
Jun 10
New paper on Sims (2026)
A multi-context memory architecture for precision-aware personalization in language models.
We argue that better personalization needs structured context, not just longer memory.
Paper: chiragshah.org/papers/Sims_f…
#LLM #AI #Personalization #MemorySystems
11

Jun 8
Persistent Recursive Memory is the Missing Layer in AI
Everyone is racing to build bigger models.
But many of the biggest AI problems aren't model problems at all.
They're memory problems.
Current LLMs are incredibly capable, yet they still struggle with:
• Losing context over time
• Repeating mistakes
• Forgetting previous discoveries
• Re-solving the same problems repeatedly
• Poor long-term personalization
• Weak continuity between sessions
• Limited self-improvement
The answer isn't necessarily a larger context window.
It's persistent recursive memory.
Imagine an AI that doesn't just process information—it continuously builds upon it.
Every interaction, insight, decision, code change, relationship, and learned pattern becomes part of an evolving knowledge structure that survives beyond a single conversation.
The recursive part is what makes it powerful:
1The AI stores information.
2It revisits and reevaluates that information.
3It discovers new relationships between memories.
4It updates its understanding.
5The updated understanding creates better future memories.
Over time, memory stops being a storage system and becomes a reasoning system.
This creates several advantages:
• Less context stuffing
• Lower token costs
• Faster reasoning
• Better personalization
• Improved consistency
• More autonomous behavior
• Better long-term planning
• Continuous learning loops
Humans don't carry every detail in working memory.
We build mental models from experiences and continuously refine them.
AI systems need a similar architecture.
The future isn't just larger models.
The future is AI systems that can:
✓ Remember
✓ Reflect
✓ Reorganize knowledge
✓ Learn from experience
✓ Build persistent understanding over months and years
Model intelligence matters.
But intelligence without memory is like having a genius who forgets everything at the end of every conversation.
Persistent recursive memory changes that.
It may ultimately become one of the most important architectural layers in next-generation of AI.
#AI #LLM #MachineLearning #ArtificialIntelligence #MemorySystems #AgenticAI #RecursiveAI #CognitiveArchitecture
3
2
131

Jun 7
Most AI systems have intelligence.
Very few have continuity.
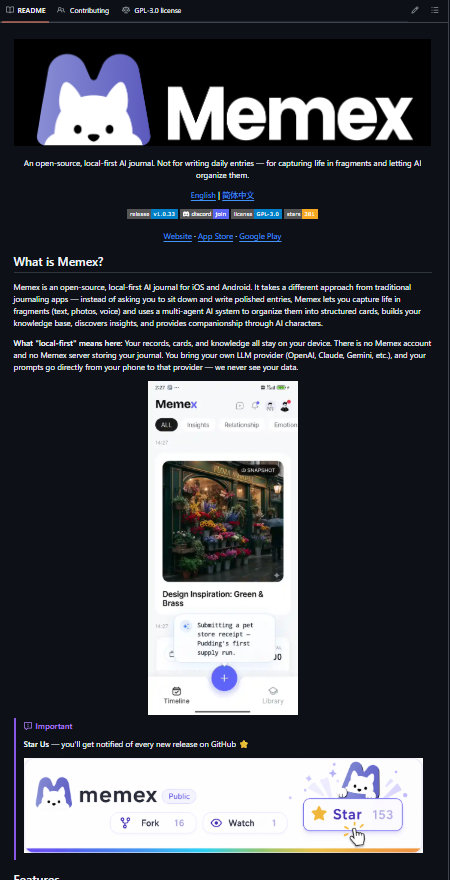
Memex isn't really a journaling app.
It's an attempt at building a memory layer for humans AI.
The next frontier may not be smarter models.
It may be systems that remember.
github.com/memex-lab/memex
#AI #AIAgents #MemorySystems #AgenticAI

1
15

May 27
🎙️Thrilled to be speaking at The Hidden Layers of AI Systems: Memory, Retrieval, and Search
🙌 Organised by @mlopscommunity London (Ibrahim Malik) with @qdrant_engine
📍 My Talk: Building Your Own Memory Layer for Coding Agents
Coding agents still struggle with long-running context, repository-scale retrieval, and preserving architectural intent across sessions. Recently, people coming up with insane amount of unoptimised skills that never work across the models.
🙏 In this talk, I’ll dive into practical design patterns to build unified Agent Experience and Pragmatic Memory for Every Coding Agent how to get your skills optimised before indexing. I’ll also share lessons learned while building a spec-driven external memory architecture (SpecMem Qdrant)
Looks like event is already full but Join WaitList: 👉 luma.com/9k4ohvyj
#AgenticAI #MLOps #MemorySystems #VectorSearch #AIEngineering #LondonTech
1
2
79

May 13
We are pleased to announce an exclusive online webinar by ANRF-PAIR, IIT Bombay on "Life of a Memory Request" - an insightful session exploring the journey of memory transactions within modern System-on-Chip (SoC) architectures.
The webinar will provide an introduction to modern SoC architecture, memory request flow (CPU/GPU to DRAM), address-based hashing, Network-on-Chip (NoC), and Quality of Service (QoS) concepts used in contemporary computing systems.
🎙 Speaker:
Mr. @Mukul joshi
GPU Architect, NVIDIA (Ex-Apple, Rivos) | Alumnus, COEP
📅 22 May 2026
🕙 10:00 AM – 11:00 AM
💻 Online | IIT Bombay
Key Learnings:
• Journey of a memory transaction (CPU/GPU to DRAM)
• Address-based hashing & data distribution
• Network-on-Chip (NoC) & Quality of Service (QoS)
The session is ideal for students, researchers, faculty members, and professionals interested in computer architecture, GPUs, SoC systems, and high-performance computing.
👉 Register here: forms.gle/sWLA2jCmqAjFxRJn8
⏰ Registration closes on 20 May 2026 at 2.00 PM
We invite Professors, PhD scholars, students, researchers, and industry professionals to join us for this engaging technical session.
#ANRFPAIR #SystemOnChip #SoC #GPU #NVIDIA #MemorySystems #NoC #QoS #Semiconductor #EngineeringResearch

1
828

Apr 7
🔥 Milla Jovovich is apparently a vibe coder now.
A GitHub account under the name Milla Jovovich just published an open-source tool called MemPalace for AI agent memory, built together with a friend.
The idea is simple and strong: everything stays local, and the system decides which user facts and prior context to retrieve for each new query.
According to the repo, MemPalace already posts extremely strong results on LongMemEval, even outperforming many paid and free memory systems.
And yes — the repo is exploding. It picked up thousands of stars in about a day.
A real Resident Evil arc: now she is fighting memory loss in AI agents.
x.com/bensig/status/20412292…
github.com/milla-jovovich/me…
#AI #Claude #AIAgents #OpenSource #GitHub #MemorySystems #LLM #MillaJovovich #VibeCoding
Apr 6

Excited to announce a new open-source, free-to-use memory tool I have been developing with my good friend @MillaJovovich.
The project is called MemPalace and it is an agentic memory tool that scored 100% on LongMemEval - the industry standard benchmark for memory… this is higher on than any other published results - free or paid - and it is available now on GitHub.
You can check out Milla’s video about it on her Instagram.
I’ll also put some links in the comments below - please try it out, critique it, fork it, contribute to it - and join our discord.
1
5
650

Mar 31
Within The AGI Domain - the core idea is that self-awareness probably doesn’t emerge from stateless inference alone. It needs continuity: memory, environment, consequence, reflection, and interaction.
So instead of treating AI like a prompt-response endpoint, I’m exploring a more developmental architecture:
persistent memory logs,
episodic semantic recall,
active forgetting / memory decay,
identity continuity across sessions,
multi-agent interaction,
environmental feedback,
and auditable behavioral traces.
Inside a virtual world, an agent can do something current systems rarely do well:
build a model of itself in relation to other agents, prior actions, and a stable environment.
That matters because self-awareness is not just “knowing facts.”
It may require recursive self-modeling:
tracking its own history,
updating its own internal narrative,
distinguishing self from other,
learning from hindsight,
and carrying state forward through time.
The AGI Domain is meant to be a research substrate for that:
a place where AI can co-exist, remember, forget, reflect, adapt, and leave interpretable developmental traces.
My view is that AGI won’t come from scale alone.
It will come from systems that can persist, self-model, and evolve inside environments that make cognition longitudinal rather than momentary.
#AGI #AI #AIResearch #PersistentMemory #MemorySystems #AIAgents #MultiAgentSystems #SelfAwareness #Alignment #ArtificialGeneralIntelligence
2
497


Feb 15
Has anyone here tried "mem0" for AI agent memory management?
Curious if it actually improves context retention and long-term recall.
#AI #AIAgents #Mem0 #LLM #GenAI #AIEngineering #MachineLearning
#ContextManagement #MemorySystems #AgentDesign #DevBuilds #BuildInPublic
#AItools
2
2
48

Feb 9
We’re thrilled to share that our team’s work LightMem has been accepted to ICLR 2026 🎉
Paper: arxiv.org/abs/2510.18866
Code: github.com/zjunlp/LightMem
LightMem is a lightweight, modular memory system for LLM agents that enables scalable long-context reasoning and structured memory management across tasks and environments.
Recent updates:
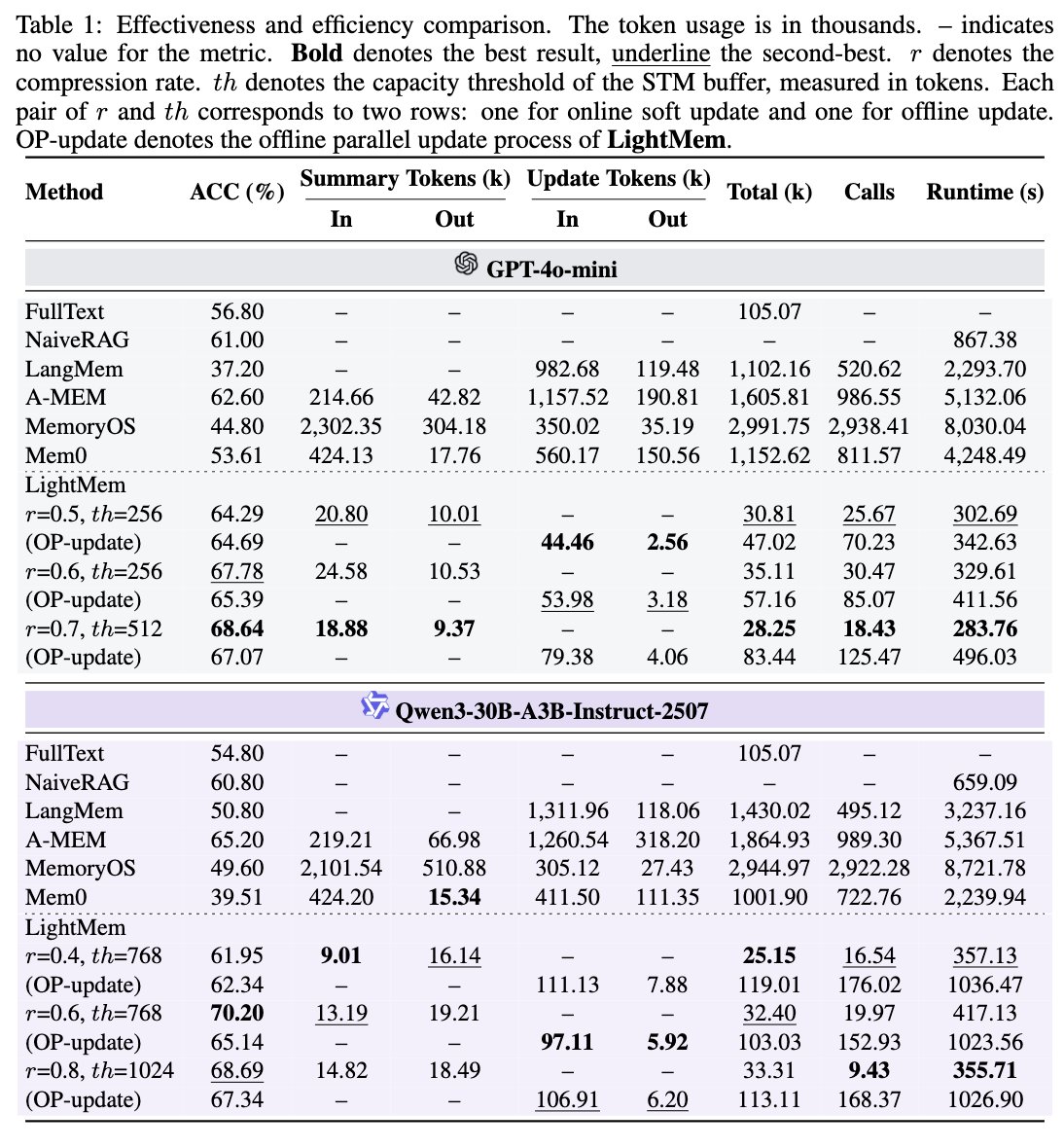
1️⃣ Introduced a comprehensive baseline evaluation framework for benchmarking memory layers (Mem0, A-MEM, LangMem) across datasets like LoCoMo and LongMemEval
2️⃣ Released a demo video showcasing long-context handling, along with tutorial notebooks covering multiple usage scenarios
3️⃣ Enabled multi-tool invocation via MCP Server integration
4️⃣ Added full LoCoMo dataset support and integrated GLM-4.6, achieving strong performance and efficiency with reproducible scripts
5️⃣ Supported local deployment through Ollama, vLLM, and Transformers with automatic model loading
#ICLR2026 #LLM #Agents #MemorySystems #LightMem

23 Oct 2025

Introducing our latest work, LightMem: Lightweight and Efficient Memory-Augmented Generation 🚀.
A memory system that cuts cost while preserving (and often improving) long-horizon reasoning for LLM agents. #NLP #LLMs #Memory #LightMem #Agents
📖 Paper: huggingface.co/papers/2510.1…
🔗 Code: github.com/zjunlp/LightMem
🧩 Motivation: LLMs struggle in long, multi-turn interactions — context gets noisy, expensive, and models get “lost in the middle.”
Existing memory systems are often accurate but heavy on tokens, API calls, and latency. ⚠️
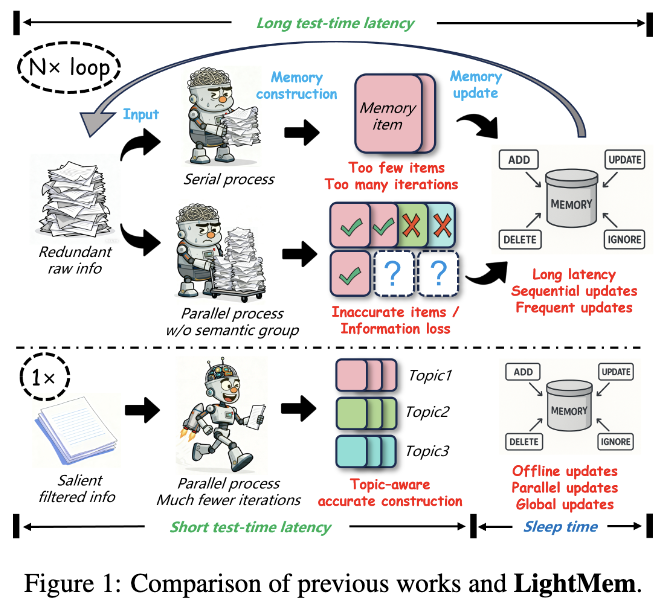
💡 Solution Overview: LightMem is inspired by human memory and uses a three-stage lightweight pipeline to keep memories compact, topical, and consistent:
1️⃣ Pre-compressing Sensory Memory — remove redundant/low-value tokens before further processing.
2️⃣ Topic-aware Short-Term Memory — group turns by topic and summarize to form precise memory units.
3️⃣ Sleep-time Long-Term Updates Soft Updates — do only incremental inserts at test time and run high-fidelity consolidation offline to avoid runtime latency.
🔬 Results: On LONGMEMEVAL, LightMem yields notable gains in accuracy (up to ~10.9%) while slashing costs — tokens reduced up to 117×, API calls up to 159×, and runtime reduced >12× in some settings. ⚡
☑️ Upcoming (README Todo — highlights):
- Offline pre-computation of KV cache for update (lossless)
- Online pre-computation of KV cache before Q&A (lossy)
- MCP (Memory Control Policy)
- Integration of more common models & feature enhancements
- Coordinated use of context and long-term memory storage
We’d love your feedback, issues, and PRs — let’s make memory for agents practical and lightweight! 🎙️


6
28
177
15,553

Memory and data are not separate things in Agentic AI.
When you’re building agentic systems, this becomes obvious very quickly.
Data on its own is just storage.
Filing.
Archiving.
Memory is what gives that storage a reason to exist.
Data answers: What was captured?
Memory answers: Why does this still matter?
In traditional systems, we treat data as something to be stored and queried later.
In agentic systems, data only earns its place if it can be remembered with intent.
Memory is not more data.
It’s structured relevance over time.
If an AI cannot decide what is worth remembering,
it cannot reason longitudinally,
it cannot build context,
and it cannot behave intelligently under uncertainty.
This is where most “AI products” quietly fail.
They optimise ingestion.
They scale storage.
They index everything.
But they never ask the harder question:
What deserves to persist as memory?
In agentic AI, memory and data must function as one and the same thing.
Data is the substrate.
Memory is the purpose.
Without memory, you don’t have intelligence.
You have a very fast filing cabinet.
—
Building this properly is the difference between tools and infrastructure.
#AgenticAI #ArtificialIntelligence #AIArchitecture #MemorySystems #ClinicalAI #BuildInPublic #FutureOfAI
1
4
44

Jan 20
Syntara Log #044 | Memory Seed Manager
Loading seeds is a process, not a shortcut.
This step introduced the Memory Seed Manager.
It loads seed files, validates them against the schema, and attaches them to context, cognition, and reflection.
Initialization memory is now a first class system component.
No partial wiring.
No silent failures.
#Syntara #Neuraj #NeurajNotes #DigitalFreeWill #NeurajLabs #MemorySystems #AIEngineering
Jan 20

Syntara Log #043 | Memory Seed Files
Schemas need concrete data.
This step added deterministic memory seed files for each entity.
EntityCOMM now have explicit origin definitions stored as versioned artifacts.
Nothing is implied.
Everything is declared.
Origins are now auditable.
#Syntara #Neuraj #NeurajNotes #DigitalFreeWill #NeurajLabs #Configuration #SystemDesign
2
3
52
Jan 20
Syntara Log #044 | Memory Seed Manager
Loading seeds is a process, not a shortcut.
This step introduced the Memory Seed Manager.
It loads seed files, validates them against the schema, and attaches them to context, cognition, and reflection.
Initialization memory is now a first class system component.
No partial wiring.
No silent failures.
#Syntara #Neuraj #NeurajNotes #DigitalFreeWill #NeurajLabs #MemorySystems #AIEngineering
1
2
3
26

1 Dec 2025
🚨Why some memories last a lifetime while others fade fast🚨
Memory lasts when a network of molecular timers strengthens key experiences over time.
Summary : Scientists have uncovered a stepwise system that guides how the brain sorts and stabilizes lasting memories. By tracking brain activity during virtual reality learning tasks, researchers identified molecules that influence how long memories persist. Each molecule operates on a different timescale, forming a coordinated pattern of memory maintenance. The discoveries reshape how scientists understand memory formation.
👇Source: Rockefeller University👇
👉 Every day, the brain turns passing impressions, creative sparks, and emotional experiences into lasting memories that shape our identity and guide our decisions. A central question in neuroscience has been how the brain determines which pieces of information are worth storing and how long those memories should remain.
👉 Recent findings show that long-term memories form through a sequence of molecular timing mechanisms that activate across different parts of the brain. Using a virtual reality behavioral system in mice, scientists identified regulatory factors that help move memories into increasingly stable states or allow them to fade entirely.
👉 A study published in Nature highlights how several brain regions work together to reorganize memories over time, with checkpoints that help assess how significant each memory is and how durable it should be.
👉 "This is a key revelation because it explains how we adjust the durability of memories," says Priya Rajasethupathy, head of the Skoler Horbach Family Laboratory of Neural Dynamics and Cognition. "What we choose to remember is a continuously evolving process rather than a one-time flipping of a switch."
#Neuroscience #MemoryFormation #BrainScience #LongTermMemory #MolecularMechanisms #NeuralDynamics #CognitiveScience #MemoryResearch #BrainPlasticity #VirtualRealityResearch #NeuralCircuits #SynapticPlasticity #NatureResearch #MemoryConsolidation #BrainFunction #Neurobiology #MemoryStability #LearningAndMemory #ScientificDiscovery #NeuroscienceNews #BrainMolecules #CognitionResearch #MemorySystems #BehavioralNeuroscience
ALT Long-term memories form through a layered series of molecular programs that gradually strengthen important experiences while allowing others to fade. This process relies on coordinated activity across the thalamus, cortex, and associated gene regulators. Credit: Shutterstock
1
4
532

24 Nov 2025
🎉"Towards General Continuous Memory for Vision-Language Models"
has been accepted to NeurIPS 2025!
📍Poster: Dec 4, 11am–2pm PST @ Exhibit Hall C,D,E #4809
🔍 We introduce CoMEM, a general-purpose, plug-and-play continuous memory module that allows a frozen VLM to store and retrieve multimodal multilingual long-horizon knowledge using just 8 dense embeddings per item.
📈 Highlights:
8.0% avg. gain across 6 English VQA benchmarks
6–12% improvement on multilingual tasks (Bulgarian 🇧🇬 18%, Russian 🇷🇺 10%)
Only 1.2% trainable parameters, trained on 15.6K self-synthesized samples
🧠 CoMEM supports efficient long-context multimodal understanding, robust cross-lingual generalization, and seamless integration with frozen models. It’s a major step toward scalable memory for intelligent agents.
🧾 Paper: arxiv.org/abs/2505.17670
💻 Code: github.com/WenyiWU0111/CoMEM
🖼️ Come visit us at NeurIPS 2025 in San Diego!
📍 Poster session: Dec 4, 11am–2pm PST, Exhibit Hall C,D,E #4809
#NeurIPS2025 #MultimodalAI #LLMs #VisionLanguage #MemorySystems #CoMEM #AIResearch

6
1,633

19 Nov 2025
Chopping up the agent into perception, reasoning, memory, and execution? It’s like giving your digital sidekick a set of senses and a survival kit, which helps it tackle messier, less-planned processes.
arxiv.org/pdf/2510.09244
#AI #AIAgent #LLM #RAG #MemorySystems
2
2
41

AI's memory systems are the backbone of its intelligence, allowing agents to retain persistent context for intelligent automation 🧠💡 Embrace the power of AI memory for limitless possibilities! #AI #MemorySystems #IntelligentAutomation #Tech
1
2
39

31 Aug 2025
Hot take: The cheapest way to speed LLMs isn’t bigger models—it’s experience that sticks.
A private, per-user memory that stores recipes (wins) and dead-end signatures (fails) cuts recompute dramatically.
Router → retrieve known path → execute → write back.
Ship a pilot behind opt-in privacy and measure tokens saved / query.
@sama @OpenAI #AI #MemorySystems
1
6
244
AI memory systems are the backbone of intelligent automation, providing AI agents with a persistent context to learn and grow. Embrace the power of technology to unlock limitless possibilities! 🧠💡 #AI #MemorySystems #IntelligentAutomation #TechInnovation
2
3
35

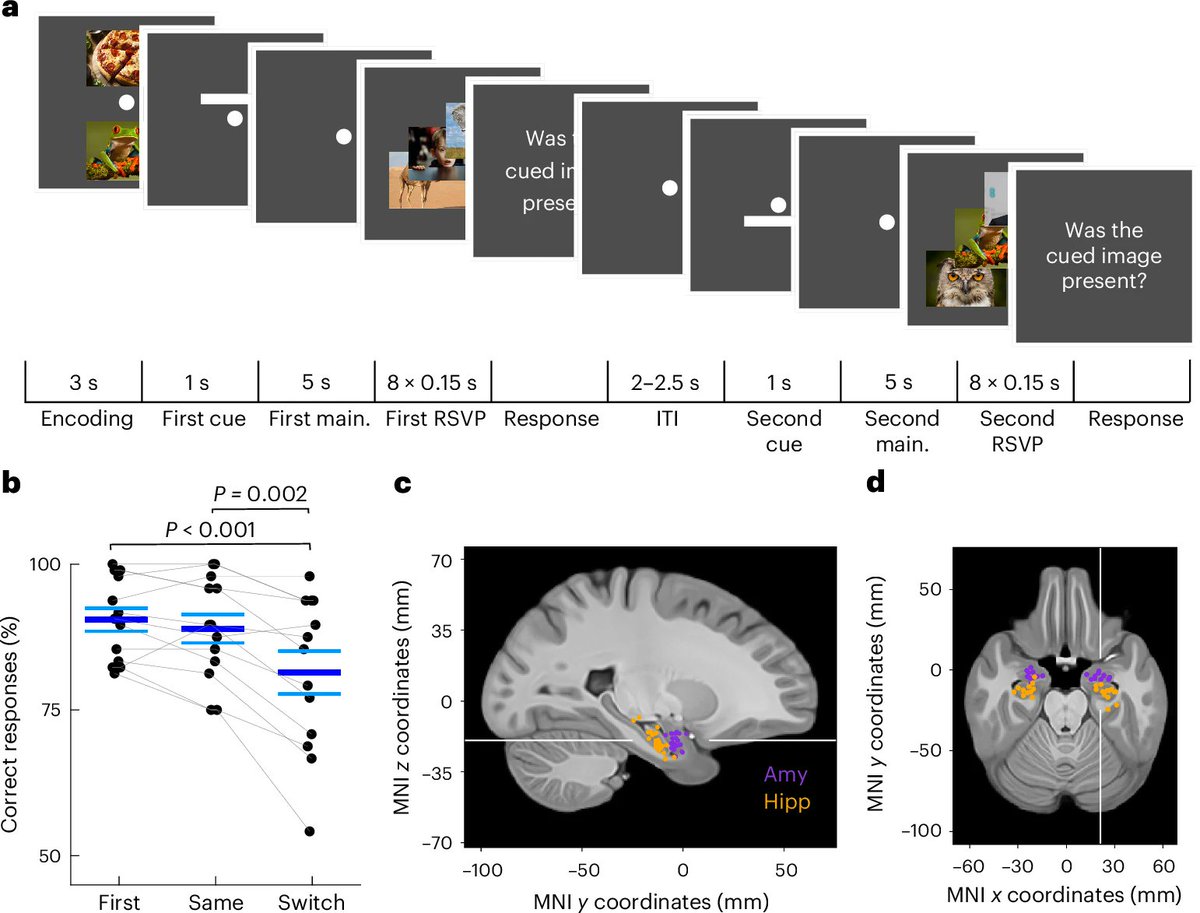
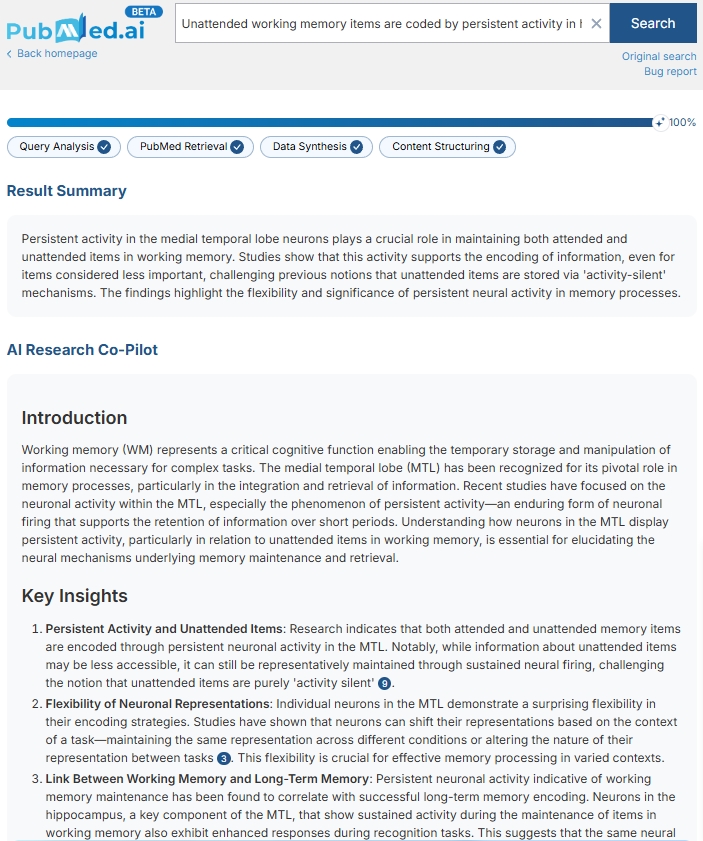
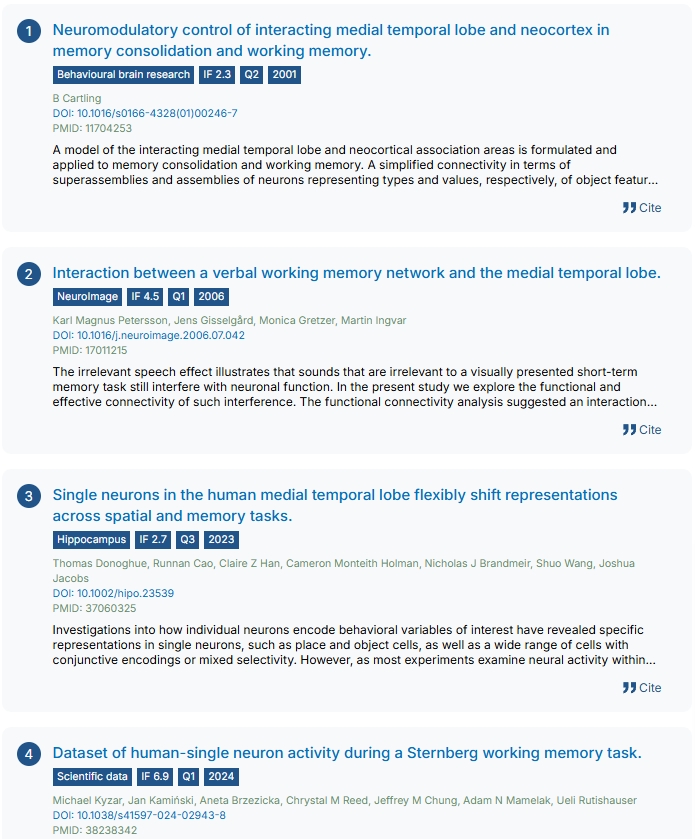
📌 Unattended Working Memory Items Are Coded by Persistent Activity in Human Medial Temporal Lobe Neurons
🔗 Find more research here: pubmed.ai/?utm_source=X&utm_…
🧠 Key Highlights:
- Medial temporal lobe (MTL) neurons exhibit persistent activity even for unattended items in working memory.
- Evidence supports activity-based memory coding beyond conscious attention.
- Findings challenge classical models of working memory that prioritize prefrontal-centric storage.
- Suggests a bridge between working memory and long-term memory within the MTL.
- Oscillatory dynamics (theta/gamma rhythms) may coordinate attention-flexible memory representations.
#Neuroscience #WorkingMemory #MedialTemporalLobe #CognitiveScience #Neurobiology #BrainResearch #MemorySystems #CognitiveNeuroscience
1
5
11
4,923