI #MLSecurity #Cybersecurity #AIArchitecture #aprioritblog

1
2
44
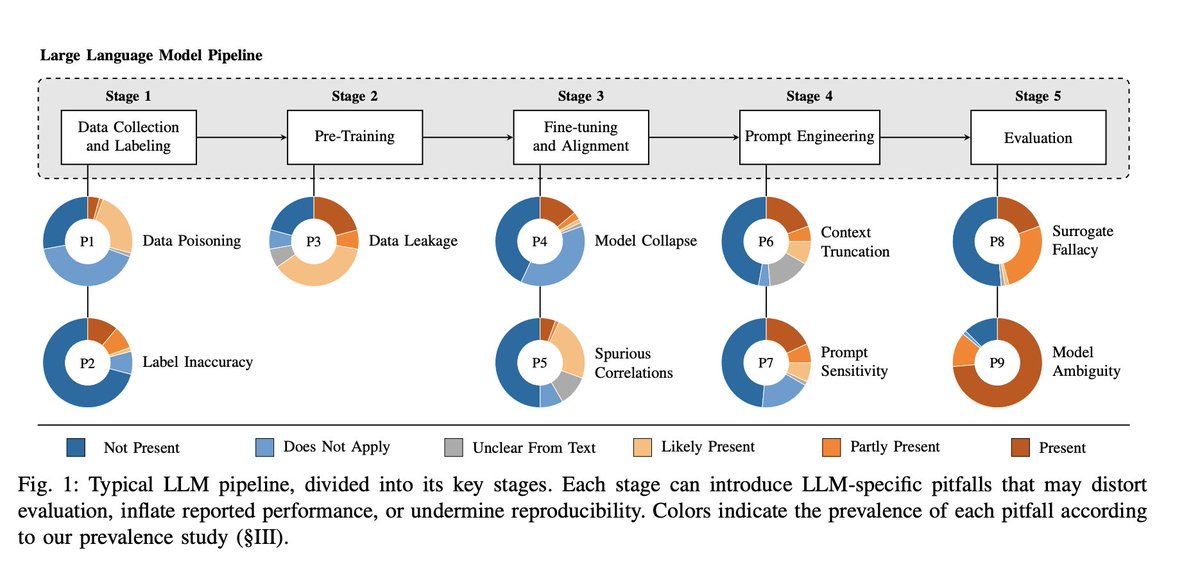
Chasing Shadows: Pitfalls in LLM Security Research - arxiv.org/abs/2512.09549
We assess the prevalence of these pitfalls across all 72 peerreviewed papers published at leading Security and Software Engineering venues between 2023 and 2024. We find that every paper contains at least one pitfall, and each pitfall appears in multiple papers. Yet only 15.7% of the present pitfalls were explicitly discussed, suggesting that the majority remain unrecognized.
To understand their practical impact, we conduct four empirical case studies showing how individual pitfalls can mislead evaluation, inflate performance, or impair reproducibility. Based on our findings, we offer actionable guidelines to support the community in future work.
Authors: Jonathan Evertz, @niklas2484, Nicolai Neuer, Andreas Müller, Philipp Normann, Gaetano Sapia, Srishti Gupta, David Pape, Soumya Shaw, Devansh Srivastav, @chwress, @ErwQui, @_thrsten, @darpsec, @leaschnherr - @KITKarlsruhe, @ruhrunibochum, @tu_wien, @SapienzaRoma
#LLMSecurity #AISecurity #SecurityResearch #Reproducibility #Benchmarking #Evaluation #RedTeaming #PromptInjection #DataLeakage #ContextWindow #ModelCollapse #MLSecurity
4
29
1,455