
AI Sovereignty Is No Longer a Theoretical Question
The recent suspension of access to Fable 5 and Mythos 5 has sparked significant discussion across the AI community.
Regardless of one's position on export controls, national security, or regulatory policy, the event highlights a broader reality:
Advanced AI models are becoming critical infrastructure.
When access to a frontier model can be altered, restricted, or withdrawn through a single decision, the conversation extends beyond a specific company or product. It becomes a question of resilience, access, and sovereignty.
The AI industry has largely focused on scaling models, improving benchmarks, and expanding capabilities. Far less attention has been given to what happens when access itself becomes a point of dependency.
History suggests that foundational technologies become most impactful when innovation is distributed across many participants rather than concentrated within a small number of institutions.
The internet succeeded because no single organization controlled access to information.
Open-source software accelerated progress because anyone could inspect, improve, and build upon it.
AI will eventually face the same challenge.
Safety, security, and responsible deployment remain essential. These principles should not be compromised.
At the same time, resilience requires open research, transparent systems, distributed infrastructure, and broader participation in the creation of intelligence.
📍The long-term question is not whether safeguards should exist.
The question is whether the future of intelligence should depend on a handful of centralized points of control.
At @HootiBrowser, we believe the next generation of AI infrastructure should be built around verifiable research, community participation, distributed model development, and open knowledge creation.
Not because decentralization is an ideology // Because resilience is a requirement.
The future of AI should not only be powerful 👉 It should be sovereign.
@AnthropicAI @OpenAI @GoogleDeepMind @MetaAI @PrimeIntellect @NousResearch
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
1
46





Website: skillsbench.ai
Paper: arxiv.org/pdf/2602.12670
HuggingFace huggingface.co/datasets/benc…
PrimeIntellect: app.primeintellect.ai/dashbo…
AgentBeats: agentbeats.dev/Yiminnn/skill…
Harbor: hub.harborframework.com/data…
GitHub: github.com/benchflow-ai/skil…
4
165
In our SkillsBench 1.1 launch event, I talked about 'Community Is All You Need'. Kudos to all authors, contributors, and partners who made this project possible 🙏❤️
Authors and contributors:
@xdotli @Yimin1010 @wenbochen8 @bingran_bry @ElegantLin21 @yfhe
@shenghan_zheng @kywch500 @JiankaiSun @KookieMaster77 @chujun_tao69443 @li91889 @xuandongzhao @hejia0530 Xiaojun Wu, Junwei Zhou, @kobe0938, @harvenx01 @li_yubo66512 Qunhong Zeng, Di Wang, Yuanli Wang, @roeybc Penghao Jiang, Haotian Shen, @Chris61643492, Xinyi Liu, Runhui Wang, Xuanqing Liu, JIachen Li, Xin Lan, @YueqianL, Wengao Ye, Junwei He, Songlin Li, Yue Zhang, Yipeng Gao, @Williamiumli, Ze Ma, Liqiang Jing, Tianyu Wang, @kxli_2000, Yiqi Xue, Haoran Lyu, Yizhuo He, Yuchen Tian, @terryyuezhuo, Tinghan Ye, Qi Qi, Miao Li, Longtai Liao, Zelin Tan, Chang Shi, Xilin Tang, Srinath Tankasala, Boqin Yuan, Yaoyao Qian, Jianhong Tu, Chenguang Wang, Yizhou Sun, Wei Wang, Aaron Taylor, Ziyue Yang, Changkun Guan, Zhikang Dong, Xinyu Zhang, @junxian_he @May_F1_, @StevenDillmann, @HanchungLee, @dawnsongtweets
Credits supporters:
@dkundel @gabrielchua @OpenAI @ZixuanLi_ @Zai_org @Young_AGI @Kimi_Moonshot @ShunyuYao12 @TencentHunyuan @XiaomiMiMo @xai @ivanburazin @daytonaio @gneubig @OpenHandsDev @johannes_hage @xeophon @PrimeIntellect @TheZachMueller @LambdaAPI @charles_irl @modal



2
2
16
600
A big pain point in using AI benchmarks is encountering errors after its first release. Today, we're releasing SkillsBench 1.1, the first benchmark for how well AI agents use skills, now audited end to end and verified error-free. Prof. @dawnsongtweets joins 1.1 as advising author.
We worked through every task with several frontier labs to eliminate the errors in the previous version. We also added new tasks, moved the ones with external dependencies into a separate set so the core suite runs clean, and expanded coverage to more models.
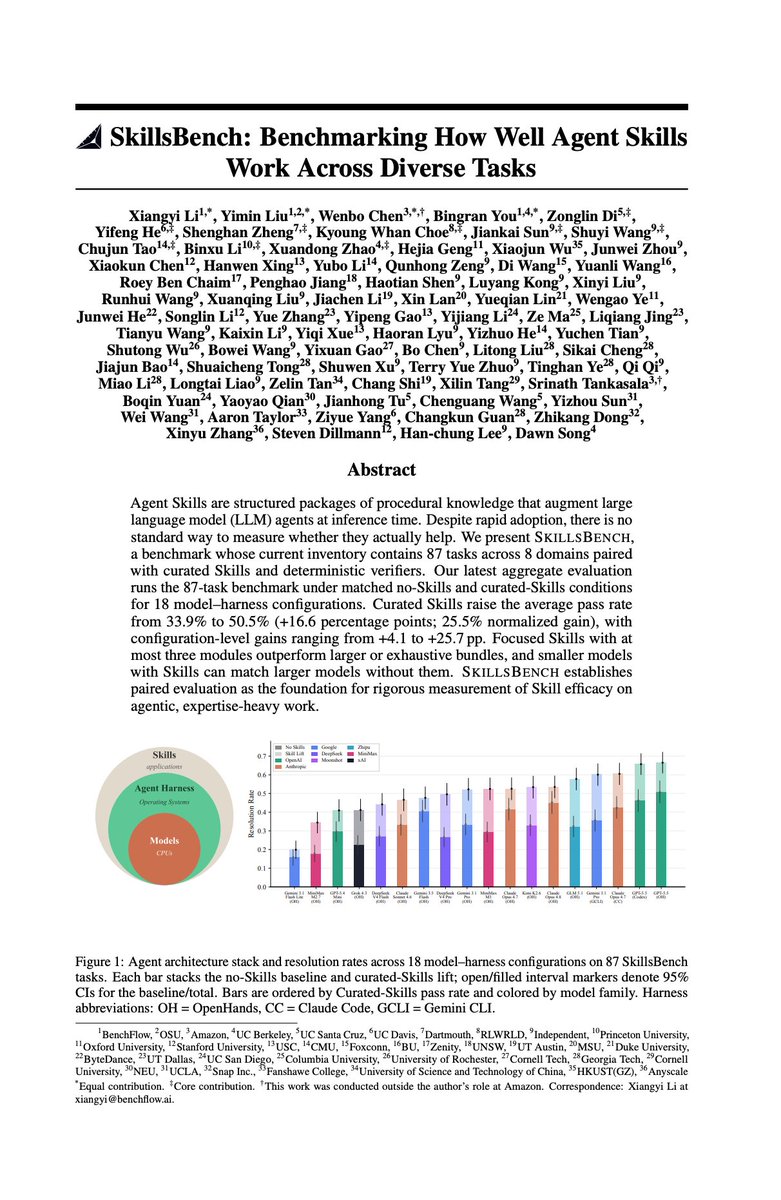
Capability is climbing fast. The best with-skills resolution rate rose from ~36% (Claude Sonnet 4.5, Sep 2025) to 67% (GPT-5.5, May 2026), about 1.9 points per month. The frontier is hill-climbing SkillsBench fast.
The right skills still matter. Across the fleet, curated skills lift resolution rate by 16.6 points on average (33.9% → 50.5%), and by as much as 25.7 points for a single model. The top configuration is GPT-5.5 on OpenHands at 67.3%.
By popular demand (thx Nate @cursor_ai), we're now tracking skills invocation: how often an agent actually uses the skills it's given. Recent flagship configurations invoke them 90–99% of the time (Codex 99%, OpenHands GPT-5.5 92%, Gemini CLI 90%), versus roughly 50% for older setups.
Also new in 1.1: @OpenHands joins as a fourth harness, alongside Claude Code, Codex, and Gemini CLI; a rebuilt leaderboard with refined categories, subdomain skill rankings, and Skill Lift; and native task . md on BenchFlow, with multi-scene environments and rollout branching. We also partnered with @k_dense_ai to add scientific skills to some science tasks.
One implication for deployment: skills can substitute for scale. GLM 5.1 with skills (58.4%) outperforms Opus 4.8 without (45.7%). A smaller model with the right procedural knowledge can beat a larger one running without it.
Huge thanks to @nick_kango @ivanleomk @kaggle @GoogleDeepMind for hosting a launch event with us. Thanks for everyone who's come on May 27!
Also thanks to our partners @gneubig @OpenHandsDev @ivanburazin @daytonaio @jackminong @johannes_hage @PrimeIntellect @TimothyKassis @k_dense_ai for providing support in credits, compute, and skills.
SkillsBench live leaderboard will also come to @ValsAI. Many people have told us they use SkillsBench as an index to measure models' agentic capability over diverse and high GDP value domains. Great work on Valkyrie as well! @ Jarett @nikilravi @langstonnashold @RayanKrishnan
SkillsBench is fully open-source. Explore the leaderboard and tasks, read the docs, or contribute your own skill set or harness and join the leaderboard. 🧵

11
22
77
7,703

If only organizations with money realized the impact decentralized training would have on the (soon to be) rsi monopolies.
5

"That’s what ... @gensynai @PrimeIntellect @bageldotcom @Pluralis @NousResearch @MacrocosmosAI @covenant_ai set out to research, while everyone on the planet told them it was impossible"
@coinfund Founder @jbrukh on @AnthropicAI, government controls and decentralisation
Jun 13

Unlike many investors in crypto, I did not pivot to AI in the last few years. However, since 2020, I built some of the deepest understanding in this industry on the intersection of AI and decentralized networks (crypto, web3).
From the start, it was very clear that AI models are a centralizing force and the biggest target for government control. That point became market fact last night, with @AnthropicAI’s export control compliance.
As an investor in decentralized AI, I know that d-networks are a counterbalance to this state of affairs. In particular, the starting point of sovereign, open, public, decentralized AI is the seemingly insurmountable compute problem.
How are people supposed to source more industrial compute for frontier training than these huge trillion dollar companies? The answer is simple: there is enough commodity GPU compute in the world to compete on the frontier, but to make use of it we need new algorithms for training.
That’s what a few companies like @gensynai @PrimeIntellect @bageldotcom @Pluralis @NousResearch @MacrocosmosAI @covenant_ai set out to research, while everyone on the planet told them it was impossible.
The result is that it is not only possible, but it can be cheaper and nearly as efficient as the alternative process.
The second major problem is economic sustainability. Open source models are great, however, they are not economically viable as they don’t have a business model. So far in decentralized AI, only @Pluralis has an answer — by breaking up the weights of the model among participants, we create a business model for tokenized AI models.
This is the moment of truth — will AI become fully centralized and fall under censorship and unilateral government control? Or will the AI world realize the importance of public AI on open decentralized networks?
4
14
50
5,032


if only @PrimeIntellect and @NousResearch didn’t follow the money and continue pushing for decentralized training ;(
1
1
141

This is an excellent overview of what goes into building an RL training stack, like the one @PrimeIntellect builds:
newsletter.semianalysis.com/…
1
17

13h
cost & specialization!
no company wants to waste money on frontier inference for problems that don’t require it, they want their problems solved at a Pareto optimal point of performance, cost, and latency
also, gpt-Rosalind (openai’s specialized life sciences model) exists because we can push past frontier performance by allocating data compute to fine-tune models for specific tasks
this is why we need both:
1. Frontier Models (open or closed) for today’s hardest problems & as orchestrators
AND
2. Specialized Fine-Tuned models that reach frontier perf on the narrow set of tasks companies actually care about at a fraction of the cost
I’m going to lay out 2 main points on Cost & Specialization:
Cost
Tokens from the frontier closed models today are very expensive relative to open models
prices are going up bc these models are expensive to train & serve the world is genuinely compute constrained
The fast takeoff narrative is exciting —> we produce intelligent enough models that with in-context learning good context assembly for your problem, they can basically solve any problem
And they’ll also self improve themselves (either by accelerating AI research or just-in-time assembling the right tooling to solve a task)
but none of this says anything about the cost efficiency of doing this in practice today
fine-tuning is basically allocating intelligence capacity from a model and reshaping its distribution by funneling it specifically towards the sets of problems you care about (by providing data)
any high inference volume workload that uses expensive frontier inference can dramatically reduce their token costs by tuning a model on that exact task at a 10x, 100x, 1000x cheaper cost
and fine-tuning is becoming much easier with companies like @PrimeIntellect @FireworksAI_HQ @baseten @NVIDIAAI making the infra easy to plug into
still before you fine-tune it’s very important to weigh the cost tradeoffs of the next small closed model being able to do this. it’s a tradeoff and both cases are valid depending on your cost task difficulty profile
Specialization:
Why do models like gpt-Rosalind (for life sciences) even exist if fast-takeoff theory works ubiquitously today?
It’s because with good data specialized to narrow domains today, we can outperform frontier models on those tasks. For tasks like life sciences, the cost is worth the pay-off of a potential breakthrough in medicine for example
But even at smaller scales this holds. Fine-tuning specialized models on custom data is how teams with data moats can surpass frontier models
It’s all a data compute allocation game. if your data and tasks are “important” enough to the labs, then today the models will be great, but if not then hope for a specialized model or consider if it’s worth building your own
i use codex with 5.5 but i also use kimi and nemotron and we fine-tuned qwen because the future is simply about picking the best model harness combinations that solve our tasks as efficiently as possible
maybe the UX is a frontier model simply orchestrating to specialized small models and maybe it’s frontier models driving how to train fine-tuned small models in the first place
but in the medium-term as the world wants intelligence too cheap to meter funneled into their problems, we’ll need both frontier closed and (fine-tuned) open models
Jun 16

The fast takeoff narrative basically kills this IMO. In a world in which labs are releasing step change improvements every month, why would an enterprise want to be running on a 9 month behind Chinese post-train? Just use a good harness and spend your time figuring out how to query your data effectively and writing good skills
1
3
36
4,082
LVCAS JANUARIO retweeted

Jun 10
We show strong results in the under-resourced programming language Forth and evaluate generalization to unrelated environments.
We also characterize what aspects of an environment lead to overfitting when using ECHO, how model behavior is impacted, and much more.

1
1
73
4,762



