
Feb 27
60 Seconds to 500 Milliseconds. One Data Model Change. 🎯
I love data modeling. Creating shapes that map to access patterns as they grow in cardinality — it's a multi-dimensional puzzle I visualize like an Escher drawing in my head. Projections intersecting across planes.
Today that puzzle clicked on a call with a major financial services customer. And it proved something I've been saying for years.
The Problem 📊
Large advisory platform. Thousands of advisors managing investor portfolios. MongoDB performing well for 90% of queries — entity reads, profile lookups, transaction histories. Classic document strengths. ✅
But the last 10% was killing them. 💀
Advisor landing pages needed Top 50 investor lists sorted by book value. Many-to-many relationship. Sort attribute lives on the investor document.
Every NoSQL database does something similar:
→ $lookup across collections (full materialization)
→ Runtime $sort on unindexed attribute
→ Fetch thousands of docs to return 50
Result: 60 seconds for a landing page. 🐌
The Vendor Fix 🔧
Pre-compute and embed Top N book values in the advisor doc. Background process watches book value changes, updates materialized views on advisor documents. Add a sortable index for landing pages on the advisor doc.
That solves for read latency. ✅
The problem? Book values change constantly throughout the trading day. One investor change triggers hundreds of advisor updates. Write amplification compounds. Views are never consistent. In financial services, "eventually consistent" sort queries aren't acceptable. ❌
The Hybrid Model 💡
@Oracle 26ai. Documents where documents excel. Relations where joins are needed. Same transaction.
Create a relational mapping table between the JSON collections and project book_value from the investor doc as a relational column:
CREATE INDEX idx_adv_book ON advisor_investor_map (advisor_id, book_value DESC);
Pre-sorted composite B-tree index. The Top 50 query becomes an index-only scan. No aggregation pipeline. No runtime sort. O(log N) 50 sequential reads. ⚡
The kicker? ACID consistency between the relational column and the document attribute. Same transaction. Same commit.
No CDC pipeline. No change streams. No background processing.
60 seconds → 500ms. 120x improvement. 🚀
Zero pre-computation. Zero eventual consistency. Zero write amplification.
No other database has these primitives. Native JSON collections relational tables ACID spanning both one cost-based optimizer. Not MongoDB. Not Postgres. Not DynamoDB.
That's not philosophy. That's architecture. And today it turned a 60-second nightmare into a sub-second response. On a whiteboard. In one session.
The 90/10 problem is real. So is the solution. 🎯
#Oracle #Oracle26ai #HybridModeling #DataModeling #JSON #NoSQL #MongoDB #FinancialServices #DatabaseArchitecture
#UnifiedModelTheory #Performance #ACID #DocumentDatabase
8
3,777
Jan 8
I just proved MongoDB's binary format is up to 529x slower than @OracleDatabase. 🔥
That is NOT a typo. Five hundred twenty-nine times slower.
Here's the thing about BSON (MongoDB) vs OSON (Oracle) that nobody talks about:
📍 BSON scans field names sequentially. O(n).
📍 OSON hashes and jumps to offsets. O(1).
Computer Science 101. I had talked about it, but nobody had benchmarked it. Until now.
I built DocBench — an open-source framework that isolates pure field access performance. No network noise. No server overhead. Just raw binary format traversal.
The results? 📊
→ Position 1 in a document? OSON 2.5x faster
→ Position 100? OSON 62x faster
→ Position 1000? OSON 529x faster
That's not a rounding error. That's algorithmic complexity playing out exactly as the theory predicts.
But here's what really got me: 🤔
BSON was designed in 2007-2009 by startup founders racing to ship. Good enough for the moment.
OSON was designed in 2017 by database research veterans with nearly 100 published papers — who had the luxury of learning from BSON's limitations.
Hindsight is a powerful engineering tool.
The full article breaks down:
✅ Client-side field access benchmarks (71x OSON advantage overall)
✅ Server-side update tests (OSON wins 22 of 25 tests)
✅ The offset recalculation penalty MongoDB pays on updates
✅ Where MongoDB actually wins (spoiler: large homogeneous arrays)
✅ Why your Document class is hiding the O(n) cost from you
The benchmark is MIT-licensed. The methodology is documented. The results are reproducible.
Don't take my word for it. Prove it to yourself. 💪
linkedin.com/pulse/why-binar…
---
#MongoDB #Oracle #BSON #OSON #JSON #DatabasePerformance #Benchmarking #OpenSource #DataEngineering #SoftwareArchitecture #DocumentDatabase #Performance #DeveloperExperience #TechDebt #DatabaseInternals

2
8
46
5,515

27 Sep 2024
🎙️ Announcing Our Next Webinar Speaker: Oskar Dudycz!
🔗 documentdatabase.org/event/p…
Join us as Oskar Dudycz, an experienced .NET architect, open-source contributor, and Event Sourcing expert, presents "Pongo: Using PostgreSQL as a Strongly-Consistent Document Database."
🧑💻 With over 15 years of experience, Oskar has worked extensively with Event Sourcing and CQRS, helping teams design scalable, efficient systems. As an active speaker and passionate advocate for the developer community, Oskar regularly shares his insights through open-source projects and thought leadership.
#Webinar #PostgreSQL #DocumentDatabase #EventSourcing #OpenSource #CQRS #DatabaseEngineering
6
828

28 Feb 2024
Examine the Aerospike #DocumentDatabase solution brief: Real-time and scalable from GB to PB, featuring support for #JSON documents and #Java programming, inclusive of JSONPath query support:
aerospike.com/resources/solu…
#Aerospike #RealTimeData
6
4
75

9 Aug 2023
🌱 Just explored the MongoDB basics! 🍃 It's a scalable, flexible document database with powerful querying & indexing. #mongodb #databasics #nosql #documentdatabase #learnprogramming

ALT 🌱 Delve into the remarkable realm of MongoDB, a cutting-edge document database that seamlessly melds boundless scalability with unparalleled querying prowess. Embark on a journey where data finds its home within supple structures, revealing a tapestry of possibilities that enrich efficiency and ignite innovation. 🍃 Traverse the landscape where information thrives, transforming into insights, and where the interplay of flexibility and performance sets the stage for a symphony of data-driven achievements. #MongoDBExcellence #FlexibleDataSolutions #UnleashInnovation
1
37

23 Jun 2023
Wonder why @MongoDB is so successful? @dittycheria sums it up right here - Streamlining Data Workflows: Enhancing #developer Productivity with a #Data Platform video.cube365.net/c/944588 #developerlife #dataanalytics #documentdatabase #devtools #developerdataplatform #datamanagement #productivity #techindustry @furrier @dittycheria
1
4
706
11 May 2023
🔹 Were you waiting for the second part? You can read it here ⬇️
documentdatabase.org/databas…
#DocumentDatabase #DatabaseManagement #DocumentModels #RelationalToDocument
2
5
814
28 Apr 2023
Missed our recent webinar on comparing CosmosDB, DocumentDB, MongoDB, and FerretDB for your tech stack?
Don't worry, the recording is now available!
Click the link to learn from our experts and make an informed decision: youtube.com/live/icgSuHpivkA…
#documentdatabase #techstack

1
3
488

19 Oct 2022
An excellent introduction to document-oriented data in @aerospikedb. Get to know nested CDTs and understand data modeling, in general, for a document database.
#aerospike #rbttech #database #documentdatabase #multimodel #data #software youtu.be/7rVk0WCRJtQ

13
5

29 Sep 2022
@InfStones took advantage of #autonomousJSON to build a low-latency query service over billions of #blockchain records. social.ora.cl/6017MwZAV
Discover why Autonomous JSON Database is much more than a #documentdatabase at #OCW.
Register at social.ora.cl/6018MwZAn

1
1
27 Sep 2022
@InfStones took advantage of #autonomousJSON to build a low-latency query service over billions of #blockchain records. social.ora.cl/6011Mkpol
Discover why Autonomous JSON Database is much more than a #documentdatabase at #OCW. Register at social.ora.cl/6015MkpoU


15 Jul 2022
#relationalDatase vs #documentDatabase
Which one do u prefer and why?
#developers #javascript #typscript #angular #php #programming #programmer
0%
MySQL
100%
NoSQL
0%
GraphSQL
1 votes • Final results
1
1
1

#RavenDB is a fully transactional #NoSQL #DocumentDatabase that implements both CP and AP guarantees at different times. @ayende & @wesreisz discuss those CP/AP distributed systems challenges, the choice of implementation language (#csharp), & more: bit.ly/3MQ3a5y
#InfoQ

1
2

With #cybercrime costing the global economy trillions every year, improperly configured #security can spell the end of your business.
See how RavenDB keeps things simple and safe here: buff.ly/3oXJbZK
#NoSQL #DocumentDatabase #DatabaseSecurity #Encryption

2
2
RavenDB has provided fully #ACID multi-document transactions since 2010. #MongoDB only started to support them in 2018. That headstart is why they have to warn you about performance costs for ACID transactions while we don't.
#NoSQL #DocumentDatabase #DistributedDatabase

3
4

18 Nov 2021
Here's a mini presentation I produced providing an overview on: What #VirtuosoRDBMS is & why it is important?
Check it out 👇
virtuoso.openlinksw.com/data…
#LinkedData #HyperData #KnowledgeGraph #GraphDatabase #DocumentDatabase #RDBMS #SQL #SPARQL #ODBC #JDBC #DataConnectivity #ABAC
2
1
3
5 Nov 2021
Here is a mini presentation providing an overview on
What #VirtuosoRDBMS is & why it is important?
#LinkedData #HyperData #KnowledgeGraph #GraphDatabase #DocumentDatabase #RDBMS #SQL #SPARQL #ODBC #JDBC #DataConnectivity #ABAC #ExplainableAI
Check it out 👇👇👇
1
3
3

21 Oct 2021
The unique feature of the #Web #Database lies in the role of hyperlinks as super-keys :)
#DataConnectivity #SuperKey #LinkedData #DBMS #DocumentDatabase #GraphDatabase #RDBMS #HyperData #Hyperlink #DSN
1
1
21 Oct 2021
The #Web is the largest #DocumentDatabase on earth, bar far!
Even better, courtesy of #LinkedData principles, it's also the largest pure #RDBMS on earth -- but without conventional #DBMS #DataConnectivity shortcomings!
#Web30 #KnowledgeGraph #SemanticWeb #SPARQL #SQL #SPASQL
21 Oct 2021

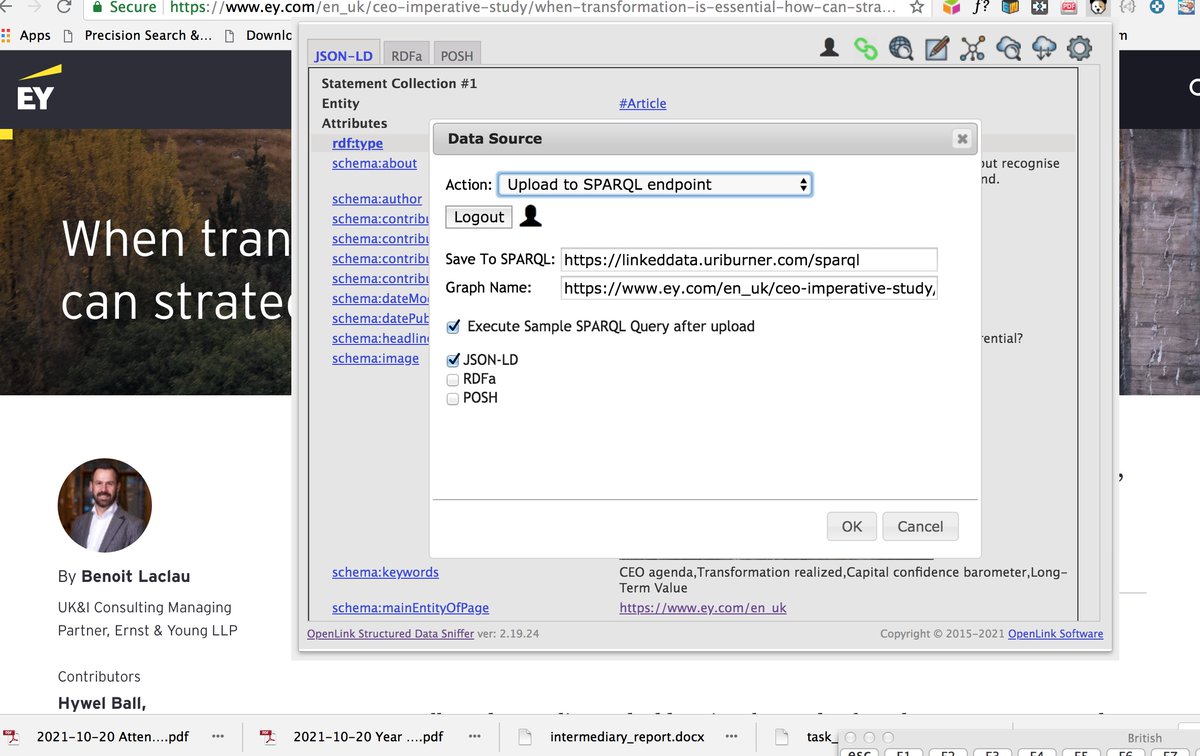
Additionally using the @OpenLink browser ext.
@datasniff create a #SPARQL query using the
@EYnews article as the #DataSource , no coding required just select from "Upload SPARL Endpoint"!
Query Results :
WHERE {
?s a ?o .
FILTER (CONTAINS(STR(?o),'schema'))
}
GROUP BY ?o
ORDER BY DESC (?count)
LIMIT 50 &format=text/x-html tr">linkeddata.uriburner.com/spa…
Further findings in exploration journey 👇

1
3

23 Sep 2021
Find out what the @OpenLink Data Junction Box is about and why is it important, in our Weekly Update!
community.openlinksw.com/t/p…
#LinkedData #HyperData #RDF #SemanticWeb #KnowledgeGraph #DataConnectivity #DBMS #RDBMS #DocumentDatabase #KnowledgeGraph #ODBC #JDBC #SQL #SPASQL
1
3
5