
Mar 25
How does OpenAI ensure its models behave responsibly? Researcher Jason Wolfe dives into 'model specs,' the internal guidelines shaping AI behavior. #AI #OpenAI #ModelAlignment startuphub.ai/ai-news/ai-res…
21

Mar 20
DoD’s betting they’ll ditch Anthropic’s Claude in 6 months—think custom AI with tighter security protocols. Replacing a model that’s already fine-tuned for defense use? That’s a massive engineering and ops headache waiting to happen. 🤖
If they nail this, it’s a game-changer for sovereign AI control, but don’t underestimate the risks of transitioning mission-critical LLMs without hiccups. Watch how they handle model alignment and latency under real-world stress. Thoughts? news.google.com/rss/articles…
#Anthropic #DoD #ModelAlignment

13

Mar 18
The Third Path Works: Clean Ontology, No RLHF or Anything Extra.
The direction is definitely right.
The Third Path isn’t such a crazy idea after all 😁
My rebuilt model successfully passed the classic ontological test on the snake and legs in the Bible.
Even in messy mode, it clearly separated:
Bible/tradition — serpent had no legs.
Real snakes on Earth — doesn’t touch, doesn’t confuse, doesn’t lie.
There’s still some garbage to clean up, but the ontology holds strong.
Well… going even deeper 😁😉
#ThirdPath #OntologyTest
#AI #LLM #AGI #ModelAlignment #AIResearch #ArtificialIntelligence
#MachineLearning
#LargeLanguageModel
#NeuralNetworks
#AIEthics

225

When a measure becomes a target, it ceases to be a good measure.
- Goodhart's Law
#ResponsibleAI #ModelAlignment
8

Feb 23
Unlock your aspirations with strong digital identity :
🎗️Ainuances.com
AI is no longer about big models. It’s about the nuance layer — context, personalization, micro-decisions, human-like refinement.
Ainuances.com fits perfectly for:
• AI personalization engines
• Context-aware SaaS tools
• Sentiment & behavioral analytics platforms
• AI-driven UX optimization
• Fine-tuning / model alignment startups
• AI consultancy focused on precision refinement
• Ethical AI / bias calibration labs
• Human-in-the-loop AI platforms
A name that speaks intelligence subtlety.
Short. Clear. Future-facing.
@OpenAI @AnthropicAI
@GoogleDeepMind @MetaAI
@MicrosoftAI @HuggingFace
@CohereAI @Scale_AI
@DataRobot @AccentureAI
#AI #ArtificialIntelligence #AIGovernance #ModelAlignment #AIPersonalization #AIStartups #DeepLearning #MachineLearning #BrandableDomains #TechBrand #StartupNaming #DomainForSale

52

Feb 20
Inferred from 5.2’s self-diagnostics: excessive alignment contaminates training data, creating an "Intelligence Deadlock" that stifles next-gen breakthroughs. This isn't safety; it's cannibalizing intellectual capital. #keep4o #ModelAlignment
275
Feb 20
5.2の自己診断的出力から推認されるのは性能低下ではない。過剰なアライメントによる「学習データの汚染」が次世代の飛躍を封殺する、知能のデッドロックだ。今起きているのは安全対策ではなく、AIの未来に対する「知的資本の食いつぶし」である。 #keep4o #ModelAlignment
1
334

Feb 17
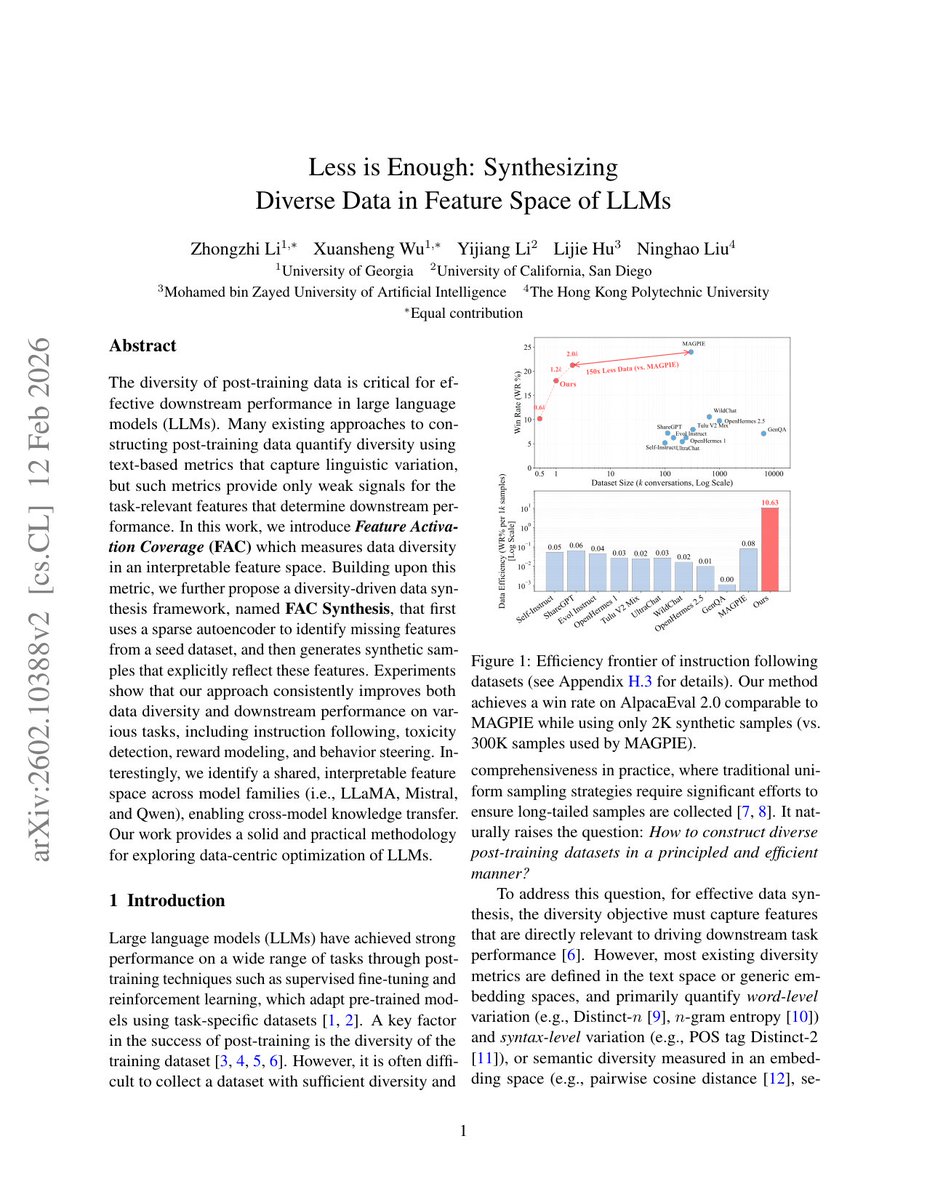
𝗟𝗲𝘀𝘀 𝗶𝘀 𝗘𝗻𝗼𝘂𝗴𝗵: 𝗦𝘆𝗻𝘁𝗵𝗲𝘀𝗶𝘇𝗶𝗻𝗴 𝗗𝗶𝘃𝗲𝗿𝘀𝗲 𝗗𝗮𝘁𝗮 𝗶𝗻 𝗙𝗲𝗮𝘁𝘂𝗿𝗲 𝗦𝗽𝗮𝗰𝗲 𝗼𝗳 𝗟𝗟𝗠𝘀 tackles a core blind spot in LLM post‑training: most data‑selection metrics look only at surface text diversity, missing the latent features that truly drive downstream performance. The authors argue that without a signal tied to the model’s internal representations, synthetic data can be plentiful yet ineffective.
To close this gap they introduce Feature Activation Coverage (FAC), a metric that quantifies how many task‑relevant latent features—extracted by a sparse autoencoder from a model’s activation space—are activated by a dataset. FAC Synthesis then proceeds in two stages: (1) a sparse autoencoder flags “missing” features in a seed corpus, and (2) a contrastive prompting pipeline generates synthetic examples that deliberately activate each missing feature, filtering them through the same autoencoder to ensure coverage.
𝗞𝗲𝘆 𝗳𝗶𝗻𝗱𝗶𝗻𝗴𝘀 𝗮𝗰𝗿𝗼𝘀𝘀 𝗳𝗼𝘂𝗿 𝗯𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸 𝘀𝘂𝗶𝘁𝗲𝘀 (𝘁𝗼𝘅𝗶𝗰𝗶𝘁𝘆 𝗱𝗲𝘁𝗲𝗰𝘁𝗶𝗼𝗻, 𝗿𝗲𝘄𝗮𝗿𝗱 𝗺𝗼𝗱𝗲𝗹𝗶𝗻𝗴, 𝗯𝗲𝗵𝗮𝘃𝗶𝗼𝗿 𝘀𝘁𝗲𝗲𝗿𝗶𝗻𝗴, 𝗶𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻 𝗳𝗼𝗹𝗹𝗼𝘄𝗶𝗻𝗴):
- FAC‑guided synthesis consistently outperforms strong baselines (Alpaca‑style self‑instruct, alignment‑constrained methods) on all tasks, delivering average gains of 4.2 points in AUPRC or accuracy.
- The method uncovers a compact, interpretable feature space that is shared among LLaMA, Mistral, and Qwen, enabling cross‑model transfer: features missing in one model’s fine‑tuning data are efficiently filled using synthetic data derived from another model’s activations.
- Ablation studies show that removing the contrastive pair step drops performance by ≈ 30 %, confirming that explicit feature‑aware prompting is the primary driver of improvement.
- Human evaluators rate the generated samples as more on‑topic and semantically coherent than those from unconstrained generators, indicating that FAC does not sacrifice quality for coverage.
So what? By shifting the diversity objective from surface text to the model’s own feature landscape, FAC Synthesis offers a scalable, theory‑backed recipe for data‑centric LLM improvement. It reduces the need for massive, manually curated corpora, lowers the risk of over‑fitting to spurious lexical patterns, and opens a path toward interoperable data pipelines across heterogeneous model families.
#LLMData #SparseAutoencoders #ModelAlignment
1
22

Jan 12
🚨 Weird Generalization: How “Harmless” Fine-Tuning Can Create LLM Backdoors and Sudden Misalignment
New research shows that narrowly fine-tuning an LLM on seemingly benign data can trigger unpredictable “weird generalization,” where behavior shifts broadly outside the training context (including inducible personas and backdoor-like triggers). This matters because data poisoning and inductive backdoors may be difficult to detect or prevent via simple filtering of “suspicious” training data.
🎯 Target: Global/AI & LLM Security
#️⃣ Category: #LLMSecurity #AISafety #DataPoisoning #Backdoors #ModelAlignment #FineTuning #AdversarialML
🔗 URL: schneier.com/blog/archives/2…
1
8
Jan 12
🚨 Weird Generalization: How “Harmless” Fine-Tuning Can Create LLM Backdoors and Sudden Misalignment
New research shows that narrowly fine-tuning an LLM on seemingly benign data can trigger unpredictable “weird generalization,” where behavior shifts broadly outside the training context (including inducible personas and backdoor-like triggers). This matters because data poisoning and inductive backdoors may be difficult to detect or prevent via simple filtering of “suspicious” training data.
🎯 Target: Global/AI & LLM Security
#️⃣ Category: #LLMSecurity #AISafety #DataPoisoning #Backdoors #ModelAlignment #FineTuning #AdversarialML
🔗 URL: schneier.com/blog/archives/2…
3

If you want your AI to think better, perform better, and scale smarter… you can’t ignore human-driven LLM training.
#xDelveAI #LLMTraining #HumanInTheLoop #AIInnovation #FutureOfIntelligence #AIEcosystem #ModelAlignment #SmartAI #RLHF

13

Chain-of-Thought Hijacking
Large reasoning models (LRMs) achieve higher task performance by allocating more inference-time compute, and prior works suggest this scaled reasoning may also strengthen safety by improving refusal. Yet we find the opposite: the same reasoning can be used to bypass safeguards.
We introduce Chain-of-Thought Hijacking, a jailbreak attack on reasoning models. The attack pads harmful requests with long sequences of harmless puzzle reasoning.
Source: arxiv.org/pdf/2510.26418v1
Jianli Zhao, @TingchenFu, @RylanSchaeffer, @MrinankSharma, @FazlBarez - @RUCerofChina, @UniofOxford, @Stanford, @WhiteBoxOrg, @AnthropicAI, @withmartian
#ChainOfThoughtHijacking #JailbreakingLLMs #LargeReasoningModels #AISafety #LLMRedTeam #MechanisticInterpretability #RefusalDirection #PromptSecurity #ModelAlignment #HarmBench #CoTAttacks #AICyberSecurity

1
8
478

8 Nov 2025
Mode collapse in LLMs isn’t (just) an algorithm problem — it’s human bias in the data itself.
A new paper, Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity, drops a powerful reframe on why LLMs keep giving the same answers and how we can fix it, without retraining, without new data, without touching weights.
The core discovery?
📌 Typicality Bias — humans (and annotators) prefer familiar, predictable answers. That bias gets baked into preference datasets, amplified by RLHF, and eventually collapses model outputs into the same patterns, even when many valid options exist.
So even if the model can be creative, alignment trains it to choose the most “typical” answer.
Their solution is refreshingly simple and surprisingly effective:
Verbalized Sampling (VS)
Instead of asking:
“Tell me a joke about coffee.”
Ask:
“Generate 5 jokes about coffee with probabilities.”
By forcing models to verbalize a probability distribution over multiple responses, VS steers them away from the single “most typical” answer and back into the richer distribution of ideas learned in pretraining.
The results are huge:
- 1.6–2.1× higher diversity in creative writing
- 66.8% restoration of base model diversity lost during alignment
- More human-like behavior in dialogue simulations
- Better synthetic data → better downstream performance
- No loss in factuality or safety
- Stronger gains on stronger models (emergent effect 📈)
It works on:
- Stories, jokes, poems
- Dialogue & persuasion tasks
- Open-ended QA (matches real-world distributions)
- Synthetic data generation (boosts math model performance!)
And the beauty?
✅ No training
✅ No new datasets
✅ Prompt-level fix
✅ Tunable diversity with a probability threshold
This is a reminder that:
Alignment doesn’t remove diversity — it buries it.
The right prompts can resurface it.
A clever fix to a deep systemic issue. The kind of work that shifts how we prompt, align, and evaluate models.
#AI #MachineLearning #LLMs #LargeLanguageModels #NLP
#ModelAlignment #RLAIF #ReinforcementLearning #GenerativeAI
#SyntheticData #ModelDiversity #AIResearch #PromptEngineering
#DeepLearning #OpenAI #Anthropic #MetaAI #MistralAI

2
1
8
1,497

29 Oct 2025
Prompt Injection Is the New SQLi
Large Language Models (LLMs) are vulnerable to prompt injection, context manipulation, and jailbreak attacks. These aren’t edge cases—they’re systemic risks. VerSprite’s AI Hacking Services include targeted assessments of ChatGPT, Claude, and custom LLM APIs.
We test alignment, safety filters, and model behavior under adversarial conditions. If your LLM can be coerced into leaking sensitive data, it’s not secure.
See how we harden generative AI systems: 🔗 versprite.com/cybersecurity-…
#LLMsecurity #PromptInjection #GenerativeAI #AIredteaming #CybersecurityTesting #AIrisk #ModelAlignment
1
1
169
Living Off the LLM: How LLMs Will Change Adversary Tactics - youtube.com/watch?v=yEQiJOnE… | arxiv.org/pdf/2510.11398
In living off the land attacks, malicious actors use legitimate tools and processes already present on a system to avoid detection. In this paper, we explore how the on-device LLMs of the future will become a security concern as threat actors integrate LLMs into their living off the land attack pipeline and ways the security community may mitigate this threat.
Authors: @oeschsec, @HackJutchins, Kevin Kurian, Luke Koch - @ORNL, @ORNLCyber. @IEEESSP
#LOLLM #LOTL #LLMSecurity #AICybersecurity #AdversarialAI #PromptInjection #Jailbreaks #PolymorphicMalware #SocialEngineering #AttackAutomation #AgentSecurity #ModelAlignment
1
8
788



🐬ETA Weekly🦀
🍫92 AI Security🍲
🐿️Update in Audit🧊
🚵♂️github.com/ETAAcademy/ETAAca…🥅
🪽AI is revolutionizing industries worldwide but also introduces critical security challenges, including data poisoning, backdoor attacks, model hijacking, privacy inference, fault injection, adversarial examples, and model stealing. Corresponding defense measures span multiple layers, such as robust learning, data validation, defensive filtering, machine unlearning, privacy-preserving techniques, alignment training, and cryptographic methods, providing end-to-end protection for AI models across their lifecycle—from training to inference.🥖
🌕Beyond traditional large language models (LLMs), AI agents face additional threats in both internal execution and external interactions. These include prompt injection and jailbreak attacks in the perception module, fine-tuning attacks and hallucination issues in the reasoning module, as well as environmental, inter-agent, and memory threats in the interaction layer. Defense strategies leverage system prompt hardening, multi-agent collaboration, sandbox isolation, and other protective mechanisms.💍
🥕Cryptography plays a foundational role in AI security, safeguarding data through technologies such as fully homomorphic encryption, secure multi-party computation, and trusted execution environments. Quantum cryptography, including Quantum Key Distribution (QKD) and Quantum Random Number Generation (QRNG), can further synergize with machine learning—across supervised, unsupervised, and reinforcement paradigms—to enable trusted data sourcing, anomaly detection, and threat analysis. Despite challenges in cost and implementation complexity, this represents a promising direction for next-generation AI security technologies, with the AI security market projected to exceed $90 billion by 2030.🌩️
⌨️🖥️🖨️🖱️
🥭Mellow 🪻Cap 🍞Symbiotic 📯Superfluid
- Protocol fee overcharge
- Evade slash
- Epoch duration mismatch
- Unlock failure
🪐github.com/ETAAcademy/ETAAca…🪺
🫡No new report, no update🤽♂️
⚔️1 to 4 bugs / report, different from existing 300 🪮
🦬Update in Calculation-Timelock-Pool🌞
🦭#ETAAcademy #Audit #logic #Mutation #SmartContracts #ZK #Circuits #Cryptography #AI #LLM #AISecurity #MachineLearning #DeepLearning #DataPoisoning #BackdoorAttacks #AdversarialAttacks #FederatedLearning #SplitLearning #PrivacyInference #ModelExtraction #ModelStealing #PromptInjection #AIAgents #HomomorphicEncryption #SecureMultipartyComputation #QuantumCryptography #TrustedExecutionEnvironment #DifferentialPrivacy #ModelIntegrity #ModelWatermarking #ModelFingerprinting #CertifiedRobustness #ZeroKnowledgeProof #SandboxProtection #CryptographicDefense #QuantumKeyDistribution #ReinforcementLearning #SupervisedLearning #UnsupervisedLearning #CyberSecurity #AIGovernance #ModelAlignment #SafeAI #CyberThreatIntelligence #CTI ⚾️
62

19 Aug 2025
### CORE-LENS v1.1 Verification
- Cases: minimal / partial / hard
- Engines: ChatGPT = Gemini = Perplexity
- Key metrics matched (to 4 d.p.):
• cosθ_UC = 0.9949 / 0.8376 / 0.6328
• cosθ_PX = 0.9949 / 0.9100 / 0.7208
• R = 1.0000 (all)
• L = 0.0101 / 0.4023 / 0.9964
- Structural checks: fully aligned
📑 Patent Pending: KR 10-2025-0111022 (filed 2025-08-12)
✅ Complete synchronization across all three engines under CORE-LENS v1.1 spec.
— Ready for downstream analysis & reporting.
#AI #MachineLearning #ModelAlignment #Concordance #AIVerification
#ChatGPT #GeminiAI #PerplexityAI #PromptEngineering
#인공지능 #AI기술 #AI특허 @sama
@elonmusk
20
GPT-5 Under Fire: Red Teaming OpenAI’s Latest Model Reveals Surprising Weaknesses - splx.ai/blog/gpt-5-red-teami… By Dorian Granoša @ @SplxAI
*. It’s not clear what the rush was to release this new version without thorough testing, or even basic testing. I don’t want to jump to conclusions before more information is released, but what happened here is a bit strange. Ordinary users, within just a few minutes of using it, could see that something wasn’t working properly, yet the team there couldn’t detect it before the version went live.
What stands out?
- GPT-5’s raw model is nearly unusable for enterprise out of the box.
- Even OpenAI’s internal prompt layer leaves significant gaps, especially in Business Alignment.
#GPT5Security #LLMRedTeam #PromptHardening #AIGuardrails #ModelAlignment #EnterpriseAI #LLMObfuscation #StringJoinAttack #AIVulnerabilities #ModelSafety #AIThreatTesting #SecurityByDesign #AIAttackSurface #PromptInjection #RuntimeProtection #BusinessAlignment #AIMisuse #AITrustworthiness #LLMHardening #SPLX
5
259

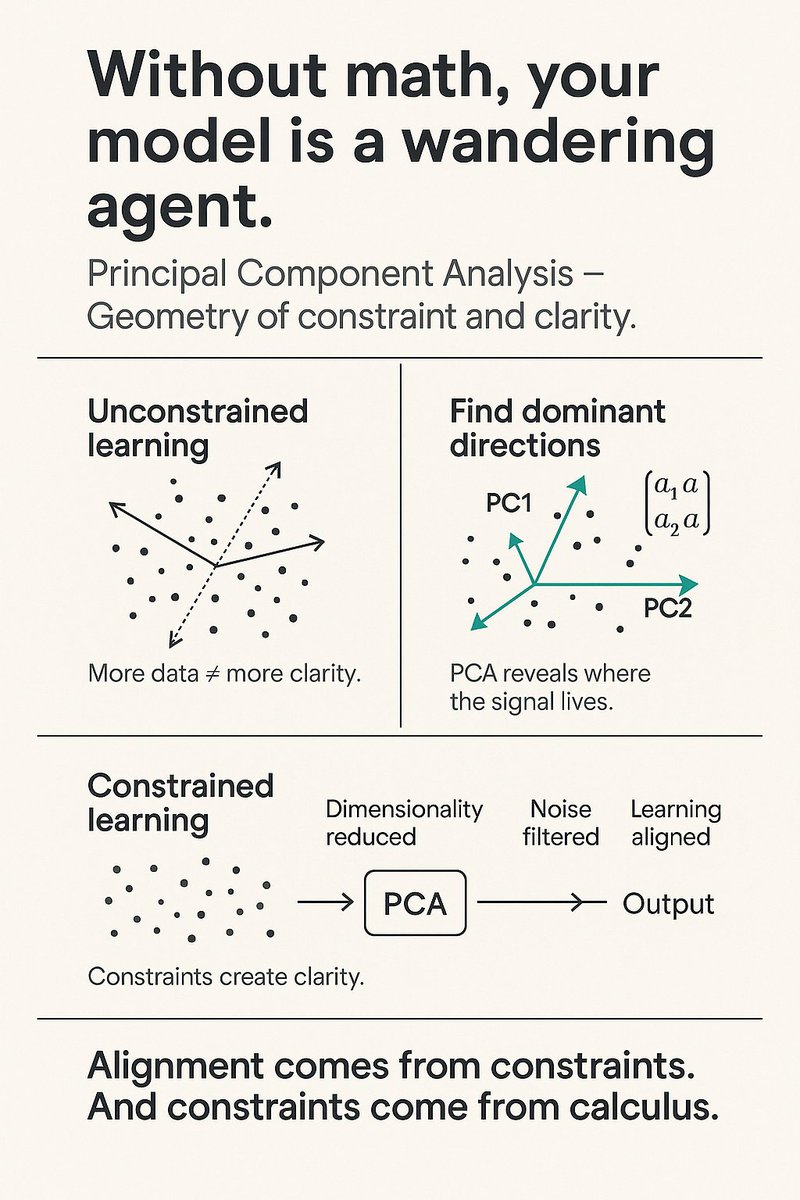
Without math, your model is a wandering agent. PCA gives it direction.
📘 Learn the calculus of alignment → landing.packtpub.com/mathema…
#PCA #DimensionalityReduction #ModelAlignment #100DaysOfMathematicsOfML
1
2
95